Автоматизация извлечения mp3 из исходного кода сайта
Существуют ли программы, способные извлекать (скачивать) mp3, выложенные на сайтах в виде flash плееров (и не только). К примеру, есть страница с проигрывателем (www.thewire.co.uk/audio/tracks/office-ambience_346). Требуется извлечь все mp3, представленные в плеере, не руками, копируя каждый mp3 из исходного кода, а как-нибудь это дело автоматизировать, если возможно.
- Вопрос задан более трёх лет назад
- 7685 просмотров
Комментировать
Решения вопроса 0
Ответы на вопрос 3

Можно просто при помощи wget стянуть всё (указать флаг -p или —page-requisites)
Ответ написан более трёх лет назад
Комментировать
Нравится 1 Комментировать
Под такую задачу проще накидать примитивный скрипт — забираем html, через регулярные выражения находим ссылки и скачиваем файлы. Делов минут на 10 🙂
Ответ написан более трёх лет назад
Комментировать
Нравится Комментировать

Веб-разработчик с 2002 года
Как скачать контент с сайта, не засоряя браузер плагинами.
Порой возникает ситуация, когда нужно скачать музыку/видео/картинку с сайта, а заветной кнопки «Скачать» на странице нет.
Для популярных сайтов, вроде ВК и ютуба, эта проблема остро не стоит, для них имеется куча разных программ, плагинов или сайтов, дающих вам возможность скачать нужный контент. Но как быть с не столь популярными сайтами, для которых найти плагины почти нереально??
Способ есть! И что самое главное, ничего скачивать и устанавливать не надо, все делается стандартными средствами браузера.
Я не мастер словоблудия, поэтому учиться будем на примерах.
(формат поста: сначала описание картинки, потом — сама картинка)
1. Заходим на страницу с видео, кликаем правой кнопкой мыши, в появившемся меню выбираем пункт «Просмотреть код элемента».
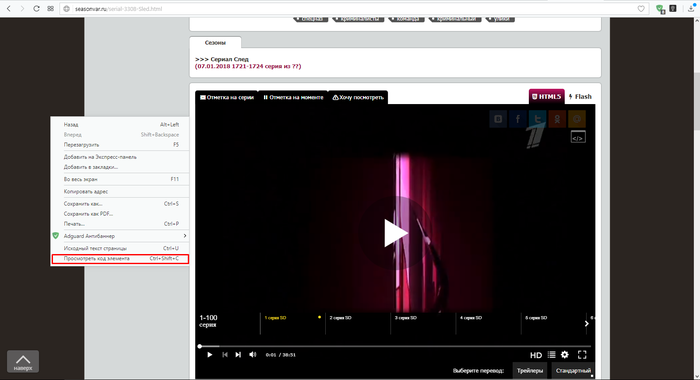
2. В появившемся окне выбираем вкладку «Network».
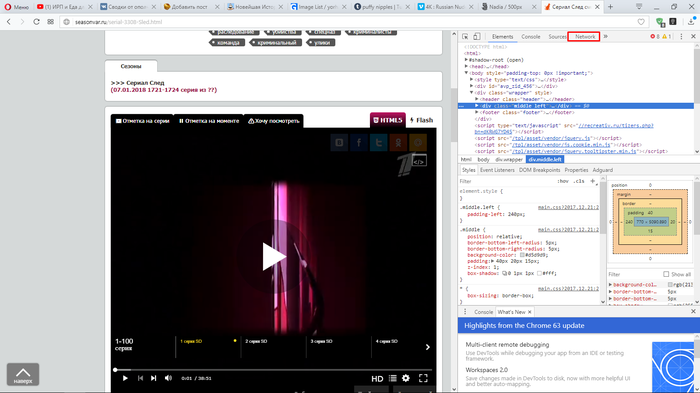
3. Затем выбираем вкладку «Media».
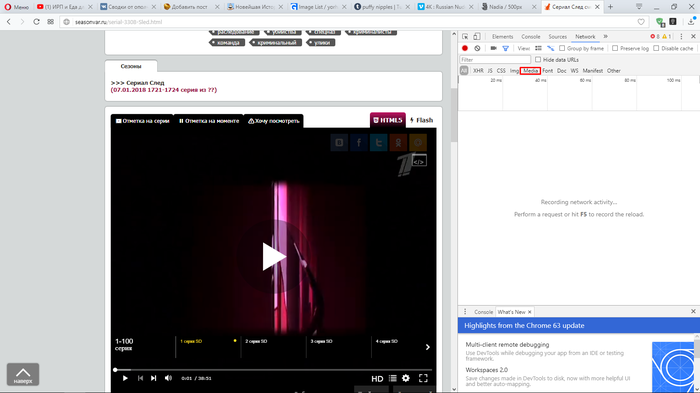
4. Перезагружаем страницу и запускаем видео.
5. Выбираем в таблице нужный нам файл (у меня он один, но бывает и несколько, тогда следует немного подождать, и выбрать файл с наибольшим объемом (объем файла указан в пункте «Size»)) и делаем двойной клик по нему.
