За что отвечает функция headers
HTML-элемент представляет собой вводный контент, обычно группу вводных или навигационных средств. Он может содержать другие элементы-заголовки, а также логотип, форму поиска, имя автора и другие элементы.
Интерактивный пример
| Категории контента | Основной поток, явный контент. |
|---|---|
| Допустимое содержимое | Основной поток, кроме и |
| Пропуск тегов | Нет, открывающий и закрывающий теги обязательны. |
| Допустимые родители | Любой элемент, который разрешает контент основного потока в качестве содержимого. Обратите внимание, что элемент не должен быть потомком элемента , или другого элемента . |
| Допустимые ARIA-роли | group (en-US) , presentation (en-US) |
| DOM-интерфейс | HTMLElement |
Примечание
Элемент не относится к секционному контенту , а значит не создаёт новый раздел в структуре HTML-документа. При этом элемент обычно должен содержать заголовок ближайшего раздела (элементы h1 — h6 ), но это не обязательно.
Историческое употребление
Несмотря на то, что элемент не попал в спецификации до HTML5, на самом деле, он существовал с самого начала HTML. Первоначально, на самом первом веб-сайте он использовался как элемент . В какой-то момент было принято решение использовать другое имя. Позже, это позволило занять другую роль.
Атрибуты
К этому элементу применимы только глобальные атрибуты.
Заголовки HTTP
Заголовки HTTP позволяют клиенту и серверу отправлять дополнительную информацию с HTTP запросом или ответом. В HTTP-заголовке содержится не чувствительное к регистру название, а затем после ( : ) непосредственно значение. Пробелы перед значением игнорируются.
Пользовательские собственные заголовки исторически использовались с префиксом X, но это соглашение было объявлено устаревшим в июне 2012 года из-за неудобств, вызванных тем, что нестандартные поля стали стандартом в RFC 6648; другие перечислены в реестре IANA, исходное содержимое которого было определено в RFC 4229. IANA также поддерживает реестр предлагаемых новых заголовков HTTP.
HTTP-заголовки сопровождают обмен данными по протоколу HTTP. Они могут содержать описание данных и информацию, необходимую для взаимодействия между клиентом и сервером. Заголовки и их статусы перечислены в реестре IANA, который постоянно обновляется.
Заголовки могут быть сгруппированы по следующим контекстам:
- Основные заголовки применяется как к запросам, так и к ответам, но не имеет отношения к данным, передаваемым в теле.
- Заголовки запроса содержит больше информации о ресурсе, который нужно получить, или о клиенте, запрашивающем ресурс.
- Заголовки ответа (en-US) содержат дополнительную информацию об ответе, например его местонахождение, или о сервере, предоставившем его.
- Заголовки сущности содержат информацию о теле ресурса, например его длину содержимого или тип MIME (en-US).
Заголовки также могут быть сгруппированы согласно тому, как прокси (proxies) обрабатывают их:
Сквозные заголовки Эти заголовки должны быть переданы конечному получателю сообщения: серверу для запроса или клиенту для ответа. Промежуточные прокси-серверы должны повторно передавать эти заголовки без изменений, а кеши должны их хранить.
Хоп-хоп заголовки (Хоп-хоп заголовки) Эти заголовки имеют смысл только для одного соединения транспортного уровня и не должны повторно передаваться прокси или кешироваться. Обратите внимание, что с помощью общего заголовка Connection могут быть установлены только заголовки переходов.
Аутентификация
WWW-Authenticate (en-US) Определяет метод аутентификации, который должен использоваться для доступа к ресурсу. Authorization Содержит учётные данные для аутентификации агента пользователя на сервере. Proxy-Authenticate (en-US) Определяет метод аутентификации, который должен использоваться для доступа к ресурсам на прокси-сервере. Proxy-Authorization (en-US) Содержит учётные данные для аутентификации агента пользователя с прокси-сервером.
Ниже перечислены основные HTTP заголовки с кратким описанием:
| Заголовок | Описание | Подробнее | Стандарт |
|---|---|---|---|
| Accept | Список MIME типов, которые ожидает клиент. | HTTP Content Negotiation | HTTP/1.1 |
| Accept-CH |
Introduced in HTTP 1.1’s RFC 2068, section 19.6.2.4, it was removed in the final HTTP 1.1 spec, then reintroduced, with some extensions, in RFC 5988
Содержит URL-адрес ресурса, из которого был запрошен обрабатываемый запрос. Если запрос поступил из закладки, прямого ввода адреса пользователем или с помощью других методов, при которых исходного ресурса нет, то этот заголовок отсутствует или имеет значение «about:blank».
Это ошибочное имя заголовка (referer, вместо referrer) было введено в спецификацию HTTP/0.9, и ошибка должна была быть сохранена в более поздних версиях протокола для совместимости.
Примечание
Примечание: The Keep-Alive request header is not sent by Gecko 5.0; previous versions did send it but it was not formatted correctly, so the decision was made to remove it for the time being. The Connection or Proxy-Connection header is still sent, however, with the value «keep-alive».
Протокол HTTP и работа с заголовками
Весь современный веб построен на модели взаимодействия клиента и сервера. Как она работает:
- браузер пользователя (клиент) отправляет на сервер запрос с адресом сайта (URL);
- сервер получает запрос и отдаёт клиенту запрошенный контент.
Для реализации процесса используется универсальный протокол HTTP.
Как работает HTTP
Программировать на PHP можно и без знания протокола HTTP. Но для решения ряда задач нужно знать, как именно работает веб-сервер. Ведь PHP — это в первую очередь серверный язык программирования.
���� Протокол HTTP очень прост и состоит из двух частей:
- Заголовков запроса/ответа;
- Тела запроса/ответа.
Сначала идёт список заголовков, затем пустая строка, после неё (если есть) тело запроса/ответа.
И клиент, и сервер могут посылать друг другу заголовки и тело ответа. У клиента доступные заголовки будут одни, у сервера — другие. Рассмотрим, как выглядит работа по протоколу HTTP, когда пользователь хочет загрузить главную страницу социальной сети «ВКонтакте».
-
Браузер пользователя устанавливает соединение с сервером vk.com и отправляет следующий запрос:
GET / HTTP/1.1 Host: vk.com HTTP/1.1 200 OK Server: ApacheВКонтакте
Нам интересен самый первый шаг, где браузер инициирует запрос к серверу vk.com.
Здесь определяется несколько важных параметров:
- Метод, которым будет запрошен контент;
- Адрес страницы;
- Версия протокола.
GET — это метод (глагол), который применяется для доступа к указанной странице. GET используется очень часто, потому что говорит серверу о том, что клиент хочет прочитать указанный документ. Есть и другие методы, один из них мы рассмотрим уже в следующем разделе.
После метода идёт указание на адрес страницы — URI (универсальный идентификатор ресурса). Мы запрашиваем главную страницу сайта, поэтому используется просто слэш — / . В конце строки указана версия протокола, почти всегда это будет HTTP/1.1 .
После строки с указанием основных параметров следует перечисление заголовков. Они передают серверу дополнительную полезную информацию: название и версию браузера, язык, кодировку, параметры кэширования и так далее.
Среди заголовков, которые передаются при каждом запросе, есть один обязательный и самый важный — это заголовок Host . Он определяет адрес домена, который запрашивает браузер клиента.
Сервер, получив запрос, ищет у себя сайт с доменом из заголовка Host , а также указанную страницу. Если запрошенный сайт и страница найдены, клиенту отправляется ответ: HTTP/1.1 200 OK . Такой ответ означает, что документ найден и будет отправлен клиенту.
�� Общая структура стартовой строки ответа:
HTTP/Версия Код состояния Пояснение
Больше всего здесь интересен именно код состояния, он же код ответа сервера. В этом примере код ответа — 200, что означает: сервер работает, документ найден и будет передан клиенту.
Не всегда всё идёт гладко.
Например, запрошенный документ отсутствует или сервер перегружен. В таком случае клиент не получит контент, а код ответа будет отличным от 200.
- 404 — если сервер доступен, но запрошенный документ не найден;
- 503 — если сервер не может обрабатывать запросы по техническим причинам.
Спецификация HTTP 1.1 определяет 40 различных кодов HTTP.
После стартовой строки следуют заголовки, а затем тело ответа.
Работа с заголовками в PHP
В PHP есть все возможности для взаимодействия с HTTP:
- Получение тела запроса;
- Получение заголовков запроса;
- Добавление/изменение заголовков ответа;
- Управление телом ответа.
Разберём всё по порядку.
Получение тела запроса
Тело запроса — это информация, которую передал браузер при запросе страницы. Но тело запроса присутствует только, если браузер запросил страницу методом POST . Дело в том, что POST — это метод, специально предназначенный для отправки данных на сайт. Чаще всего метод POST браузер задействует в момент отправки формы. В этом случае телом запроса будет содержимое формы.
В PHP-сценарии все данные отправленной формы будут доступны в специальном массиве $_POST . Более подробно об этом написано в следующей главе, посвящённой формам.
Получение заголовков запроса
Напомним ещё раз, что заголовки запроса — это метаинформация, отправленная браузером при запросе сценария.
PHP автоматически извлекает такие заголовки и помещает их в специальный массив — $_SERVER . Стоит отметить, что в этом массиве, помимо заголовков, есть и другая информация. Значения заголовков запроса находятся под ключами, которые начинаются с HTTP_ . Подробно всё содержимое этого массива описано в официальной документации.
Пример, как получить предыдущую страницу, с которой перешёл пользователь:
print($_SERVER['HTTP_REFERER']); Добавление/изменение заголовков ответа
В PHP-сценарии можно управлять всеми заголовками ответа, которые попадут к пользователю вместе с контентом страницы. Это возможно, потому что PHP работает на стороне веб-сервера и имеет с ним очень тесную интеграцию. Вот примеры сценариев, когда пригодится управление заголовками ответа:
- Кэширование;
- Переадресация пользователя;
- Установка cookies;
- Отправка файлов;
- Передача дополнительной информации браузеру.
Заголовки ответа нужны для выполнения множества важных задач.
В PHP есть функция для отправки или смены заголовков: header() .
Она принимает имя и значение заголовка и добавляет его в список из всех заголовков, которые уйдут в браузер пользователя после окончания работы сценария.
Например, так выполняется перенаправление пользователя на другую страницу:
header("Location: /index.php"); За переадресацию отвечает заголовок с именем Location , а через двоеточие задаётся значение — адрес страницы для перехода.
Важное замечание по использованию заголовков
Есть одно ограничение: заголовки нельзя отправлять, если пользователю к этому моменту уже отправили любой контент. То есть если показать что-то на экране, например, через функцию print() , то после этого заголовки поменять уже не получится.
Управление телом ответа
Всё, что PHP выводит на экран, является содержимым ответа. Иными словами, вызовы функций print , echo или показ текста через шорт-теги являются телом ответа, которое попадает в браузер пользователю.
Параметры запроса
Мы привыкли, что на нашем сайте каждый PHP-сценарий отвечает за одну страницу. Посетитель сайта вводит в адресную строку путь, который состоит из имени домена и имени PHP-сценария. Например, так: http://weather-diary.ru/day.php .
Но как быть, если одна страница должна показывать разную информацию?
На сайте дневника наблюдений за погодой мы сделали отдельную страницу, чтобы показывать на ней информацию о погоде из истории за один конкретный день. То есть страница одна, но показывает разные данные, в зависимости от выбранного дня.
Также пользователи хотят добавить в закладки адреса страниц с нужными им днями. Получается, что, имея только один сценарий, сделать страницу, способную показывать дневник погоды за любой день невозможно? Вовсе нет!
Из чего состоит URI
URI — это уникальный идентификатор ресурса. Ресурс в нашем случае — это полный путь до страницы сайта. И вот как может выглядеть ресурс для показа погоды за конкретный день:
Разберём, из чего состоит этот URI.
Здесь есть имя домена: weather-diary.ru .
Затем идёт имя сценария: day.php .
А всё, что идёт после — это параметры запроса.
Параметры запроса — это как бы дополнительные атрибуты адреса страницы. Они отделяются от имени страницы знаком запроса. В примере выше параметр запроса только один: date=2017-10-30.
Имя этого параметра: date , значение: 2017-10-15 .
Параметров запроса может быть несколько, тогда они разделяются знаком амперсанда: ?date=2017-10-15&tscale=celsius .
В примере выше указывается два аргумента: дата и единица измерения температуры.
Параметры запроса — как внешние переменные
Теперь в адресе страницы используются параметры запроса, но какая нам от этого польза? Она состоит в том, что если имя страницы вызывает к исполнению соответствующий PHP-сценарий, то параметры запроса превращаются в специальные внешние переменные в этом сценарии. То есть если в адресе присутствуют такие параметры, то их легко получить внутри кода сценария и выполнить с ними какие-нибудь действия. Например, показать погоду за конкретный день в выбранных единицах измерения.
Получение параметров запроса
Если есть внешние переменные, то как их прочитать?
Все параметры запроса находятся в специальном, ассоциативном массиве $_GET , а значит, сценарий, вызванный с таким адресом: day.php?date=2017-10-15&tscale=celsius будет иметь в этом массиве два значения с ключами date и scale .
Запрос на получение данных за выбранный день выглядит так:
В первой строчке примера выше мы получаем значение параметра date , а если он отсутствует, то используем текущую дату в качестве выбранного дня.
Никогда не полагайтесь на существование параметра в массиве $_GET и делайте проверку либо функцией isset() , либо как в этом примере.
В этом задании вы сможете потренироваться использовать $_GET .
Формирование URI с параметрами запроса
Иногда нужно совершить обратную операцию: сформировать адрес страницы, включив туда нужные параметры запроса из массива.
Скажем, на странице погодного дневника надо поставить ссылку на следующий и предыдущий день. Нужно также сохранить выбранную единицу измерений. То есть необходимо сохранить текущие параметры запроса, поменять значение одного из них (день), и сформировать новую ссылку.
Вот как это можно сделать:
Здесь мы использовали две функции:
- basename(__FILE__) — получает имя текущего сценария;
- http_build_query() — преобразует ассоциативный массив в строку запроса.
«Доктайп» — журнал о фронтенде. Читайте, слушайте и учитесь с нами.
HTTP-заголовки для ответственного разработчика

Сегодня быть онлайн — это привычное состояние для многих людей. Все мы покупаем, общаемся, читаем статьи, ищем информацию на разные темы. Сеть соединяет нас со всем миром, но прежде всего, она соединяет людей. Я сам пользуюсь интернетом уже 20 лет, и мои отношения с ним изменились восемь лет назад, когда я стал веб-разработчиком.
Разработчики соединяют людей.
Разработчики помогают людям.
Разработчики дают людям возможности.
Разработчики могут создать сеть для всех, но эту способность необходимо использовать ответственно. В конце концов, важно создавать вещи, которые помогают людям и расширяют их возможности. В этой статье я хочу рассказать о том, как HTTP-заголовки могут помочь вам создавать лучшие продукты для лучшей работы всех пользователей в интернете.
HTTP — протокол передачи гипертекста
Давайте сначала поговорим о HTTP. HTTP — это протокол, используемый компьютерами для запроса и отправки данных по интернету.
Когда браузер запрашивает ресурс с сервера, он использует HTTP. Этот запрос включает набор пару ключ-значение, содержащих такую информацию, как версия браузера или форматы файлов, которые он понимает. Эти пары называются заголовками запросов.
Сервер отвечает запрашиваемым ресурсом, но также отправляет заголовки ответа, содержащие информацию о ресурсе или самом сервере.
Request: GET https://the-responsible.dev/ Accept: text/html,application/xhtml+xml,application/xml Accept-Encoding: gzip, deflate, br Accept-Language: en-GB,en-US;q=0.9,en;q=0.8,de;q=0.7 . Response: Connection: keep-alive Content-Type: text/html; charset=utf-8 Date: Mon, 11 Mar 2019 12:59:38 GMT . Response BodyСегодня HTTP является основой интернета и предлагает множество способов оптимизировать работу пользователей. Давайте посмотрим, как можно использовать заголовки HTTP для создания безопасной и доступной сети.
Сеть должна быть безопасной
Раньше я никогда не чувствовал опасности, когда искал что-то в интернете. Но чем больше я узнавал о всемирной паутине, тем больше я беспокоился. Вы можете почитать, как хакеры меняют глобальные CDN-библиотеки, случайные сайты майнят криптовалюту в браузере своих посетителей, а также о том, как с помощью социальной инженерии люди регулярно получают доступ к успешным проектам с открытым исходным кодом. Это нехорошо. Но почему вас должно это волновать?
Если вы сегодня разрабатываете для веба, то не просто пишете код. Сегодня в веб-разработке над одним сайтом работает много людей. Возможно, вы также используете много открытого исходного кода. Кроме того, для маркетинговых целей вы можете включить несколько сторонних скриптов. Сотни людей предоставляют код, запущенный на вашем сайте. И разработчикам приходится работать в подобных реалиях.
Можно ли доверять всем этим людям и всему исходному коду?
Я не думаю, что следует доверять какому-либо стороннему коду. К счастью, есть способы защитить свой сайт и сделать его более безопасным. Кроме того, такие инструменты, как helmet могут быть полезны, например, для экспресс-приложений.
Если вы хотите проанализировать, сколько стороннего кода запускается на вашем сайте, можно посмотреть в панели разработчика или попробовать Request Map Generator.
HTTPS и HSTS — убедитесь, что ваше соединение безопасно
Защищённое соединение является основой безопасного интернета. Без зашифрованных запросов, проходящих через HTTPS, нельзя быть уверенным, что между вашим сайтом и посетителями больше никого нет. Человек может быстро настроить общедоступную сеть Wi-Fi и совершить атаку «человек посередине» на любого, кто подключится к этой сети. Как часто вы используете общедоступный Wi-Fi? Кроме того, как часто вы проверяете, заслуживает ли он доверия?
К счастью, сегодня сертификаты TLS бесплатны; HTTPS стал стандартом, и браузеры предоставляют передовые функции только для защищенных соединений, и даже отмечают веб-сайты, не относящиеся к HTTPS, как небезопасные, что способствует внедрению этого протокола. К сожалению, мы не всегда в безопасности, когда находимся в интернете. Когда кто-то хочет открыть сайт, он не вводит протокол в адресную строку (и почему вообще должен?). Это приводит к созданию незашифрованного HTTP-запроса. Безопасно работающие сайты перенаправляют пользователя на HTTPS. Но что если кто-то перехватит первый незащищенный запрос?
Вы можете использовать заголовки ответа HSTS (HTTP Strict Transport Security), чтобы сообщить браузерам, что ваш сайт работает только через HTTPS.
Strict-Transport-Security: max-age=1000; includeSubDomains; preloadЭтот заголовок говорит браузеру, что вы не хотите использовать HTTP-запросы, и тогда он автоматически применит те же запросы к такому же источнику с защищенным соединением. Если вы попытаетесь открыть такой же URL через HTTP, браузер снова будет использовать HTTPS и перенаправит пользователя.
Вы можете настроить, как долго этот параметр должен оставаться активным ( max-age в секундах), если захотите потом снова использовать HTTP. Если вы хотите включить поддомены, то можете настроить это с помощью includeSubDomains .
Если вы хотите сделать всё возможное, чтобы браузер никогда не запрашивал ваш сайт по HTTP, можете также задать указатель preload и отправить ваш сайт в глобальный список. Если конфигурация HSTS вашего сайта соответствует минимальному max-age в один год и активна для поддоменов, он может быть включен во внутренний список браузер для сайтов, работающих только через HTTPS.
Задумывались ли вы когда-нибудь, почему вы больше не можете использовать в своем браузере через HTTP локальные переменные среды, такие как my-site.dev ? Причина именно в этом внутреннем списке — .dev автоматически включаются в этот список, поскольку в феврале 2019 года он стал настоящим доменом верхнего уровня.
Заголовок HSTS не только делает ваш сайт немного безопаснее, но и ускоряет его работу. Представьте себе, что кто-то заходит по медленному мобильному соединению. Если первый запрос сделан через HTTP только для получения перенаправления, то пользователь может несколько секунд ничего не видеть на экране. А с помощью HSTS вы можете сэкономить эти секунды, и браузер автоматически будет использовать HTTPS.
CSP — четко укажите, что разрешено на вашем сайте
Теперь, когда ваш сайт работает через защищенное соединение, вы можете столкнуться с проблемой, когда браузеры начинают блокировать запросы, которые выходят на незащищенный адрес из-за политик смешанного контента. Заголовок Content Security Policy (CSP) предлагает отличный способ обработки таких ситуаций. Вы можете установить свой набор правил CSP с помощью мета-элементов в предоставляемом HTML или через HTTP-заголовки.
Content-Security-Policy: upgrade-insecure-requestsУказатель upgrade-insecure-requests заставляет браузер волшебным образом переделать все HTTP-запросы в HTTPS-запросы.
Однако CSP касается не только используемого протокола. Он предлагает детальные способы определения того, какие ресурсы и действия разрешены на вашем сайте. Вы можете, например, указать, какие скрипты должны выполняться или откуда загружать изображения. Если что-то не разрешено, браузер блокирует это действие и предотвращает потенциальные атаки на ваш сайт.
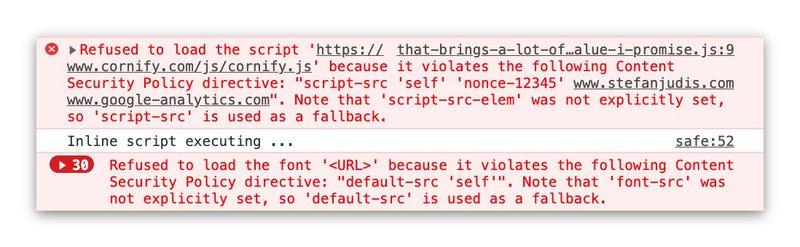
На момент написания статьи для CSP существовало 24 различных варианта конфигурации. Они варьируются от скриптов через таблицы стилей вплоть до сервис-воркеров.

Вы можете найти полный обзор на MDN.
Используя CSP, вы можете указать, что должен включать ваш сайт, а что нет.
Content-Security-Policy: default-src 'self'; script-src 'self' just-comments.com www.google-analytics.com production-assets.codepen.io storage.googleapis.com; style-src 'self' 'unsafe-inline'; img-src 'self' data: images.contentful.com images.ctfassets.net www.gravatar.com www.google-analytics.com just-comments.com; font-src 'self' data:; connect-src 'self' cdn.contentful.com images.contentful.com videos.contentful.com images.ctfassets.net videos.ctfassets.net service.just-comments.com www.google-analytics.com; media-src 'self' videos.contentful.com videos.ctfassets.net; object-src 'self'; frame-src codepen.io; frame-ancestors 'self'; worker-src 'self'; block-all-mixed-content; manifest-src 'self' 'self'; disown-opener; prefetch-src 'self'Вышеприведенный набор правил предназначен для моего личного сайта, и если вы считаете, что этот пример определения CSP очень сложный, то вы абсолютно правы. Я внедрил у себя этот набор с третьей попытки, развёртывая и снова откатывая, потому что он несколько раз ломал сайт. Но есть способ получше.
Чтобы избежать взлома вашего сайта, CSP также предоставляет режим только для отчетов.
Content-Security-Policy-Report-Only: default-src 'self'; . report-uri https://stefanjudis.report-uri.com/r/d/csp/reportOnlyИспользуя режим Content-Security-Policy-Report-Only , браузеры просто записывают ресурсы, которые были бы заблокированы, вместо их фактической блокировки. Этот механизм отчетности позволяет проверить и настроить ваш набор правил.
Оба заголовка, Content-Security-Policy и Content-Security-Policy-Report-Only , также предлагают способ определения конечной точки для отправки сообщения о нарушении и регистрации информации ( report-uri ). Вы можете настроить сервер регистрации и использовать отправленную информацию журнала для настройки правил CSP, пока он не будет готов к отправке.
Рекомендуемый процесс выглядит так: сначала запустите CSP в режиме отчета, проанализируйте входящие нарушения с реальным трафиком, и только тогда, когда не будет обнаружено нарушений ваших контролируемых ресурсов, включите его.
Если вы ищете сервис, который мог бы помочь вам справиться с этими журналами, то рекомендую Report URI, он мне очень помогает.
Общее внедрение CSP
Сегодня браузеры хорошо поддерживают CSP, но, к сожалению, не многие сайты используют её. Чтобы посмотреть, сколько сайтов отдают контент с помощью CSP, я направил запрос в HTTParchive и обнаружил, что только 6 % просмотренных сайтов используют эту политику. Я думаю, что мы можем сделать интернет более безопасным и защитить наших пользователей от невольного майнинга криптовалют.

Сеть должна быть доступной
Пока я пишу эту статью, я сижу перед относительно новым MacBook, используя быстрое домашнее Wi-Fi-подключение. Разработчики часто забывают, что такая ситуация не является стандартной для большинства наших пользователей. Люди, посещающие наши сайты, пользуются старыми телефонами и сомнительными соединениями. Тяжелые и перегруженные сайты с сотнями запросов оставляют им плохое впечатление.
И дело не только во впечатлении. Люди платят различные суммы за трафик в зависимости от места проживания. Представьте себе, вы создаете сайт для больницы. Информация на нём может иметь решающее значение и спасти жизни людей. Если страница на сайте больницы имеет размер 5 Мб, то она не только будет медленно работать, но и может оказаться слишком дорогой для тех, кто больше всего в ней нуждается. Цена пяти мегабайтов трафика в Европе или США ничтожна по сравнению с ценой в Африке. Разработчики несут ответственность за доступность веб-страниц для всех. Эта ответственность включает в себя предоставление правильных ресурсов, выбор правильных инструментов (действительно ли вам нужен JS-фреймворк для лендинга?) и недопущение запросов.
Cache-Control — избегайте запросов на неизменные ресурсы
Сегодня сайт может содержать сотни ресурсов, от CSS до скриптов и изображений. Используя заголовок Cache-Control , разработчики могут указать, как долго ресурс должен считаться «свежим» и может отдавать из кэша браузера.
Cache-Control: max-age=30, publicПри правильной настройке Cache-Control передача данных сохраняется, и файлы могут использоваться из кэша браузера в течение определенного количества секунд ( max-age ). Браузеры должны повторно проверять кэшированные ресурсы по истечении этого периода времени.
Однако, если посетители обновляют страницу, браузеры всё равно повторно проверяют её, включая ссылки на ресурсы, чтобы убедиться, что кэшированные данные всё ещё действительны. Серверы отвечают заголовком 304, сигнализируя, что кэшированные данные пока действительны, или заголовком 200 при передаче обновленных данных. Это позволяет сохранить переданные данные, но не обязательно сделанные запросы.
Именно здесь вступает в игру функция immutable .
Immutable — никогда не запрашивать ресурс дважды
В современных frontend-приложениях файлы CSS и скриптов обычно имеют уникальные имена, например, styles.123abc.css . Имя этого файла зависит от содержимого. И при изменении содержимого файлов меняются и их имена.
Эти уникальные файлы потенциально могут храниться в кэше вечно, включая ситуацию, когда пользователь обновляет страницу. Функция immutable может запретить браузеру повторную проверку ресурса в определенный промежуток времени. Это очень важно для объектов с контрольными суммами, и помогает избежать повторных проверочных запросов.
Cache-Control: max-age=31536000, public, immutableРеализовать оптимальное кэширование очень сложно, а особенно браузерное кэширование не слишком интуитивно понятно, поскольку имеет различные конфигурации. Я рекомендую ознакомиться со следующими материалами:
- Гарри Робертс написал отличное руководство по управлению кэшем и его настройкам.
- Джек Арчибальд дал советы по лучшим методикам кэширования с иллюстрациями.
- Илья Григорик предложил отличную технологическую схему для кэширования заголовков.
Accept-Encoding — максимальное сжатие (до минимума)
С помощью Cache control мы можем сохранять запросы и уменьшать объем данных, которые многократно передаются по сети. Мы можем не только экономить запросы, но и сокращать то, что передается.
Отдавая ресурсы, разработчики должны позаботиться о том, чтобы отправлять как можно меньше данных. Для текстовых ресурсов, таких как HTML, CSS и JavaScript, сжатие играет важную роль в экономии передаваемых данных.
Самым популярным методом сжатия сегодня является GZIP. Серверам хватает мощности для сжатия текстовых файлов на лету и предоставления сжатых данных при запросе. Но GZIP уже не самый лучший вариант.
Если вы взглянете на создаваемые браузером запросы текстовых файлов, таких как HTML, CSS и JavaScript, и проанализируете заголовки, то найдете среди них accept-encoding .
Accept-Encoding: gzip, deflate, brЭтот заголовок сообщает серверу, какие алгоритмы сжатия он понимает. Малоизвестный параметр br обозначает сжатие Brotli и используется на сайтах с высокой посещаемостью, таких как Google и Facebook. Для использования Brotli ваш сайт должен работать через HTTPS.
Этот алгоритм сжатия был создан с учетом небольшого размера файлов. Если вы попробуете сжать файл вручную на вашем локальном устройстве, то обнаружите, что Brotli действительно сжимает лучше, чем GZIP.
Вы, возможно, слышали, что сжатие Brotli выполняется медленнее. Причина в том, что Brotli имеет 11 режимов сжатия, и по умолчанию выбирается тот, при котором получаются файлы наименьшего размера, что удлиняет процедуру. GZIP, с другой стороны, имеет 9 режимов, и по умолчанию выбирается тот, при котором учитывается как скорость сжатия, так и размера файла. В результате режим Brotli по умолчанию непригоден для сжатия «на лету», но если изменить режим, то можно добиться сжатия небольших файлов с той же скоростью, что и у GZIP. Вы можете использовать его для сжатия на лету и рассматривать как потенциальную замену GZIP для поддерживающих браузеров.
Кроме того, если вы хотите максимально экономить файлы, то можете забыть о динамическом сжатии и предварительно сгенерировать оптимизированные GZIP-файлы с помощью файлов zopfli и Brotli для их статического обслуживания.
Если вы хотите прочитать больше о сжатии Brotli и его сравнении с GZIP, сотрудники компании Akamai провели обширное исследование на эту тему.
Accept и Accept-CH — обслуживайте индивидуальные ресурсы для пользователя
Оптимизация текстовых ресурсов очень важна для экономии килобайтов, но как насчёт более тяжелых ресурсов, таких как изображения, чтобы сэкономить ещё больше объёма данных?
Accept — обслуживание изображений правильного формата
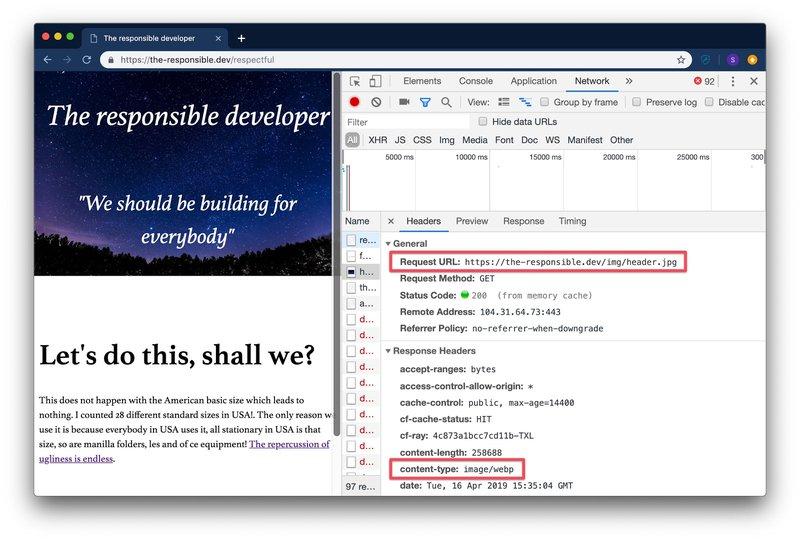
Браузеры не только показывают нам, какие алгоритмы сжатия они понимают. Когда браузер запрашивает изображение, он также предоставляет информацию о том, какие форматы файлов он понимает.
Accept: image/webp, image/apng, image/*,*/*;q=0.8Несколько лет велась борьба вокруг нового формата изображений, но выиграл webp. Webp — это формат изображений, изобретенный Google, и поддержка этого формата сейчас очень актуальна.
Используя этот заголовок запроса, разработчики могут передавать изображение webp , даже если браузер запросил image.jpg , в результате чего размер файла будет меньше. Дин Хьюм написал хорошее руководство о том, как это применять. Очень круто!
Accept-CH — обслуживание изображений правильного размера
Вы также можете включить клиентские подсказки для поддерживающих эту функцию браузеров. Клиентские подсказки — это способ сказать браузерам, чтобы они посылали дополнительную информацию о ширине области просмотра, ширине изображения и даже сетевых условиях, таких как RTT (время на передачу и подтверждение) и типе соединения, например 2g .
Вы можете активировать подсказки, добавив мета-элемент:
Или задав заголовки в исходном запросе HTML:
Accept-CH: Width, Viewport-Width Accept-CH-Lifetime: 100В последующих запросах браузеры начнут посылать дополнительную информацию за определенный промежуток времени ( Accept-CH-Lifetime в секундах), что может помочь разработчикам адаптировать изображения к условиям пользователя, не меняя HTML.
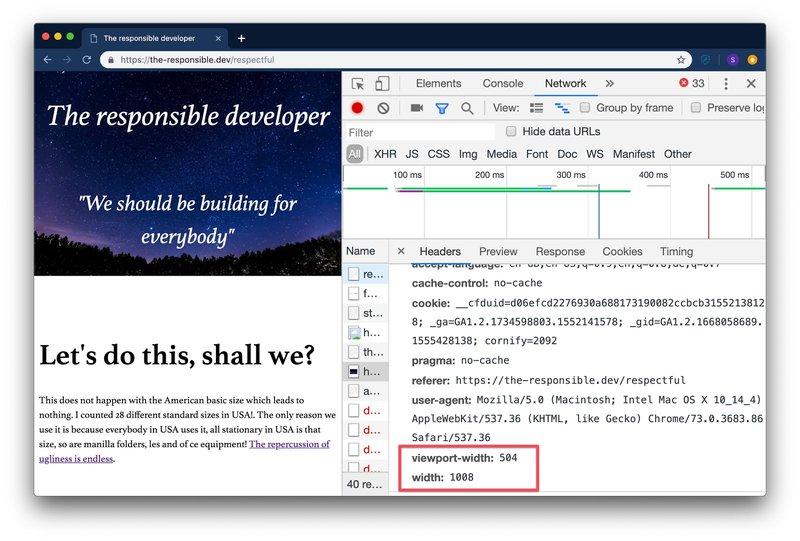
Например, для получения дополнительной информации, такой как ширина изображения на стороне сервера, вы можете снабдить свои изображения атрибутом sizes , чтобы дать браузеру дополнительную информацию о том, как эти изображения будут выглядеть.

С полученным заголовком ответа Accept-CH и изображениями с атрибутом sizes браузеры будут включать заголовки viewport-width и width в запросы изображений, показывая вам, какое изображение подойдёт лучше всего.
Имея поддерживаемый формат и размеры изображения, вы можете отправлять адаптированные данные без необходимости записывать ненадежные элементы изображений и обращать внимание только на формат и размер файлов, как показано ниже.

Если у вас есть доступ к ширине области просмотра (viewport) и размеру изображений, вы можете на своих серверах поставить логику изменения размера ресурсов во главу угла.
Однако нужно учитывать, что не следует создавать изображения для любой ширины просто потому, что у вас есть точная ширина изображения. Отправка изображений для определенного диапазона размеров ( image-200 , image-300 , . ) помогает использовать CDN-кэширование и экономит время вычислений.
Кроме того, с такими современными технологиями, как service worker’ы, вы даже можете перехватывать и изменять запросы прямо в клиенте, чтобы обслуживать лучшие файлы изображений. С включенными клиентскими подсказками service worker’ы получают доступ к информации о макетах, и в сочетании с API изображений, как, например, Cloudinary, вы можете настроить url изображения прямо в браузере для получения картинок надлежащего размера.
Если вы ищете более подробную информацию о клиентских подсказках, можете ознакомиться со статьями Джереми Вагнера или Ильи Григорика на эту тему.
Сеть должна быть бережной
Поскольку каждый из нас проводит в сети много часов в день, есть последний аспект, который я считаю очень важным — сеть должна быть бережной.
Preload — сокращение времени ожидания
Будучи разработчиками, мы ценим время наших пользователей. Никто не хочет терять время. Как уже говорилось в предыдущих главах, предоставление нужных данных играет большую роль в экономии времени и трафика. Речь идёт не только о том, какие запросы делаются, но и о сроках и порядке их выполнения.
Приведу пример: если вы добавите на сайт таблицу стилей, браузеры не будут ничего показывать, пока она не загрузится. Пока на экране ничего не отображается, браузер продолжает анализировать HTML в поисках других ресурсов для запрашивания. После загрузки и парсинга таблицы стилей в ней могут оказаться ссылки на другие важные ресурсы, такие как шрифты, которые тоже могут быть запрошены. Этот процесс может увеличить время загрузки страницы для ваших посетителей.
Используя Rel=preload вы можете дать браузеру информацию о том, какие ресурсы будут запрошены в ближайшее время.
Можете предварительно загрузить ресурсы через HTML-элементы:
Link: ; rel=preload; as=font; no-pushТаким образом, браузер получает заголовок или находит элемент ссылки, и немедленно запрашивает ресурсы, чтобы они уже находились в кэше, когда понадобятся. Этот процесс экономит время ваших посетителей.
Для оптимальной предварительной загрузки ресурсов и понимания всех конфигураций я рекомендую обратить внимание на следующие материалы:
- Йоав Вайс является экспертом по предварительной загрузке, он опубликовал прекрасный материал по этой теме.
- Эдди Османи подробно рассказал о preload и других инструментах, таких как prefetch и preconnect.
Feature-Policy — не раздражайте других
Меньше всего я хочу видеть сайты, запрашивающие у меня разрешения без причины. Я могу лишь процитировать своего коллегу Фила Нэша по этому поводу.
Не требуйте разрешение при загрузке страницы. Разработчики должны относиться с уважением и не создавать сайты, раздражающие посетителей. Люди просто кликают на все окна с разрешениями. Если мы не используем их правильно, то сайты и разработчики теряют доверие, а новые блестящие функции — свою привлекательность.
Но что, если ваш сайт обязательно должен включать много стороннего кода, и все эти скрипты запускают множество диалоговых окон с разрешением? Как убедиться, что все включённые скрипты ведут себя правильно?
Именно здесь в игру вступает заголовок Feature-Policy. С его помощью вы можете указать, какие функции разрешены, и ограничить всплывающие диалоговые окна с разрешениями, которые могут быть вызваны сторонним кодом, исполняемым на вашем сайте.
Feature-Policy: vibrate 'none'; geolocation 'none'Вы можете настроить это поведение для сайта с помощью заголовка. Также можно задать этот заголовок для встроенного контента, например, плавающих фреймов, которые могут быть обязательными для интеграции со сторонними разработчиками.
На момент написания статьи заголовок Feature-Policy был, скорее, экспериментальным, но интересно посмотреть на его будущие возможности. В недалеком будущем разработчики смогут не только ограничивать себя и не допускать появления раздражающих диалоговых окон, но также блокировать неоптимизированные данные. Эти функции существенно улучшат работу пользователей.

Вы можете найти полный обзор на MDN.
Глядя на список выше, вы можете вспомнить о самом раздражающем моменте — push-уведомлениях. Оказалось, что применение Feature-Policy для push-уведомлений сложнее, чем ожидалось. Если вы хотите узнать больше, можете подписаться на соответствующую тему на GitHub.
Благодаря feature policy можете быть уверены, что вы и сторонние ресурсы не превратите ваш сайт в гонку за разрешениями, которая, к сожалению, уже стала привычной для многих сайтов.
Сеть должна быть для всех
В этой статье я рассказал лишь о нескольких заголовках, которые могут помочь улучшить работу пользователей. Если хотите увидеть почти полный обзор заголовков и их возможностей, я рекомендую посмотреть презентацию Кристиана Шефера «HTTP-заголовки — скрытые чемпионы».
Я знаю, что создание отличного сайта сегодня — очень сложная задача. Разработчики должны учитывать дизайн, устройства, фреймворки, и да… заголовки тоже играют определённую роль. Надеюсь, эта статья даст вам некоторые идеи, и вы будете учитывать безопасность, доступность и уважительность в ваших следующих веб-проектах, потому что это именно те факторы, которые делают сеть по-настоящему отличным местом для всех.
- http
- http-заголовки
- никто не читает теги
- Блог компании VK
- Высокая производительность
- Веб-разработка
- Клиентская оптимизация
- HTML