Pandas: как создать новый фрейм данных из существующего фрейма данных
Существует три распространенных способа создания нового кадра данных pandas из существующего кадра данных:
Метод 1: создание нового фрейма данных с использованием нескольких столбцов из старого фрейма данных
new_df = old_df[['col1',' col2']]. copy () Способ 2: создать новый фрейм данных, используя один столбец из старого фрейма данных
new_df = old_df[['col1']]. copy () Способ 3: создать новый фрейм данных, используя все столбцы, кроме одного, из старого фрейма данных
new_df = old_df.drop('col1', axis= 1 ) В следующих примерах показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd #create DataFrame old_df = pd.DataFrame() #view DataFrame print(old_df) Пример 1: создание нового фрейма данных с использованием нескольких столбцов из старого фрейма данных
Следующий код показывает, как создать новый DataFrame, используя несколько столбцов из старого DataFrame:
#create new DataFrame from existing DataFrame new_df = old_df[['points',' rebounds']]. copy () #view new DataFrame print(new_df) points rebounds 0 18 11 1 22 8 2 19 10 3 14 6 4 14 6 5 11 7 6 20 9 7 28 12 #check data type of new DataFrame type (new_df) pandas.core.frame.DataFrame Обратите внимание, что этот новый DataFrame содержит только столбцы точек и восстановлений из старого DataFrame.
Примечание.Важно использовать функцию copy() при создании нового DataFrame, чтобы избежать любого SettingWithCopyWarning , если нам случится каким-либо образом изменить новый DataFrame.
Пример 2: создание нового фрейма данных с использованием одного столбца из старого фрейма данных
Следующий код показывает, как создать новый DataFrame, используя один столбец из старого DataFrame:
#create new DataFrame from existing DataFrame new_df = old_df[['points']]. copy () #view new DataFrame print(new_df) points 0 18 1 22 2 19 3 14 4 14 5 11 6 20 7 28 #check data type of new DataFrame type (new_df) pandas.core.frame.DataFrame Обратите внимание, что этот новый DataFrame содержит только точки и столбец из старого DataFrame.
Пример 3: создание нового фрейма данных с использованием всех столбцов, кроме одного, из старого фрейма данных
В следующем коде показано, как создать новый DataFrame, используя все столбцы, кроме одного, из старого DataFrame:
#create new DataFrame from existing DataFrame new_df = old_df.drop('points', axis= 1 ) #view new DataFrame print(new_df) team assists rebounds 0 A 5 11 1 A 7 8 2 A 7 10 3 A 9 6 4 B 12 6 5 B 9 7 6 B 9 9 7 B 4 12 #check data type of new DataFrame type (new_df) pandas.core.frame.DataFrame Обратите внимание, что этот новый DataFrame содержит все столбцы из исходного DataFrame, кроме столбца точек .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Python:
Как создать pandas DataFrame
DataFrame — это специальная структура данных в очень популярной Python библиотеки pandas. Работа с библиотекой pandas часто заключается в том что нужно создать из данных DataFrame, а дальше что-то делать с этими данными, лежащими в DataFrame.
Есть несколько способов создать DataFrame.
Создать DataFrame из данных, записанных в коде программы
Самый простой способ создать DataFrame — это передать конструктору словарь. Ключи станут названиями колонок, а значения (в которых содержатся списки) станут данными в этих колонках.
import pandas as pd df = pd.DataFrame() Вот пример как это выглядит в Jupyter Notebook:
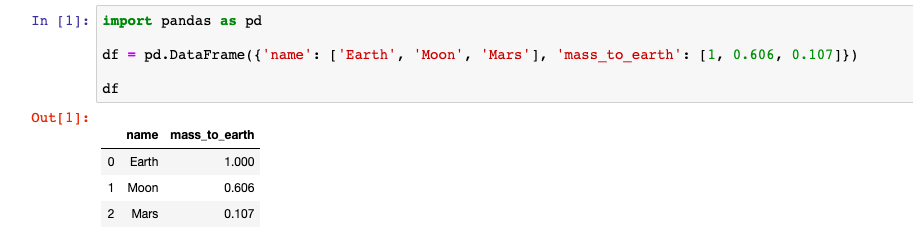
Но не всегда удобно задавать данные по столбцам. Можно создать DataFrame и из данных, которые разбиты по строкам. Для этого в конструктор нужно передать список в котором содержатся данные для строк. Вот пример создания DataFrame с данными как из прошлого примера, но по строкам, а не по столбцам:
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]]) Но при такой записи система не знает как нужно называть столбцы, поэтому названия столбцов становятся числа начиная с нуля. В этих данных две колонки, поэтому они называются ноль и один:
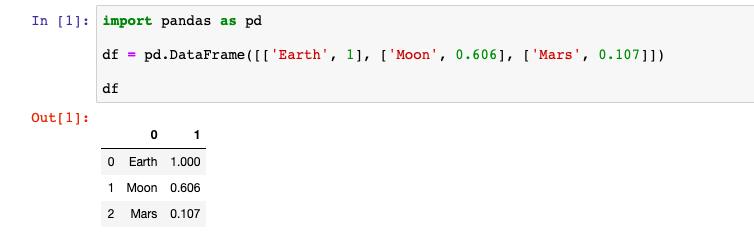
Для того чтобы вместо чисел были осмысленные названия колонок нужно указать список названий в именованном аргументе columns:
df = pd.DataFrame([['Earth', 1], ['Moon', 0.606], ['Mars', 0.107]], columns=['name', 'mass_to_earth']) Но запись данных в коде программы подходит только для очень простых ситуаций, когда данных немного. Обычно данные в DataFrame загружаются из какого-то внешнего источника, например из файла из из базы данных.
Создать DataFrame из csv файла
Вот содержимое файла solar-system.csv:
name,mass_to_earth Earth,1 Moon,0.606 Mars,0.107 Csv — это очень распространенный формат (расшифровывается как «comma separated values»,— «значения разделенные запятыми»). В файле solar-system.csv в первой строчке находится заголовок с названиями столбцов, все остальные строки — это данные. Разделитель между элементами это символ запятая. Для того чтобы загрузить данные из этого файла в DataFrame нужно сказать:
df = pd.read_csv('solar-system.csv') Но иногда формат csv файла выглядит несколько иначе. Бывает что в качестве разделителя используется не запятая, а какой-то другой символ, например точка с запятой или символ табуляции (в это случае файл иногда бывает с расширением .tsv — «tab separated values»). read_csv можно указать какой разделитель использовать:
df = pd.read_csv('solar-system.tsv', sep='\t') Бывает что в csv файле нет заголовка, в первой строке сразу идут данные. В таком случае нужно передать None в именованный параметр header:
df = pd.read_csv('solar-system.csv', header=None) Но в такой ситуации система не будет знать какие названия столбцов использовать и будут использованы цифры начиная с нуля. Для того чтобы установить имена колонок нужно передать параметр names:
df = pd.read_csv('solar-system.csv', header=None, names=['name', 'mass_to_earth']) Создать DataFrame из jsonl файла
Кроме csv еще есть достаточно популярный формат для хранения данных в текстовых файла — jsonl. JSON Lines. При использовании этого формата в каждой строчке файла содержится однострочный json. Это формат лучше чем csv, так как строго регламентирует что должно быть разделителем и как нужно экранировать.
Вот пример содержимого файла solar-system.jsonl:
Для того чтобы загрузить его в DataFrame нужно сказать:
pd.read_json('solar-system.jsonl', lines=True) Создать DataFrame из результата sql запроса
Вот пример кода, который загружает в DataFrame таблицу с результатом sql запроса из sqlite базы данных:
import sqlite3 import pandas as pd cnx = sqlite3.connect(r'/data/db.db') df = pd.read_sql_query("SELECT * FROM users", cnx) Создать DataFrame из файла в интернете
Иногда необходимо создать DataFrame с данными которые лежат где-то в интернете. Например, создать DataFrame из csv файла, который лежит на GitHub.
pandas.read_csv умеет рабоать не только с локальными файлами, но и с файлами, которые лежат в интернете. Вот как загрузить в DataFrame данные про страны из файла по ссылке:
import pandas as pd url = 'https://raw.githubusercontent.com/lukes/ISO-3166-Countries-with-Regional-Codes/master/all/all.csv' df = pd.read_csv(url) Дальше
Как создать датафрейм pandas из другого датафрейма: наглядное руководство с примерами ��
Чтобы создать датафрейм Pandas из другого датафрейма, вы можете использовать один из следующих методов: 1. copy() : Создайте копию исходного датафрейма.
import pandas as pd df1 = pd.DataFrame() df2 = df1.copy() print(df2) 2. reindex() : Создайте новый датафрейм с индексами, указанными пользователем.
import pandas as pd df1 = pd.DataFrame() df2 = df1.reindex([0, 2]) print(df2) 3. loc[] или iloc[] : Создайте новый датафрейм, выбрав нужные строки и столбцы по меткам или позициям.
import pandas as pd df1 = pd.DataFrame() df2 = df1.loc[1:, 'B'] print(df2) Выберите метод в зависимости от вашей конкретной задачи и требуемого результата.