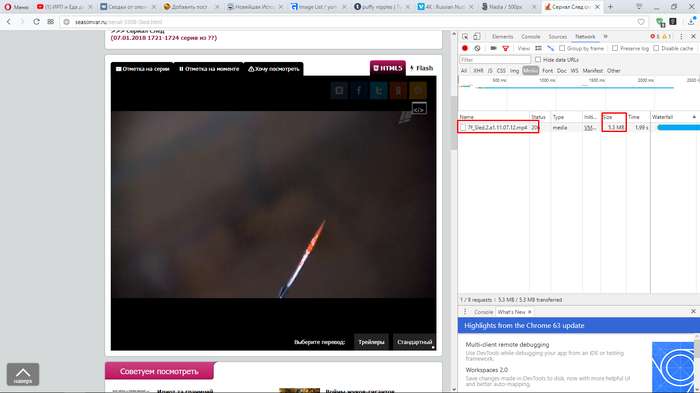
6. Откроется новая вкладка с плеером, нажимаем кнопку «Скачать» и наслаждаемся видом загрузки))
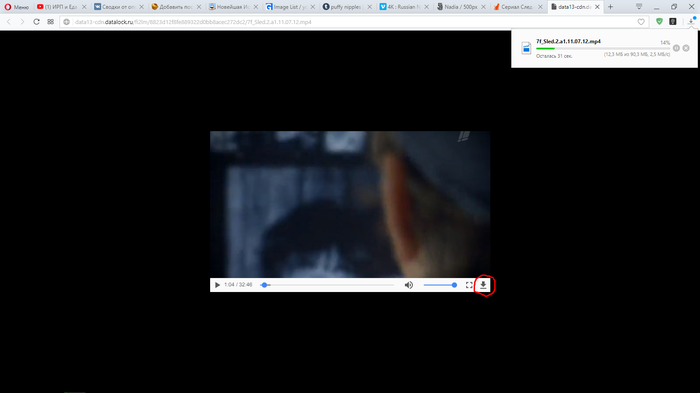
Пример 2. Музыка.
1. Повторяем пункты 1 — 4 из первого примера.
2. Запускаем воспроизведение нужного трека, и делаем двойной клик на файле с наибольшим объемом, затем повторяем пункт 6 из первого примера.
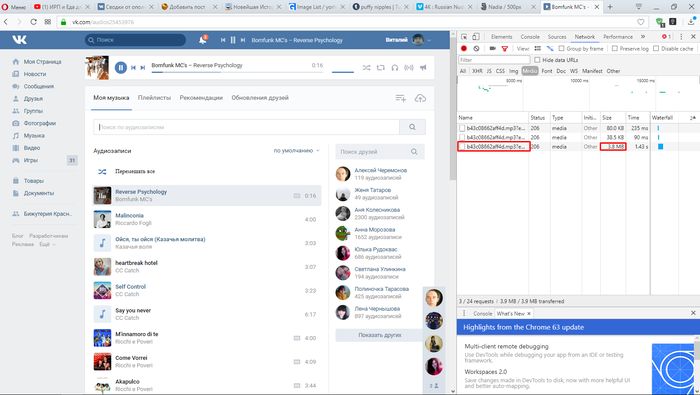
Пример 3. Картинка.
Чтобы не было глупых вопросов, поясню: не на всех сайтах можно сохранить картинку через контекстное меню, на некоторых оно либо урезано, либо заблокировано совсем.
1. Повторяем пункты 1 — 2 из первого примера.
2. Выбираем вкладку «Img».
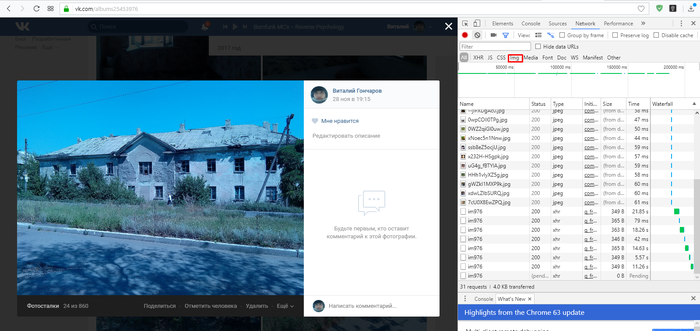
3. Перезагружаем страницу.
4. Ищем нужную картинку в списке (он может быть большим), используя предпросмотр (один клик по файлу) и найдя, делаем двойной клик по ней.
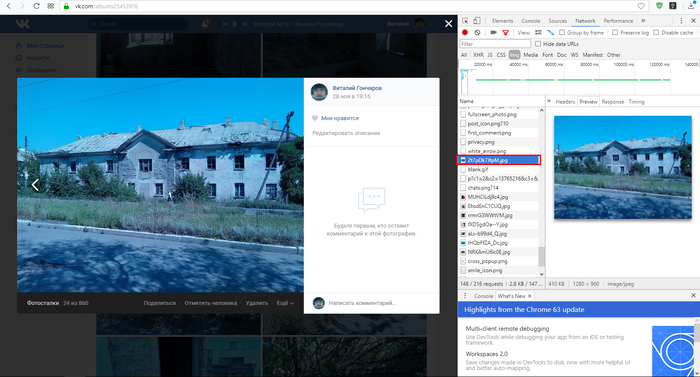
5. В открывшейся вкладке кликаем правой клавишей мыши по картинке, и выбираем в контекстном меню пункт «Сохранить изображение как. «.
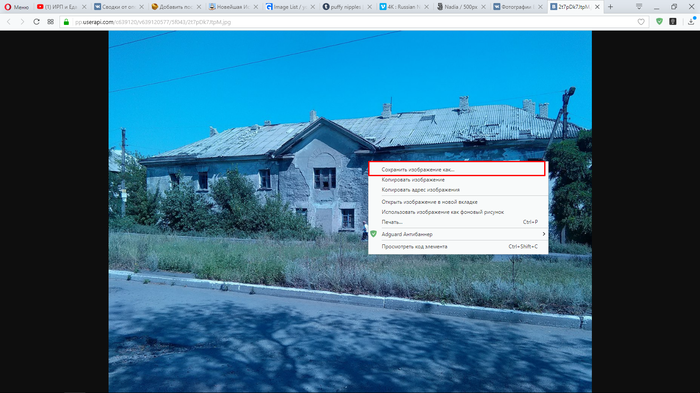
6. Сохраняем картинку.
