Локально развернутая бд на сервере или бд хостинг [закрыт]
Закрыт. На этот вопрос невозможно дать объективный ответ. Ответы на него в данный момент не принимаются.
Хотите улучшить этот вопрос? Переформулируйте вопрос так, чтобы на него можно было дать ответ, основанный на фактах и цитатах.
Закрыт 4 года назад .
Допустим есть небольшой проект, который развернут на небольшом dns сервере. Имеется бд (postgesql), которая в свою очередь не требует большого кол-ва памяти и скорости. Что лучше, локально развернуть бд на этом сервере или все таки купить бд хостинг, на котором будет она лежать?
Как развернуть БД SQL: полное руководство для начинающих
Чтобы развернуть базу данных SQL, вам нужно выполнить следующие шаги: 1. Установите систему управления базами данных (СУБД) SQL, такую как MySQL, PostgreSQL или Microsoft SQL Server, на свой компьютер или сервер. 2. Создайте новую базу данных или используйте существующую, если у вас уже есть. 3. Загрузите свою SQL-схему или создайте таблицы и связи в вашей базе данных. Вот пример создания таблицы:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(50), email VARCHAR(100) );
4. Загрузите ваши данные в таблицы или создайте новые записи. Вот пример добавления записи в таблицу:
INSERT INTO users (id, name, email) VALUES (1, 'John Doe', 'john.doe@example.com');
5. Проверьте, что ваша база данных успешно развернута, выполните некоторые простые запросы, чтобы убедиться, что они работают правильно. Например, вы можете выполнить запрос на выборку всех пользователей:
SELECT * FROM users;
Надеюсь, это помогает вам развернуть базу данных SQL! Если у вас возникнут еще вопросы, не стесняйтесь задавать!
Детальный ответ
Как развернуть БД SQL
Приветствую! Сегодня мы поговорим о том, как развернуть базу данных SQL. Это важный шаг в разработке веб-приложений, так как база данных является основой для хранения и организации данных. В этой статье я расскажу тебе о нескольких способах разворачивания БД SQL, а также покажу примеры кода.
1. Локальный сервер
Первый способ — это разворачивание БД SQL на локальном сервере. Для этого нам понадобится установленный и сконфигурированный сервер баз данных, такой как MySQL, PostgreSQL или SQLite. Вот пример кода для создания базы данных на локальном сервере MySQL:
CREATE DATABASE database_name;
После создания базы данных, мы можем использовать SQL-запросы для создания таблиц и вставки данных. Вот пример для создания таблицы:
CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, . );
Здесь `table_name` — это имя таблицы, а `column1`, `column2`, `column3` и т.д. — это названия столбцов и их типы данных.
2. Облачные сервисы
Еще один способ — это использование облачных сервисов для развертывания БД SQL. Здесь нет необходимости устанавливать и настраивать сервер баз данных, так как облачные сервисы уже предоставляют готовые решения для разворачивания БД. Примеры популярных облачных сервисов включают Amazon RDS, Google Cloud SQL и Microsoft Azure Database. Чтобы развернуть БД SQL в облачном сервисе, необходимо создать экземпляр базы данных и указать необходимые настройки, такие как размер и вид базы данных, имя пользователя и пароль. После создания экземпляра базы данных, мы можем подключиться к ней с помощью клиента БД и выполнять SQL-запросы.
3. Использование ORM-фреймворков
Третий способ — это использование ORM-фреймворков (Object-Relational Mapping) для развертывания БД SQL. ORM-фреймворки позволяют разработчикам работать с базой данных через объектно-ориентированный интерфейс, что делает процесс разработки более простым и удобным. ORM-фреймворки автоматически генерируют SQL-код на основе определенных моделей данных и могут самостоятельно создавать таблицы и вставлять данные. Примеры популярных ORM-фреймворков для языка Python включают Django ORM и SQLAlchemy.
Заключение
В этой статье мы рассмотрели несколько способов разворачивания базы данных SQL. Вы можете выбрать наиболее подходящий способ в зависимости от ваших потребностей и предпочтений. Не забывайте, что важно понимать основы SQL и иметь хорошее представление о структуре и организации данных в вашей базе данных. Удачи в разработке!