Детальный ответ
Как создать датафрейм pandas из другого датафрейма
Здравствуйте! В этой статье мы расскажем вам, как создать новый датафрейм в библиотеке pandas на основе данных из другого существующего датафрейма. Поехали! Для начала, предположим, что у нас есть исходный датафрейм, который мы будем использовать. Возьмем следующий пример:
import pandas as pd # Создаем исходный датафрейм df1 = pd.DataFrame()
В переменной «df1» у нас теперь есть исходный датафрейм, содержащий информацию об имени, возрасте и городе трех человек. Теперь давайте рассмотрим различные способы создания нового датафрейма на основе исходного.
Метод copy()
Первый способ — использование метода copy(). Этот метод создает полную копию исходного датафрейма. Вот как это можно сделать:
# Создаем новый датафрейм, полностью копируя исходный df2 = df1.copy()
Теперь в переменной «df2» у нас есть полная копия исходного датафрейма «df1». Мы можем вносить изменения в новый датафрейм, не затрагивая исходный.
Метод loc[]
Второй способ — использование метода loc[]. Этот метод позволяет выбирать определенные строки или столбцы из исходного датафрейма и создавать на их основе новый. Допустим, мы хотим создать новый датафрейм только с информацией о людях, проживающих в Москве. Мы можем сделать это следующим образом:
# Создаем новый датафрейм на основе строк, соответствующих условию df3 = df1.loc[df1['Город'] == 'Москва']
Теперь в переменной «df3» у нас есть новый датафрейм, содержащий только информацию о людях, проживающих в Москве.
Метод merge()
Третий способ — использование метода merge(). Этот метод позволяет объединять различные датафреймы на основе общих столбцов. Допустим, у нас есть еще один датафрейм, содержащий информацию о возрасте и зарплате людей:
df4 = pd.DataFrame()
Мы можем объединить этот датафрейм с исходным на основе столбца «Имя» следующим образом:
# Создаем новый датафрейм, объединяя два исходных df5 = df1.merge(df4, on='Имя')
Теперь в переменной «df5» у нас есть новый датафрейм, содержащий информацию об имени, возрасте, городе и зарплате людей. Это лишь некоторые из возможных способов создания нового датафрейма на основе другого в библиотеке pandas. У библиотеки pandas есть множество других методов и функций, которые могут быть полезными в различных ситуациях. Вам стоит ознакомиться с документацией библиотеки для получения более подробной информации. Мы надеемся, что эта статья помогла вам понять, как создать датафрейм pandas на основе другого датафрейма. Если у вас остались вопросы, не стесняйтесь задавать их! Успехов в изучении pandas!
Создание DataFrame из значений другого DataFrame по условным правилам
Дано: df1 из трех столбцов — Параметр, Время, Значение . Наблюдения представляют собой пакет параметров, измеренных в одно и то же время, т.е так:
Параметр 1 -- Значение -- Время 1 Параметр 2 -- Значение -- Время 1 Параметр 3 -- Значение -- Время 1 Параметр 1 -- Значение -- Время 2 Параметр 2 -- Значение -- Время 2 Параметр 1 -- Значение -- Время 3 Требуется получить другой датафрейм, df2 , такой, чтобы Параметры стали столбцами, времена — индексами, а в ячейках значения, например так:
Время -- Параметр 1 -- Параметр 2 -- Параметр 3 Время 1 -- Значение -- Значение -- Значение Время 2 -- Значение -- Значение -- NAN Время 3 -- Значение -- NAN -- NAN На практике такой паттерн не работает:
for col in tqdm(df_out.columns): condition = df_out.index == np.unique(df['Дата и время']) df_out[col] = np.where(condition, df[np.unique(df['Дата и время']) == df_out.index][col] Подскажите, как это обойти? Спасибо.