P. S.: Все действия проводились на Опере v.50, за работоспособность этого способа на других браузерах я не ручаюсь.
6 лет назад
Ну удачи вам с потоковым контентом
раскрыть ветку
6 лет назад
уважаемый мамкин хакирь, специально от таких как вы видосы режут на кусочки и с ютуба ты так не скачаешь
пс: шучу, не специально а для оптимизации
раскрыть ветку
6 лет назад
Для Хрома — Flash Video Downloader
Для Мозилы — FlashGot
раскрыть ветку
6 лет назад
С потоковым видео такое не прокатит, плюс есть всякие защищенные плееры на подобии netu.tv, которые в плеер вставляют кучу всякого мусора, который затрудняет поиск потока.
Так, что НЕ с любого сайта.
6 лет назад
чет с ютобом у меня не прокатило
раскрыть ветку
Похожие посты
2 месяца назад

Лежачий человек тоже человек.
я давно хотел написать этот пост, но всё думал, как его сформулировать Чтоб любой мог понять мои слова.
если вы читаете это то, поймите всё что я напишу это не смешно, это тяжело, больно и неприятно.
я просто хочу помочь людям у которых в семье есть лежачий человек страдающий инвалидностью.
я сам полу лежачий, то есть я могу только седеть и лежать.
всем мы справляем нужду и мало кто задумывался о том как люди которые не могут ходить в туалет по-большому.
дело в том что большинство людей используют для этого Утку, да это привычный способ для многих, но бывает так что больному человеку не комфортно, на пластмассовой утке.
2020-году мне сделали операции на бедро (тазобедренный сустав разрушался) и после жизнь дала мне новые испытания, раньше я вставал на ноги и тем самым помогал себя поднимать и пересаживать с места на место
и так, после того как мы с родными поняли что я не способен, вставать и садиться на санитарный стул и лежать на утке это тяжело и больно.
мы придумали лайфхак это Пелёнки которые выдают в соц обеспечения для инвалидов, иногда вам придётся самим их покупать.
принцип тот же, что и с уткой разница лишь в уборке фекалии, вам просто нужно аккуратно свернуть содержимое в пелёнку.
техника сворачивания похожа на то, как сворачивают фарш, когда готовят голубцы
вы наверно скажешь типа Зачем руки морать когда есть утка, да точно тут вы правы, но не везде просто не все люди могут лежать на пластике им больно.
просто попробуйте лечь спиной на кубик-рубик что вы почувствуйте?
самое главное помните что лежачий человек тоже человек.
Показать полностью
Поддержать
4 месяца назад

А так можно было что ли?
Поддержать
7 месяцев назад
Девушка демонстрирует способы освободить связанные изолентой или зажимом руки
Мало ли пригодится в жизни.
Взято из сети.
Поддержать
1 год назад
Ещё один вариант
Поддержать
1 год назад
Как купить билет на поезд, если билетов нет совсем. 3 проверенных способа
Бывают случаи, когда вам нужно ехать в другой город: по работе, на свадьбу, юбилей и т.д. Забегались, забыли, билеты не купили. Что делать, если билетов нет от слова Совсем. Да, на вашу дату осталось, пару билетов СВ по цене, как ваша месячная зарплата. Что делать? Вы не можете не ехать.
Сохраните в закладки, чтобы не потерять.
Отказные билеты.
Заходить на сайт РЖД каждые 10 минут. Во-первых есть много нюансов, когда снимается дополнительная бронь и появляются билеты, за 3 суток, за сутки, за 3 часа и т.д. Плюс кто-то может сдать билет.
Некоторые направления настолько популярны, например Минск-Москва, что уже в ноябре люди начинают покупать билеты на Новый год, причем в обе стороны. Тем более 10 дней праздничных дней в России сделают свое дело. Попробуйте найти билеты на 30 декабря, скорее всего их почти не осталось.
Второй способ- можно поделить ваш путь на части. Самый работающий метод.
Сейчас расскажу подробнее. Например, вы едете Москва-Минск. Билетов нет, совсем никаких. Вы смотрите маршрут поезда, который вам нужен. Какие крупные города проезжает поезд.
В нашем случае Вязьму, Смоленск. Начинаете смотреть билеты частями: Москва-Вязьма, Вязьма-Смоленск, Смоленск-Минск и т.д. Да это не очень удобно, старайтесь , чтобы места были в одном вагоне. То есть до Вязьмы вы едете на месте 21, дальше 45. Впринципе ничего страшного) Только у проводников иногда вызывает удивление.
Почему частями должны быть свободные места? Потому что человек, например, купил билет Москва-Вязьма, это всего 3 часа от Москвы, дальше это место до самого Минска будет свободно, а вы в итоге не можете уехать.
Допустим вы нашли билет Вязьма-Минск, теперь ваша задача добраться из Москвы до Вязьмы. Ищите билет в этом же вагоне или хотя бы поезде. Если вообще ничего нет, смотрите билет на другой поезд. Да, это не удобно! Пересаживаться, иногда ночью, на другой поезд! Но речь о ситуациях, когда вам надо быть завтра на свадьбе свидетельницей, и вы не можете сказать подруге:
-Извини, не было билетов, я не приеду!
К тому же до этого ближайшего города, например, Вязьмы, вы можете добраться на электричке, скоростной Ласточке за 2 часа, на автобусе, вас может довезти муж на машине.
Третий способ — смотреть билеты на начало следующего дня.
Допустим впереди 3-4 праздничных дня и вы упорно ищите билеты на пятницу вечер. Ничего нет. Всем надо ехать.
А теперь попробуйте посмотреть на субботу, после 0.00 часов. И там кстати довольно много поездов, на час ночи, на 3.00. Вот как раз на поезда глубокой ночью могут быть билеты, потому что не каждый сможет добраться. Плюс на утро скорее всего будут билеты, да, потом полдня ехать, может немного опоздаете на торжество. Но вы приедете!
Вывод- выход с покупкой билетов есть всегда! Да, способы не очень удобные, но не пешком же вам идти.
Забронировать билет на поезд онлайн:
Сервисы бронирования жилья:
Суточно (квартиры, комнаты, отели и апартаменты),
Скачивание аудио с сайта mail.ru

Задача, которая перед нами стоит — скачивание музыкальных произведений с сайта предоставляющего такую возможность. Использовать будем язык-программирования Python.
Для осуществления этого нам будут необходимы знания о парсинге сайта и работе с медиа файлами.
На рисунке выше изображен общий алгоритм парсинга сатов. Парсинг будем осуществлять с помощью модулей BeautifulSoup и request, а для работы с текстом нам будет достаточно модуля re.
Импорт
import requests #осуществляет работу с HTTP-запросами import urllib.request #библиотека HTTP from bs4 import BeautifulSoup #осуществляет синтаксический разбор документов HTML import re #осуществляет работу с регулярными выражениями Объявление переменных и основная процедура
Нам будет необходимо всего два массива и одна переменная для хранения информации:
page_count = [] #массив для хранения страниц сайта, содержащих музыку perehod = '' #сайт перенаправляет на новую страницу для скачивания, здесь мы будем хранить эту ссылку download = [] #массив для поочередного хранения готовых ссылок для скачивания и имени файла Пишем процедуру, где первым делом считаем все страницы на сайте, содержащие нужные нам песни.
if __name__ == '__main__': #условие для запуска процедуры u = str(input('Впишите группу для скачивания:\n')) #input - ввод данных с клавиатуры в программу. Эта переменная будет содержать название группы исполнителей, которую мы скачивем base_url = 'http://go.mail.ru/zaycev?sbmt=1486991736446&q='+u #переменная содержит http сайта, который мы парсим count=0 #объявляем переменную и приравниваем ее к нулю для дальнейшего создания счетчика page_count = [base_url] #в массив добавляем ссылку первой страницы, остальные будем помещать в цикле print('Поиск станиц. Подождите. ') #print - осуществляем вывод указанного текста while True: #запускаем цикл try: #try обработчик исключительных ситуаций. То есть, программа будет выполнять цикл и когда встретит ошибку, которую мы укажем в условии except, начнет выполнять условие в нем page_count = page_count+[get_page_count(get_html(page_count[count]),page_count)] #к массиву прибавляем переменную, получаемую в функции get_page_count, куда мы также передаем переменную page_count для дальнейшего заполнения. Внутри этой переменной выполняется функция get_html (для получения http) от page_count[count], где count изначально равен нулю. Проще говоря, программа будет брать первый элемент в массиве - первый раз, и на единицу больше - каждый последующий проход цикла count = count + 1 #счетчик, позволяющий нам перебирать элементы в массиве except TypeError: #когда закончатся страницы на сайте, возникнет ошибка TypeError. Воспользуемся ею break #оператор break прекращает выполнение цикла и переводит выполнение программы на строку следующую после цикла print("Всего страниц найдено - ",len(page_count)) #в желании вывести количество найденных страниц нам поможет оператор len, который считает количество элементов в массиве Получение HTTP-страниц
Для жизнедеятельности ранее написанного, необходимо написать две функции, первая — будет получать http и передавать этот параметр во вторую, которая в свою очередь будет получать данные с этой ссылки по средству парсинга.
def get_html(url): #объявление функции и передача в нее переменной url, которая является page_count[count] response = urllib.request.urlopen(url) #это надстройка над «низкоуровневой» библиотекой httplib, то есть, функция обрабатывает переменную для дальнейшего взаимодействия с самим железом return response.read() #возвращаем полученную переменную с заданным параметром read для корректного отображения Следующая функция будет представлять сам парсинг. Главное, что нам необходимо для получения информации о построении сайта — это просмотреть его html верстку. Для этого заходим на сайт, нажимаем Shift+Ctrl+C и получаем исходный код, где отображены все имена виджетов.
def get_page_count(html,page_count): #в функцию мы передаем две переменные page_count (о ней мы говорили ранее) и html эта переменная нам также встречалась, просто в более сложном виде: get_html(page_count[count]) soup = BeautifulSoup(html, "html.parser") #объявляем новую переменную с полным html-кодом страницы href = soup.find('a', text = 'Вперед') #теперь из страницы находим нужный нам виджет - это кнопка с текстом "Вперед". "а" - это блочный элемент, которому принадлежит данная кнопка. Убедиться в этом можно описанным выше способом(Shift+Ctrl+C). base_url = 'http://go.mail.ru' #как видим, это лишь часть урла сайта. Берем лишь часть для дальнейшего соединения с частью, содержащей порядковый номер страницы сайта page_count = base_url + href['href'] #теперь крепим недостающую часть. Так как нам нужен лишь адрес из переменной href, а не весь html-код, принадлежащий кнопке, то с помощью функции ['href'] мы получим ссылку следующей страницы (также можно получить и иные части html-кода). return page_count #возвращаем значение переменной в процедуру Важно! Все данные, получаемые с использованием BeautifulSoup, имеют не строковой тип данных, а отдельный «красивый суп» тип данных.