Как развернуть БД SQL: полное руководство для начинающих
Чтобы развернуть базу данных SQL, вам нужно выполнить следующие шаги: 1. Установите систему управления базами данных (СУБД) SQL, такую как MySQL, PostgreSQL или Microsoft SQL Server, на свой компьютер или сервер. 2. Создайте новую базу данных или используйте существующую, если у вас уже есть. 3. Загрузите свою SQL-схему или создайте таблицы и связи в вашей базе данных. Вот пример создания таблицы:
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(50), email VARCHAR(100) );
4. Загрузите ваши данные в таблицы или создайте новые записи. Вот пример добавления записи в таблицу:
INSERT INTO users (id, name, email) VALUES (1, 'John Doe', 'john.doe@example.com');
5. Проверьте, что ваша база данных успешно развернута, выполните некоторые простые запросы, чтобы убедиться, что они работают правильно. Например, вы можете выполнить запрос на выборку всех пользователей:
SELECT * FROM users;
Надеюсь, это помогает вам развернуть базу данных SQL! Если у вас возникнут еще вопросы, не стесняйтесь задавать!
Детальный ответ
Как развернуть БД SQL
Приветствую! Сегодня мы поговорим о том, как развернуть базу данных SQL. Это важный шаг в разработке веб-приложений, так как база данных является основой для хранения и организации данных. В этой статье я расскажу тебе о нескольких способах разворачивания БД SQL, а также покажу примеры кода.
1. Локальный сервер
Первый способ — это разворачивание БД SQL на локальном сервере. Для этого нам понадобится установленный и сконфигурированный сервер баз данных, такой как MySQL, PostgreSQL или SQLite. Вот пример кода для создания базы данных на локальном сервере MySQL:
CREATE DATABASE database_name;
После создания базы данных, мы можем использовать SQL-запросы для создания таблиц и вставки данных. Вот пример для создания таблицы:
CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, . );
Здесь `table_name` — это имя таблицы, а `column1`, `column2`, `column3` и т.д. — это названия столбцов и их типы данных.
2. Облачные сервисы
Еще один способ — это использование облачных сервисов для развертывания БД SQL. Здесь нет необходимости устанавливать и настраивать сервер баз данных, так как облачные сервисы уже предоставляют готовые решения для разворачивания БД. Примеры популярных облачных сервисов включают Amazon RDS, Google Cloud SQL и Microsoft Azure Database. Чтобы развернуть БД SQL в облачном сервисе, необходимо создать экземпляр базы данных и указать необходимые настройки, такие как размер и вид базы данных, имя пользователя и пароль. После создания экземпляра базы данных, мы можем подключиться к ней с помощью клиента БД и выполнять SQL-запросы.
3. Использование ORM-фреймворков
Третий способ — это использование ORM-фреймворков (Object-Relational Mapping) для развертывания БД SQL. ORM-фреймворки позволяют разработчикам работать с базой данных через объектно-ориентированный интерфейс, что делает процесс разработки более простым и удобным. ORM-фреймворки автоматически генерируют SQL-код на основе определенных моделей данных и могут самостоятельно создавать таблицы и вставлять данные. Примеры популярных ORM-фреймворков для языка Python включают Django ORM и SQLAlchemy.
Заключение
В этой статье мы рассмотрели несколько способов разворачивания базы данных SQL. Вы можете выбрать наиболее подходящий способ в зависимости от ваших потребностей и предпочтений. Не забывайте, что важно понимать основы SQL и иметь хорошее представление о структуре и организации данных в вашей базе данных. Удачи в разработке!
Работа с базой данных через SQLAlchemy
FastAPI поддерживает работу с самыми разными системами баз данных: PostgreSQL, MySQL, SQLite, Oracle, Microsoft SQL Server и т.д. Причем мы не ограничены только реалиционными базами данных и равным образом использовать и нереляционные, так называемые NoSQL-системы баз данных.
При работе с базами данных самым простым решением является использование специальных инструментов — ORM (Object Relational Mapper), которые позволяют абстрагироваться от строения базы данных в конкретной СУБД и позволяет автоматически связать сущности в коде Python с таблицами в базе данных. В FastAPI наиболее распространным ORM-инструментом является SQLAlchemy ORM
Рассмотрим работу с базой данных через SQLAlchemy ORM на примере SQLite, поскольку SQLite не требует установки сервера или каких-то дополнительных инструментов. Кроме того, перейти от одной СУБД к другой не составить особого труда и почти не потребует изменения кода взаимодействия с БД, за исключением пары строк кода.