Очередная задача — получение нового адреса для скачивания при нажатии «Скачать» на каждой из страниц. Заметим, что не станем использовать массив, так как в этом случае нам придется заполнять его полностью и лишь затем начинать скачивание, что сильно замедлит работоспособность программы. Будем брать каждый раз новую ссылку и работать непосредственно с ней. Для этого пишем вторую функцию и добавляем в процедуру:
print('Скачивание') #выводим надпись 'Скачивание' пока идет скачивание музыки try: #запускаем обработчик исключительных ситуаций for i in page_count: #перебираем каждый элемент в массиве perehod = parsing1(get_html(i),perehod) #приравниваем переменную к функции, получающей url кнопки для скачивания. В эту функцию передаем две переменные - саму приравниваемую переменную и каждый раз меняющийся url except TypeError: #ошибка, которая нас потревожит TypeError (функция применяется к объекту несовместимого типа) print('Скачивание окончено') #выводим надпись 'Скачивание окончено' по окончанию будущего скачивания В третьей функции встретимся с использованием re.findall(Шаблон, строка)- осуществляет поиск по заданному шаблону в строковой переменной.
def parsing1(html,perehod): #объявляем функцию soup = BeautifulSoup(html, "html.parser") #получаем полный html-код страницы perehod = [] #необходимо каждый раз обнулять массив, так как данные с предыдущих страниц нам не нужны for row in soup.find_all('a'): #создаем цикл, перебирая каждую найденную кнопку отдельно (на сайте, как мы можем убедится, их примерно 20) для занесения ее в массив if re.findall(r'Скачать', str(row)): #вот нам и пригодился импорт re, мы будем проверять в полученном html-коде, есть ли данные, связанные с кнопкой, так как сейчас переменная row, из-за особенности сайта (блок "a" имеет и иные классы, кроме самих кнопок), содержит много лишнего perehod=perehod+[row['href']] #теперь просто прибавляем к массиву проверенную переменную, предварительно получив из нее лишь свойство тега return perehod #возвращаем переменную Теперь процедура берет каждый раз новую ссылку с каждой страницы и нам необходимо находить адрес новой страницы, где находится новая кнопка с текстовым полем «Скачать», с конечным адресом для скачивания. В главную процедуру пишем:
for y in perehod: #цикл с перебором значений в массиве со ссылками на новую страницу download = parsing2(get_html(y),download #download - массив для хранения двух параметров - название песни и ссылка на ее скачивание Получение HTTP для прямого скачивания
В последней функции мы найдем ссылки для прямого скачивания. Здесь мы будем использовать две новые процедуры:
- re.sub(Шаблон, Новым фрагмент, Строка для замены) ищет все совпадения с шаблоном и заменяет их указанным значением. В качестве первого параметра можно указать ссылку на функцию.
- text — получает текст из html-кода (только из результата поиска BeautifulSoup, строковой тип данных не подойдет).
def parsing2(html,download): #объявляем функцию soup = BeautifulSoup(html, "html.parser") #объявляем новую переменную с полным html страницы table = soup.find('a', ) #в html страницы ищем блок "a" с его "id". В нем и будут храниться данные - название и ссылка на прямое скачивание href='' #переменная хранения адреса песни name='' #переменная хранения названия песни if table != None: #условие: если данные найдены не были, то выполнить условие else row = soup.find('h1', ) #для записи имени находим блок "h1" с его классом и передаем данные в последующую name = re.sub(r'\n\t\t\t\t\t\t','',row.text) #в названии нам будут мешать лишние символы - заменим их на пустую строку. Строковым значением выступит текст от html-кода переменной row href=table.get('href') #в этот раз я использовал .get('href') вместо ['href'] - они идентичны download=[href]+[name] #массив, который мы передавали в функцию, теперь заполняем двумя переменными return download #возвращаем массив else: #условие ответвления не станет вносить изменения в массив download return download #возвращаем пустой массив Запись файла
Нам остается скачать и записать файл.
- Процедура get позволяет отправлять HTTP-запрос, который позже проверим процедурой req.status_code: это список кодов состояния HTTP (список можно найти в Интеренете, статус означает удачный вход).
- Процедура open открывает и закрывает файл для записи в двоичном формате, wb — создает файл с именем, если такового не существует.
if download != []: #условие, проверяющее, не равен ли массив пустому множеству req = requests.get(download[0],stream = True) #переменную приравниваем отправленному запросу от нашей ссылки для скачивания и задаем обязательный параметр stream равного True if req.status_code == requests.codes.ok: #условие проверяет статус http и если он удачен, то продолжить with open(download[1]+'.mp3', 'wb') as a: #открываем файл с присвоением имени a.write(req.content) #запись в файл осуществляется с помощью метода write Используя всего два модуля BeautifulSoup и request можно достигать решений практически любых поставленных задач, связанных с парсингом сайта. С помощью полученных знаний можно адаптировать программу для скачивания иных данных даже с других сайтов. Желаю удачи в вашей работе!
Скачать потоковое аудио / видео проще простого
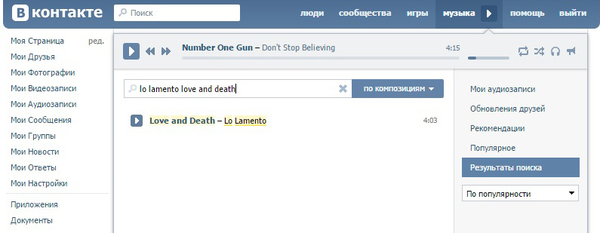
Итак, существует простой способ сохранить себе аудио- или видеофайл, который проигрывается в браузере. Способ работает для музыкальных сайтов (типа Яндекс.Музыка) или видео. Поясню на примере свежего трека Lo Lamento от группы Love and Death (кстати, зацените, песня супер). Выдирать будем из контакта.
1. Заходим на сайт. Вводим в поиск название.
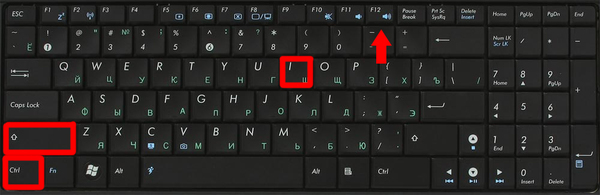
2. Жмем F12 или Ctrl+Shift+I (действительно для хрома, для остальных браузеров работает F12).
3. Справа появляется панель инструментов разработчика.
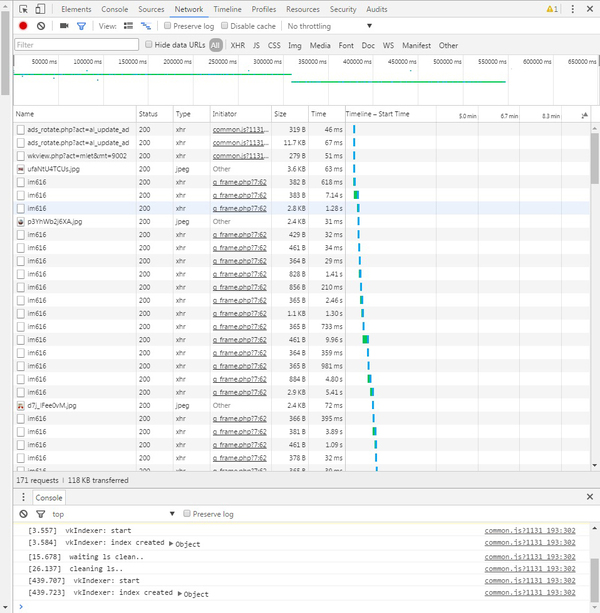
4. Перезагружаем страницу по F5 (аудиопоиск может сброситься, просто введите данные заново), выбираем в панели инструментов вкладку Network, жмем Play и сортируем элементы по типу.

5. В колонке «Type» ищем значение «media» либо «audio» (для звуковых файлов) либо «video» (для видео). Жмем правой кнопкой на ссылке слева от типа.
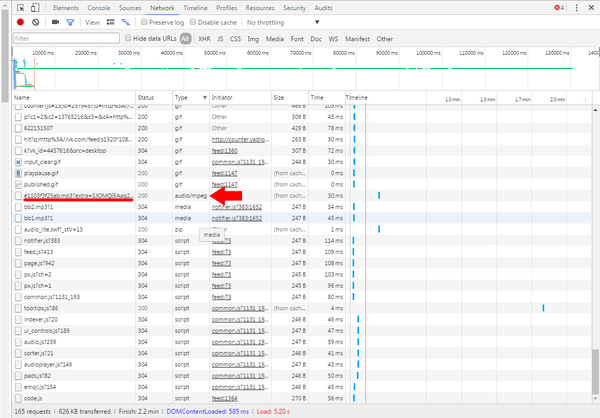
6. В выпадающем списке выбираем пункт «Open link in new tab».
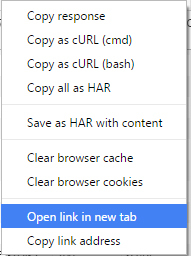
7. В новой вкладке откроется браузерный проигрыватель. Жмете правой кнопкой, выбираете пункт «Сохранить как. » или «Сохранить видео как. «
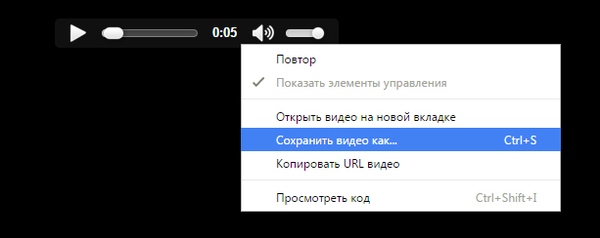
8. Выбираете папку, вводите имя файла, ОК.
Если было, извиняйте, надеюсь, кому-то пригодится.
PS Скорость загрузки выше, чем в этих ваших файлообменниках.
8 лет назад
Ожидал в конце увидеть: «И засовывайте себе все это в ж***»
раскрыть ветку
8 лет назад
Не всегда есть возможность(желание) устанавливать плагины, например в гостях, а скачать трек надо
8 лет назад
может, легче плагин для скачивания проточной лабуды установть, чтобы качать одним кликом?
раскрыть ветку
8 лет назад
Автор, зачем придумывать велосипед и так сильно заморачиваться? Для этого давно существуют плагины браузера.

раскрыть ветку
8 лет назад
пиздец как просто!У меня плагиат стоит и не ебу себе мозги
раскрыть ветку
Похожие посты
10 месяцев назад

Напоминаю как скачать любую книгу
Постоянно слышу от знакомых, что они не могут найти ту или иную книгу в интернете.
Однако, многие этого способа не знают и я повторно напоминаю про него.
Тем более флибуста, что то уж очень стала нестабильно работать, а пользоваться ботами в телеге не очень то удобно. А тут есть удобный поиск по коллекциям и авторам.
Кроме того, прошу попросить вашей помощи. Раздачу поддерживаю уже очень давно. Но в связи с её большим объемом нужна помощь в раздаче.
Те у кого есть возможность попрошу раздать Флибусту и по возможности обновлять раздачу в начале каждого месяца.

2 года назад
Новая версия VDL — бесплатной программы для скачивания видео
Привет пикабу! Выпустил новый релиз VDL, в который вошли исключительно запросы из предыдущей темы.
1. Добавлена возможность загрузки субтитров. Это можно сделать как вручную, кликнув на кнопку загрузки сабов у ролика, так и автоматически, включив в настройках.
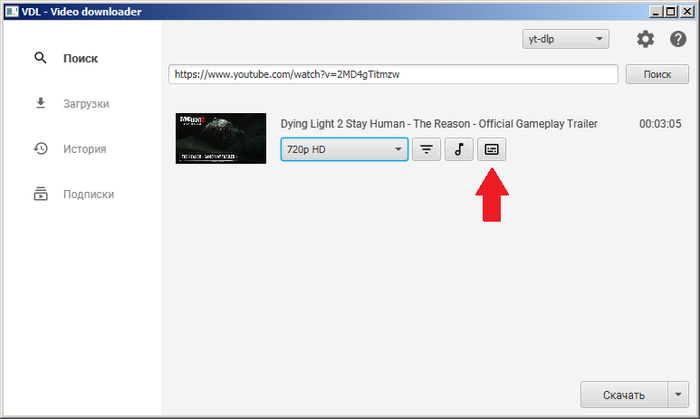
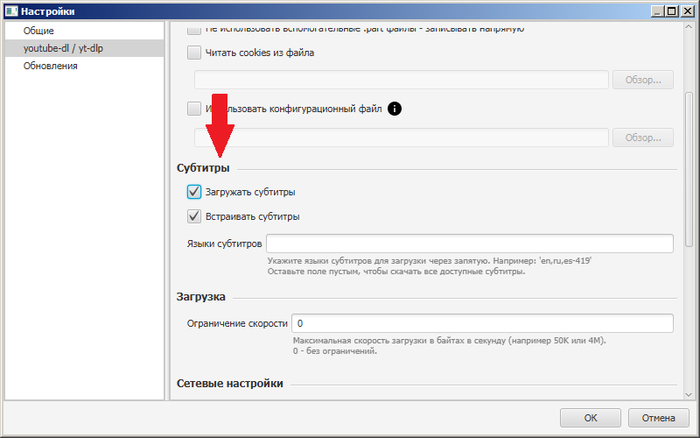
Пункт «Встраивать субтитры» добавляет сабы внутрь контейнера. Если он отключен, то сабы будут скачиваться отдельными файлами в ту же папку, что и видео.
Также в поле «Языки субтитров» можно через запятую указать предпочитаемые субтитры, тогда автоматически будут скачиваться только они. При ручном скачивании всегда качаются все доступные субтитры.
2. Сохранение превьюшек. По клику на превью-изображении ролика картинку можно сохранить. В случае с youtube’ом пытаюсь сохранить изображение максимального качества.
3. Добавил возможность воспроизведения файла прямо из истории. Можно вызвать либо из контекстного меню, либо двойным кликом мышью, либо нажатием клавиши Enter.
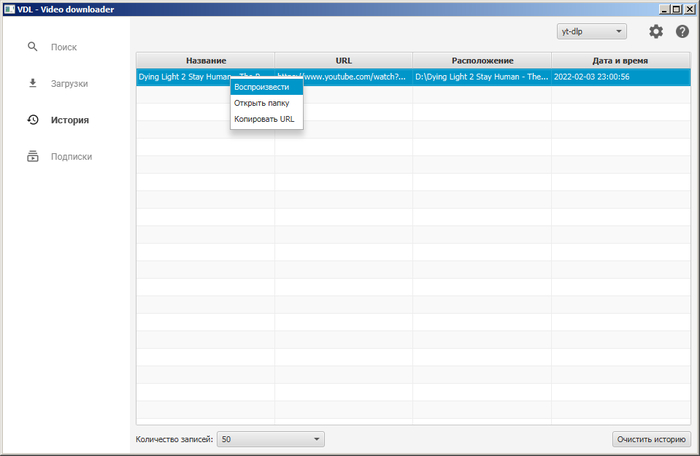
4. Слегка изменил работу с добавлением в историю. Если раньше запись добавлялась сразу после попадания в очередь закачки, то теперь добавление в историю происходит только после успешного окончания загрузки.
5. Добавил возможность включить/выключить прокси прямо с главного окна. Если в настройках указан прокси, то на верхней панели появится чекбокс «Использовать прокси».
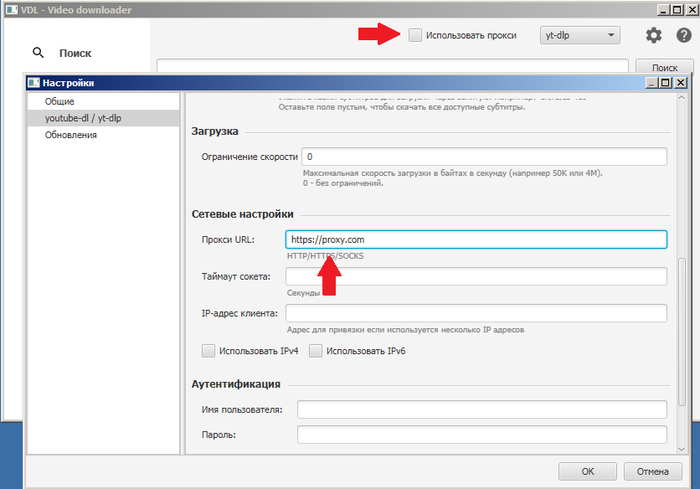
В будущем добавлю возможность создавать список проксей.
6. Вернул украинский язык. Большая благодарность @Alllexxxlllol за перевод.
Как обычно доступны установщики и portable-версии для трех операционных систем: Windows, Linux, MacOS.
Те у кого установлена предыдущая версия 1.7 должны получить обновление автоматически (при условии, что обновление включено). Напишите пожалуйста если что-то пошло не так и программа не обновилась.
p.s. Стоит ли добавить к бинарникам youtube-dlc (еще один форк youtube-dl) или одного yt-dlp достаточно?