Прежде всего нам надо установить сам SQLAlchemy с помощью команды
pip install sqlalchemy
Определение строки подключения к БД
Прежде всего для подключения к базе данных необходима строка подключения, которая включает адрес базы данных и другие различные параметры, необходимые для подключения. Для разных СУБД строка подключения может отличаться. Пример строки подключения к SQLite:
# строка подключения SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
Для sqlite строка подключения начинается с sqlite:// , затем идет относительный или абсолютный путь к файлу:
sqlite:///относительный_путь/file.db sqlite:////абсолютный_путь/file.db
В данном случае это «./sql_app.db», который указывает, что файл базы данных будет называться «sql_app.db» и будет располагаться в текущей папке.
В зависимости от конкретной субд строка подключения будет различаться. Так, если бы мы подключись бы к базе данных PostgreSQL, то строка подключения имела бы следующий формат:
SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
где user — имя пользователя на сервере PostgreSQL, password — пароль, postgresserver — адрес сервера, а db — имя базы данных на сервере.
При подключении к другим системам баз данных по сути это единственная строка кода, которая потребует изменения.
Определение движка
После определения строки подключения создается движок SQLAlchemy с помощью функции create_engine() :
from sqlalchemy import create_engine SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db" # создание движка engine = create_engine( SQLALCHEMY_DATABASE_URL, connect_args= )
Первый параметр функции указывает на строку подключения — то есть по сути базу данных, к которой идет подключение.
Второй параметр — дополнительные параметры подключения в виде словаря connect_args . В частности, элемент «check_same_thread»: False предназначен только для SQLite и указывает, что для взаимодействия с базой данных SQLite в рамках одного запроса может использоваться больше одного потока. Зачем это надо? По умолчанию SQLite разрешает взаимодействовать с БД только одному потоку, чтобы один поток обрабатывал отдельный запрос, что позволяет предотвратить использование одного потока для разных запросов. Но в FastAPI в рамках одного и того же запроса с базой данных могут взаимодействовать более одного потока. Собственно поэтому необходима подобная настройка для получения необходимых разрешений. При этом каждый запрос будет получать свой собственный сеанс подключения к базе данных через механизм внедрения зависимостей, поэтому в механизме по умолчанию нет необходимости.
При работе с другими СУБД достаточно указать только адрес подключения:
engine = create_engine(SQLALCHEMY_DATABASE_URL)
Определение моделей
Модели представляют классы, которые соответствуют определению таблиц в базе данных и объекты которых хранятся в этих таблицах. И одним из преимуществ SQLAlchemy является то, что мы можем работать таблицами через эти модели-классы языка Python, не прибегая к созданию запросов на языке SQL.
Для создания моделей необходима базовая модель, от которой потом наследуются остальные модели. Для создания базовой модели можно использовать различные способы, но самый короткий — создания класса модели с помощью функции declarative_base() :
from sqlalchemy.orm import DeclarativeBase class Base(DeclarativeBase): pass
То есть в данном случае определяется класс Base — базовая модель. Затем уже можно определить конкретные модели, данные которых будут храниться в БД. Например:
from sqlalchemy.orm import DeclarativeBase from sqlalchemy import Column, Integer, String class Base(DeclarativeBase): pass class Person(Base): __tablename__ = "people" primary_key=True, index=True) name = Column(String) age = Column(Integer,)
Здесь определена модель Person, которая представляет пользователя. Она наследуется от Base и определяет ряд атрибутов.
Атрибут __tablename__ хранит имя таблицы, с которой будет сопоставляться текущая модель. То есть данные класса Person будут храниться в таблице «people».
Для хранения данных в классе модели определяются атрибуты, которые сопоставляются со столбцами таблицы. Такие атрибуты в качестве значения получаются объект Column . В данном случае класс Person определяет три таких атрибута: id, name и age, для которых в таблице people будут создаваться одноименные столбцы.