Показать полностью 4
2 года назад

Ответ Defaulto в «Скачивание закрытых видео с boomstream и vimeo»
Верез ctrl+shift+j находим файлы в network с помощью поиска
Вводим в поиск process в списке тыкаем на первый файл и получаем ключ для файла [KEY]
создаем файл без расширения [KEY] и туда через блокнот вставляем ключ по типу LuVYKuDgSuvBWGpE
Вводим в поиск playlist (список потоков разного качества) или chunklist (поток с фрагметами)
сохраняем нужный chunklist.m3u8
Качаем например ffmpeg-4.4-full_build (у меня работает с этим билдом)
Создаем файл блокнота и меняем download.txt на download.cmd
Редактируем файл
ffmpeg -protocol_whitelist file,http,https,tcp,tls,crypto -allowed_extensions ALL -i chunklist.m3u8 -c copy -bsf:a aac_adtstoasc out.mp4
(где out.mp4 ваш файл на выходе называйте как хотите либо слитно либо в кавычках «х ы х.mp4»)
Кидаем рядом с ffmpeg.exe файлы chunklist.m3u8 , [KEY] , download.cmd
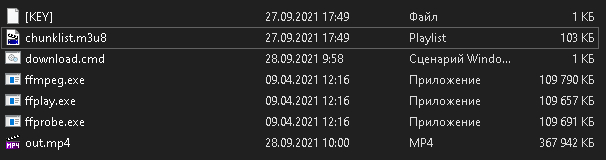
При запуске должно получится следующее
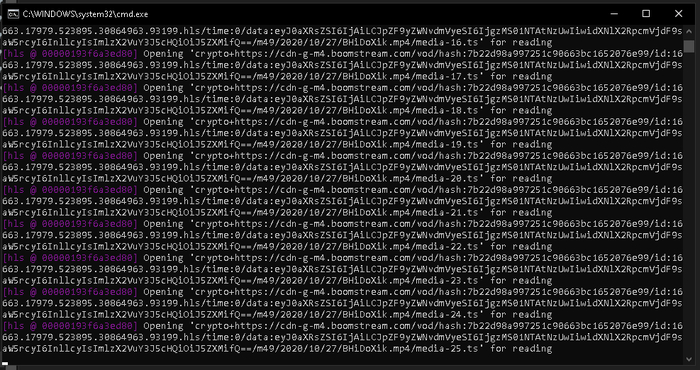
P.S. Если имя конечного файла кириллицей в файле .cmd на выходе получается файл с кривым именем, так что можно через коммандную строку
cd C:\ffmpeg-4.4-full_build\bin
ffmpeg -protocol_whitelist file,http,https,tcp,tls,crypto -allowed_extensions ALL -i chunklist.m3u8 -c copy -bsf:a aac_adtstoasc «Ваше имя файла.mp4»
Показать полностью 2
3 года назад

Супер мощный металлоискатель Clone Pi W на MC33079 Ч.2
Вторая часть
Плата металлоискателя прошита и теперь необходимо сделать катушку. Самый оптимальный вариант это катушка из витой пары UTP диаметром минимум 27 см. Именно с ней показан тест металлоискателя ниже на видео. Применялся самый дешевый UTP (FTP – не подойдет) провод на 4 пары. Маркировка 4*2 24AWG CAT5E (другие тоже подойдут прекрасно) Цена в нашем местном магазине 10 руб. за метр. Делаем три витка провода и паяем их по схеме.

Характеристики моей катушки из UTP:
Сопротивление 7,3 Ом
Индуктивность 0.53 mH
Так же можно мотать катушку эмалированным проводом. Но советую делать больше витков. Для катушки диаметром 27 см. около 30 витков провода сечением 0,5 мм.
Для большей стабильности прибора провод от катушки до платы лучше использовать экранированный (Например КММ) с сечением от 0,5 мм. (лучше больше) Очень рекомендую именно экранированный провод. Но не обязательно, на видео я использую провод ШВВП 2×0,5 (Только ГОСТ!).

Настройку готового металлоискателя я делаю без осциллографа, просто с линейкой. Крутим подстроечный резистор против часовой стрелки до упора (до щелчка), включаем прибор, проверяем чувствительность на 10 коп. после делаем один – два оборота по часовой стрелке. Снова выключаем и включаем прибор и проверяем чувствительность. И так до тех пор, пока не будет найдено положение подстроечника, при котором металлоискатель имеет максимальную чуйку и высокую стабильность. К слову говоря, таких пиков сильной чувствительности может быть три или четыре, но только в одном из положений чувствительность будет максимальной. У меня лучше всего прибор работает при «последнем пике максимальной чувствительности».
Готовая плата отлично помещается внутри корпуса G10010040B и закрывается крышкой G10010040L. Цена вопроса около 40 руб.

Теперь некоторые нюансы по сборке.
Светодиоды нужно использовать с длинными ножками (у моих 3см.) Иначе он не загнутся как надо. Сами светодиоды должны быть яркими. Можно использовать светодиоды 3мм и 5мм. Резисторы R22 и R23 ограничивают ток на светодиоды и их нужно подобрать в соответствии с параметрами тех светодиодов, которые Вы будете применять. У меня сопротивление резисторов 5,1К, но как не странно при этом сопротивлении китайские светодиоды светят очень ярко и самое главное не перегорают.
Если ставить зуммер то параллельно ему нужно добавить резистор. Мне работа с зуммером не понравилась, скорее всего мне просто не везло с ними и я использую динамики.
На видео тест готового Клона. Сразу скажу, большое мучение делать тест клона в помещении и при максимальной чувствительности так как он реагирует на все (стены, пол, потолок) Поэтому чувствительность занижена чтобы показать принцип работы. Идеально настраивать прибор в поле где ничего не мешает. Можно делать настройку подвесив катушку на расстоянии от земли, но так же иногда лучше настраивать прибор положив катушку на грунт, в котором будет осуществляться поиск.