Класс Column с помощью параметров конструктора определяет настройки столбца в таблицы. Здесь в конструктор вначале передается тип столбца. Так, у id и age тип столбца — Integer , то есть целое число. А столбец name представляет тип String, то есть строку.
Кроме того, в конструктор можно передать ряд дополнительных параметров. Так, для столбца id передаются параметры primary_key и index . Значение primary_key=True указывает, что данный столбец будет представлять первичный ключ. А параметр index=True говорит, что для данного столбца будет создаваться индекс.
Создание базы данных и таблиц
Для создания базы данных и таблиц по метаданным моделей применяется метод Base.metadata.create_all() . Его ключевой параметр — bind принимает класс, который используется для подключения к базе данных. В качестве такого класса применяется созданный ранее движок SQLAlchemy. Если база данных и все необходимые таблицы уже имеются, то метод не создает заново таблицы.
Посмотрим на простейшем примере. Все объединим и определим в файле приложения следующий код:
from sqlalchemy import create_engine from sqlalchemy.orm import DeclarativeBase from sqlalchemy import Column, Integer, String from fastapi import FastAPI # строка подключения SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db" # создаем движок SqlAlchemy engine = create_engine( SQLALCHEMY_DATABASE_URL, connect_args= ) #создаем базовый класс для моделей class Base(DeclarativeBase): pass # создаем модель, объекты которой будут храниться в бд class Person(Base): __tablename__ = "people" primary_key=True, index=True) name = Column(String) age = Column(Integer,) # создаем таблицы Base.metadata.create_all(bind=engine) # приложение, которое ничего не делает app = FastAPI()
После запуска приложения в папке проекта будет создана таблица sql_app.db:
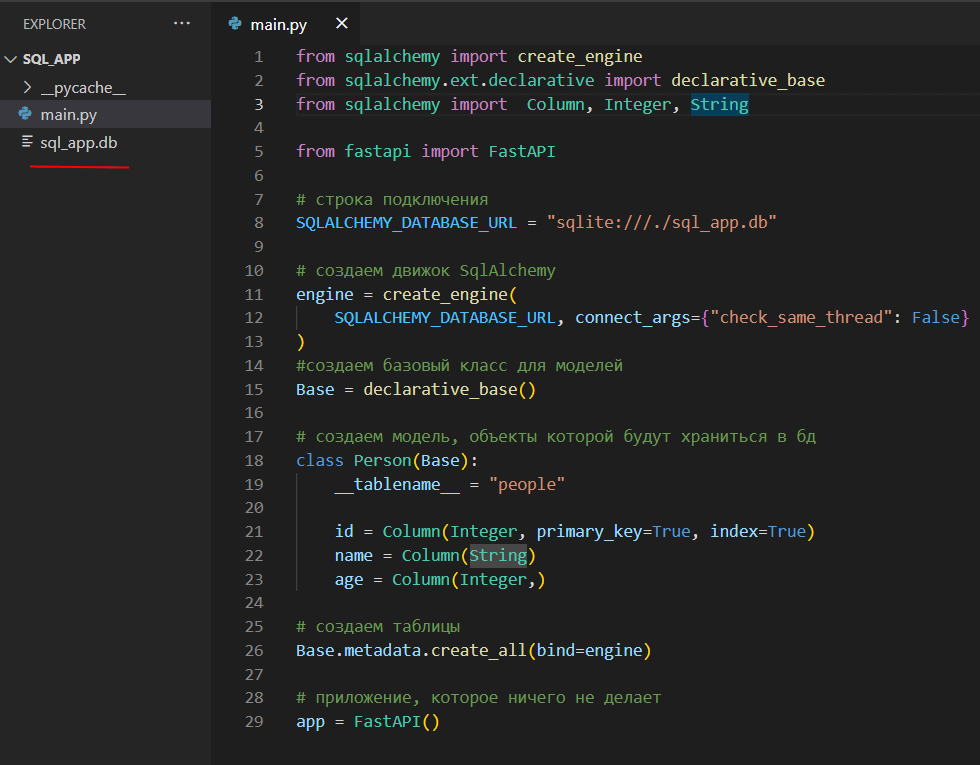
Мы можем открыть эту базу данных с помощью любой программы для просмотра баз данных sqlite (например, с помощью DB Browser for SQLite) и увидеть содержимое бд: