Как работать в Visual Prolog
Заказать решение задачи на Prolog можно тут Цель работы: ознакомление с основами среды логического программирования Visual Prolog.
Установка Visual Prolog
Скачать Visual Prolog 5.2.
32-х разрядная версия Visual Prolog 5.2 для Windows была установлена на 64х разрядный компьютер с операционной системой OpenSUSE 42.1, при этом использовался Wine 1.8.4. Процесс установки ничем не отличается от установки под Windows, при клике по установщику автоматически запускается Wine и процесс установки продолжается в обычном режиме.
Создание проекта в Visual Prolog
После установки системы, запускаем Visual Prolog и создаем проект. В появившемся окне вводим имя проекта и путь к нему.
 Затем нужно перейти во вкладку Target и выбрать консольный режим (Textmode), т. к. наше приложение будет консольным:
Затем нужно перейти во вкладку Target и выбрать консольный режим (Textmode), т. к. наше приложение будет консольным:
 Нажимает кнопку Create, после этого будет открыто рабочее окно системы, в левой части которого отобразится структура проекта. Проект содержит файл parents.pro с исходным кодом.
Нажимает кнопку Create, после этого будет открыто рабочее окно системы, в левой части которого отобразится структура проекта. Проект содержит файл parents.pro с исходным кодом.

Разработка программы в Visual Prolog
В качестве примера, разработаем программу, содержащую базу данных родственных отношений и попробуем использовать различные запросы (цели для вычисления). Открываем файл parents.pro, приступаем к написанию исходного кода. Нам требуется создать базу родственных отношений между именами. Опишем тип имени в секции domains:
domains name = symbol
В данном случае записано, что name является эквивалентом типа данных symbol. В свою очередь symbol — это символьный тип данных, элементами которого могут являться как строки (например, « Ilia », « Elena »), заключенные в кавычки, так и любые идентификаторы, начинающиеся со строчной буквы (например marina , ira и т. п.). Опишем отношение базы данных, задающее родство двух имен:
database parent(name, name)
Теперь можно добавлять элементы во внутреннюю базу данных. Сделать это можно в секции clauses:
clauses parent(ilia, marina). parent(marina, ira). parent(elena, ivan). parent(nikolay, ira). parent(olga, aleksei). parent(marina, sasha). parent(sergei, ivan).
Первый запрос, который мы реализуем, должен проверять, что “Марина является родителем Саши”. Запросы описываются в секции goal:
 Для запуска цели нажимает комбинацию Ctrl+g, программа запускается и начинает свое выполнение с секции goal. В появившемся окне можем наблюдать результат работы программы. Выводится yes , т. к. утверждение является верным для описанных в базе фактов:
Для запуска цели нажимает комбинацию Ctrl+g, программа запускается и начинает свое выполнение с секции goal. В появившемся окне можем наблюдать результат работы программы. Выводится yes , т. к. утверждение является верным для описанных в базе фактов:
 Следующее утверждение, которое проверим “Алексей является родителем Ольги” – ложно, т. к. в базе нет факта parent(aleksei, olga) . Запишем этот запрос в секции goal и убедимся, что результат — no:
Следующее утверждение, которое проверим “Алексей является родителем Ольги” – ложно, т. к. в базе нет факта parent(aleksei, olga) . Запишем этот запрос в секции goal и убедимся, что результат — no: 
В запросе «Кто является ребенком Николая» нужно использовать анонимную переменную (ее имя начинается с большой буквы), т. к. имя ребенка неизвестно. Интерпретатор попробует подобрать все возможные решения, сопоставив эту переменную с каждым значением базы данных. В результате он сообщит нам, что ребенок Николая — Ира:
 Несмотря на то, что пролог в предыдущем запросе перебирал все возможные варианты, был получен только один ответ, т. к. у Николая других детей нет. Однако, в запросе «Кто родители Ивана» мы получим несколько решений:
Несмотря на то, что пролог в предыдущем запросе перебирал все возможные варианты, был получен только один ответ, т. к. у Николая других детей нет. Однако, в запросе «Кто родители Ивана» мы получим несколько решений:
 При определении всех родителей и их детей мы используем две анонимных переменных в запросе (т. к. ни конкретные родители, ни дети нам заранее не известны). В результате будет выведено все содержимое нашей базы данных:
При определении всех родителей и их детей мы используем две анонимных переменных в запросе (т. к. ни конкретные родители, ни дети нам заранее не известны). В результате будет выведено все содержимое нашей базы данных:
 Более подробно про работу с базами данных в Prolog.
Более подробно про работу с базами данных в Prolog.
Выводы по работе в Visual Prolog:
1. получены навыки работы в среде Visual Prolog 5.2;
2. на примерах исследован механизм поиска с возвратами. В рассмотренных нами примерах видно, что интерпретатор пролога выполняет поиск всех решений, при этом последний пример показывает, что данные базы данных обрабатываются в том порядке, в котором они были описаны в коде. Мы можем задавать в программе различные цели, соответствующие нашим требованиям, при этом будет выполняться поиск в базе и выдаче результатов подобно тому, как это происходит в реляционных базах данных.
Основы Пролога. Часть 1
В этом руководстве по языку Prolog мы ознакомимся с фундаментальными идеями языка программирования Prolog.
Язык системы программирования Visual Prolog является объектно-ориентированным, строго типизированным и с контролируемым режимов предикатов. Естественно, это все необходимо освоить для написания программ в системе Visual Prolog. Однако, в этом руководстве мы сосредоточимся на ядре программных текстов, то есть на текстах Пролога безотносительно классов, типов и режимов.
С этой целью мы будем использовать пример приложения PIE (Prolog Inference Engine — Машина Вывода Пролога), который включен в комплект системы программирования Visual Prolog. PIE можно также сгрузить в виде исполняемого приложения с сайта. PIE является «классическим» интерпретатором, используя который можно изучать и экспериментировать с Прологом безо всего, что касается классов, типов и т.д.
- 1 Логика Хороновских клаузов
- 2 PIE: Prolog Inference Engine
- 3 Extending the family theory
- 4 Prolog is a Programming Language
- 5 Program Control
- 6 Failing
- 7 Backtracking
- 8 Improving the Family Theory
- 9 Recursion
- 10 Side Effects
- 11 Conclusion
- 12 See also
- 13 Ссылки
Логика Хороновских клаузов
Visual Prolog, как и другие диалекты языка Пролог, базируется на логике хороновских клаузов. Логика Хорновских Клаузов является формальной системой для заключений относительно сущностей и для установления отношений между ними.
В естественном языка мы можем сформулировать предложение вроде:
John is the father of Bill. (Джон является отцом Билла)
Здесь мы имеем две сущности: Джон (John) и Билл (Bill). Кроме того мы здесь имеем отношение между ними, а именно то, что один является отцом другому. В логике хорновских клаузов мы пожем формализовать это утверждение следующим образом:
father("Bill", "John"). или отец("Билл","Джон").
father (отец) является предикатом или отношением с двумя аргументами, где второй является отцом первого.
Заметьте что мы выбрали так, что именно второй человек является отцом первого.
Мы могли бы выбрать и другой способ, поскольку порядок аргументов является прерогативой разработчика формальной системы.
Однако, сделав однажды выбор, следует в дальнейшем его придерживаться.
Итак в нашей формализации отец всегда должен быть вторым.
I have chosen to represent the persons by their names (which are string literals). In a more complex world this would not be sufficient because many people have same name. But for now we will be content with this simple formalization.
With formalizations like the one above I can state any kind of family relation between any persons. But for this to become really interesting I will also have to formalize rules like this:
X is the grandfather of Z, if X is the father of Y and Y is the father of Z
where X, Y and Z are persons. In Horn Clause Logic I can formalize this rule like this:
grandFather(Person, GrandFather) :- father(Person, Father), father(Father, GrandFather).
I have chosen to use variable names that help understanding better than X, Y and Z. I have also introduced a predicate for the grandfather relation. Again I have chosen that the grandfather should be the second argument. It is wise to be consistent like that, i.e. that the arguments of the different predicates follow some common principle. When reading rules you should interpret :- as if and the comma that separates the relations as and.
Statements like «John is the father of Bill» are called facts, while statements like «X is the grandfather of Z, if X is the father of Y and Y is the father of Z» are called rules.
With facts and rules we are ready to formulate theories. A theory is a collection of facts and rules. Let me state a little theory:
father("Bill", "John"). father("Pam", "Bill"). grandFather(Person, GrandFather) :- father(Person, Father), father(Father, GrandFather).
The purpose of the theory is to answer questions like these:
Is John the father of Sue? Who is the father of Pam? Is John the grandfather of Pam? .
Such questions are called goals. And they can be formalized like this (respectively):
?- father("Sue", "John"). ?- father("Pam", X). ?- grandFather("Pam", "John").
Such questions are called goal clauses or simply goals. Together facts, rules and goals are called Horn clauses, hence the name Horn Clause Logic.
Some goals like the first and last are answered with a simple yes or no. For other goals like the second we seek a solution, like X = «Bill».
Some goals may even have many solutions. For example:
?- father(X, Y).
has two solutions:
X = "Bill", Y = "John". X = "Pam", Y = "Bill".
A Prolog program is a theory and a goal. When the program starts it tries to find a solution to the goal in the theory.
PIE: Prolog Inference Engine
Now we will try the little example above in PIE, the Prolog Inference Engine that comes with Visual Prolog. You can also download it from the web.
Before we start you should install and build the PIE example.
When the program starts it will look like this:

Select File -> New and enter the father and grandFather clauses above:

While the editor window is active choose Engine -> Reconsult. This will load the file into the engine. In the Dialog window you should receive a message like this:
Reconsulted from: . \pie\Exe\FILE4.PRO
Reconsult loads whatever is in the editor, without saving the contents to the file, if you want to save the contents use File -> Save.
File -> Consult will load the disc contents of the file regardless of whether the file is opened for editing or not.
Once you have «consulted» the theory, you can use it to answer goals.
On a blank line in the Dialog window type a goal (without the ?- in front).

When the caret is placed at the end of the line, press the Enter key on your keyboard. PIE will now consider the text from the beginning of the line to the caret as a goal to execute. You should see a result like this:

Extending the family theory
It is straight forward to extend the family theory above with predicates like mother and grandMother. You should try that yourself. You should also add more persons. I suggest that you use persons from your own family, because that makes it lot easier to validate, whether some person is indeed the grandMother of some other person, etc.
Given mother and father we can also define a parent predicate. You are a parent if you are a mother; you are also a parent if you are a father. Therefore we can define parent using two clauses like this:
parent(Person, Parent) :- mother(Person, Parent). parent(Person, Parent) :- father(Person, Parent).
The first rule reads (recall that the second argument corresponds to the predicate name):
Parent is the parent of Person, if Parent is the mother of Person
You can also define the parent relation using semicolon «;» which means or, like this:
parent(Person, Parent) :- mother(Person, Parent); father(Person, Parent).
This rule reads:
Parent is the parent of Person, if Parent is the mother of Person or Parent is the father of Person
I will however advise you to use semicolon as little as possible (or actually not at all). There are several reasons for this:
- The typographical difference «,» and «;» is very small, but the semantic difference is rather big. «;» is often a source of confusion, since it is easily misinterpreted as «,», especially when it is on the end of a long line.
- Visual Prolog only allows to use semicolon on the outermost level (PIE will allow arbitrarily deep nesting).
Try creating a sibling predicate! Did that give problems?
You might find that siblings are found twice. At least if you say: Two persons are siblings if they have same mother, two persons are also siblings if they have same father. I.e. if you have rules like this:
sibling(Person, Sibling) :- mother(Person, Mother), mother(Sibling, Mother). sibling(Person, Sibling) :- father(Person, Father), father(Sibling, Father).
The first rule reads:
Sibling is the sibling of Person, if Mother is the mother of Person and Mother is the mother of Sibling
The reason that you receive siblings twice is that most siblings both have same father and mother, and therefore they fulfill both requirements above. And therefore they are found twice.
We shall not deal with this problem now; currently we will just accept that some rules give too many results.
A fullBlodedSibling predicate does not have the same problem, because it will require that both the father and the mother are the same:
fullBlodedSibling(Person, Sibling) :- mother(Person, Mother), mother(Sibling, Mother), father(Person, Father), father(Sibling, Father).
Prolog is a Programming Language
From the description so far you might think that Prolog is an expert system, rather than a programming language. And indeed Prolog can be used as an expert system, but it is designed to be a programming language.
We miss two important ingredients to turn Horn Clause logic into a programming language:
- Rigid search order/program control
- Side effects
Program Control
When you try to find a solution to a goal like:
?- father(X, Y).
You can do it in many ways. For example, you might just consider at the second fact in the theory and then you have a solution.
But Prolog does not use a «random» search strategy, instead it always use the same strategy. The system maintains a current goal, which is always solved from left to right.
I.e. if the current goal is:
?- grandFather(X, Y), mother(Y, Z).
Then the system will always try to solve the sub-goal grandFather(X, Y) before it solves mother(Y, Z), if the first (i.e. left-most) sub-goal cannot be solved then there is no solution to the overall problem and then the second sub-goal is not tried at all.
When solving a particular sub-goal, the facts and rules are always tried from top to bottom.
When a sub-goal is solved by using a rule, the right hand side replaces the sub-goal in the current goal.
I.e. if the current goal is:
?- grandFather(X, Y), mother(Y, Z).
And we are using the rule
grandFather(Person, GrandFather) :- father(Person, Father), father(Father, GrandFather).
to solve the first sub-goal, then the resulting current goal will be:
?- father(X, Father), father(Father, Y), mother(Y, Z).
Notice that some variables in the rule have been replaced by variables from the sub-goal. I will explain this in details later.
Given this evaluation strategy you can interpret clauses much more procedural. Consider this rule:
grandFather(Person, GrandFather) :- father(Person, Father), father(Father, GrandFather).
Given the strict evaluation we can read this rule like this:
To solve grandFather(Person, GrandFather) first solve father(Person, Father) and then solve father(Father, GrandFather).
Or even like this:
When grandFather(Person, GrandFather) is called, first call father(Person, Father) and then call father(Father, GrandFather).
With this procedural reading you can see that predicates correspond to procedures/subroutines in other languages. The main difference is that a Prolog predicate can return several solutions to a single invocation or even fail. This will be discussed in details in the next sections.
Failing
A predicate invocation might not have any solution in the theory. For example calling parent(«Hans», X) has no solution as there are no parent facts or rules that applies to «Hans». We say that the predicate call fails. If the goal fails then there is simply no solution to the goal in the theory. The next section will explain how failing is treated in the general case, i.e. when it is not the goal that fails.
Backtracking
In the procedural interpretation of a Prolog program «or» is treated in a rather special way. Consider the clause
parent(Person, Parent) :- mother(Person, Parent); father(Person, Parent).
In the logical reading we interpreted this clause as:
Parent is the parent of Person if Parent is the mother of Person or Parent is the father of Person.
The «or» introduces two possible solutions to an invocation of the parent predicate. Prolog handles such multiple choices by first trying one choice and later (if necessary) backtracking to the next alternative choice, etc.
During the execution of a program a lot of alternative choices (known as backtrack points) might exist from earlier predicate calls. If some predicate call fails, then we will backtrack to the last backtrack point we met and try the alternative solution instead. If no further backtrack points exists then the overall goal has failed, meaning that there was no solution to it.
With this in mind we can interpret the clause above like this:
When parent(Person, Parent) is called first record a backtrack point to the second alternative solution (i.e. to the call to father(Person, Parent)) and then call mother(Person, Parent)
A predicate that has several classes behave in a similar fashion. Consider the clauses:
father("Bill", "John"). father("Pam", "Bill").
When father is invoked we first record a backtrack point to the second clause, and then try the first clause.
If there are three or more choices we still only create one backtrack point, but that backtrack point will start by creating another backtrack point. Consider the clauses:
father("Bill", "John"). father("Pam", "Bill"). father("Jack", "Bill").
When father is invoked, we first record a backtrack point. And then we try the first clause. The backtrack point we create points to some code, which will itself create a backtrack point (namely to the third clause) and then try the second clause. Thus all choice points have only two choices, but one choice might itself involve a choice.
Example To illustrate how programs are executed I will go through an example in details. Consider these clauses:
mother("Bill", "Lisa"). father("Bill", "John"). father("Pam", "Bill"). father("Jack", "Bill"). parent(Person, Parent) :- mother(Person, Parent); father(Person, Parent).
And then consider this goal:
?- father(AA, BB), parent(BB, CC).
This goal states that we want to find three persons AA, BB and CC, such that BB is the father of AA and CC is a parent of BB.
As mentioned we always solve the goals from left to right, so first we call the father predicate. When executing the father predicate we first create a backtrack point to the second clause, and then use the first clause.
Using the first clause we find that AA is «Bill» and BB is «John». So we now effectively have the goal:
?- parent("John", CC).
So we call parent, which gives the following goal:
?- mother("John", CC); father("John", CC).
You will notice that the variables in the clause have been replaced with the actual parameters of the call (exactly like when you call subroutines in other languages).
The current goal is an «or» goal, so we create a backtrack point to the second alternative and pursuit the first. We now have two active backtrack points, one to the second alternative in the parent clause, and one to the second clause in the father predicate.
After the creation of this backtrack point we are left with the following goal:
?- mother("John", CC).
So we call the mother predicate. The mother predicate fails when the first argument is «John» (because it has no clauses that match this value in the first argument).
In case of failure we backtrack to the last backtrack point we created. So we will now pursuit the goal:
?- father("John", CC).
When calling father this time, we will again first create a backtrack point to the second father clause.
Recall that we also still have a backtrack point to the second clause of the father predicate, which corresponds to the first call in the original goal.
We now try to use the first father clause on the goal, but that fails, because the first arguments do not match (i.e. «John» does not match «Bill»).
Therefore we backtrack to the second clause, but before we use this clause we create a backtrack point to the third clause.
The second clause also fails, since «John» does not match «Pam», so we backtrack to the third clause. This also fails, since «John» does not match «Jack».
Now we must backtrack all the way back to the first father call in the original goal; here we created a backtrack point to the second father clause.
Using the second clause we find that AA is «Pam» and BB is «Bill». So we now effectively have the goal:
?- parent("Bill", CC).
When calling parent we now get:
?- mother("Bill", CC); father("Bill", CC).
Again we create a backtrack point to the second alternative and pursuit the first:
?- mother("Bill", CC).
This goal succeeds with CC being «Lisa». So now we have found a solution to the goal:
AA = "Pam", BB = "Bill", CC = "Lisa".
When trying to find additional solutions we backtrack to the last backtrack point, which was the second alternative in the parent predicate:
?- father("Bill", CC).
This goal will also succeed with CC being «John». So now we have found one more solution to the goal:
AA = "Pam", BB = "Bill", CC = "John".
If we try to find more solutions we will find:
AA = "Jack", BB = "Bill", CC = "John". AA = "Jack", BB = "Bill", CC = "Lisa".
After that we will experience that everything will eventually fail leaving no more backtrack points. So all in all there are four solutions to the goal.
Improving the Family Theory
If you continue to work with the family relation above, you will probably find out that you have problems with relations like brother and sister, because it is rather difficult to determine the sex of a person (unless the person is a father or mother).
The problem is that we have chosen a bad way to formalize our theory.
The reason that we arrived at this theory is because we started by considering the relations between the entities. If we instead first focus on the entities, then the result will naturally become different.
Our main entities are persons. Persons have a name (in this simple context will still assume that the name identifies the person, in a real scale program this would not be true). Persons also have a sex. Persons have many other properties, but none of them have any interest in our context.
Therefore we define a person predicate, like this:
person("Bill", "male"). person("John", "male"). person("Pam", "female").
The first argument of the person predicate is the name and the second is the sex.
Instead of using mother and father as facts, I will choose to have parent as facts and mother and father as rules:
parent("Bill", "John"). parent("Pam", "Bill"). father(Person, Father) :- parent(Person, Father), person(Father, "male").
Notice that when father is a «derived» relation like this, it is impossible to state female fathers. So this theory also has a built-in consistency on this point, which did not exist in the other formulation.
Recursion
Most family relations are easy to construct given the principles above. But when it comes to «infinite» relations like ancestor we need something more. If we follow the principle above, we should define ancestor like this:
ancestor(Person, Ancestor) :- parent(Person, Ancestor). ancestor(Person, Ancestor) :- parent(Person, P1), parent(P1, Ancestor). ancestor(Person, Ancestor) :- parent(Person, P1), parent(P1, P2), parent(P2, Ancestor). .
The main problem is that this line of clauses never ends. The way to overcome this problem is to use a recursive definition, i.e. a definition that is defined in terms of itself. like this:
ancestor(Person, Ancestor) :- parent(Person, Ancestor). ancestor(Person, Ancestor) :- parent(Person, P1), ancestor(P1, Ancestor).
This declaration states that a parent is an ancestor, and that an ancestor to a parent is also an ancestor.
If you are not already familiar with recursion you might find it tricky (in several senses). Recursion is however fundamental to Prolog programming. You will use it again and again, so eventually you will find it completely natural.
Let us try to execute an ancestor goal:
?- ancestor("Pam", AA).
We create a backtrack point to the second ancestor clause, and then we use the first, finding the new goal:
?- parent("Pam", AA).
This succeeds with the solution:
AA = "Bill".
Then we try to find another solution by using our backtrack point to the second ancestor clause. This gives the new goal:
?- parent("Pam", P1), ancestor(P1, AA).
Again «Bill» is the parent of «Pam», so we find P1= «Bill», and then we have the goal:
?- ancestor("Bill", AA).
To solve this goal we first create a backtrack point to the second ancestor clause and then we use the first one. This gives the following goal:
?- parent("Bill", AA).
This goal has the gives the solution:
AA = "John".
So now we have found two ancestors of «Pam»:
If we use the backtrack point to the second ancestor clause we get the following goal:
?- parent("Bill", P1), ancestor(P1, AA).
Here we will again find that «John» is the parent of «Bill», and thus that P1 is «John». This gives the goal:
?- ancestor("John", AA).
If you pursuit this goal you will find that it will not have any solution. So all in all we can only find two ancestors of «Pam».
Recursion is very powerful but it can also be a bit hard to control. Two things are important to remember:
- the recursion must make progress
- the recursion must terminate
In the code above the first clause ensures that the recursion can terminate, because this clause is not recursive (i.e. it makes no calls to the predicate itself).
In the second clause (which is recursive) we have made sure, that we go one ancestor-step further back, before making the recursive call. I.e. we have ensured that we make some progress in the problem.
Side Effects
Besides a strict evaluation order Prolog also has side effects. For example Prolog has a number of predefined predicates for reading and writing.
The following goal will write the found ancestors of «Pam»:
?- ancestor("Pam", AA), write("Ancestor of Pam : ", AA), nl().
The ancestor call will find an ancestor of «Pam» in AA.
The write call will write the string literal «Ancestor of Pam : «, and then it will write the value of AA.
The nl call will shift to a new line in the output.
When running programs in PIE, PIE itself writes solutions, so the overall effect is that your output and PIE’s own output will be mixed. This might of course not be desirable.
A very simple way to avoid PIE’s own output is to make sure that the goal has no solutions. Consider the following goal:
?- ancestor("Pam", AA), write("Ancestor of Pam : ", AA), nl(), fail.
fail is a predefined call that always fails (i.e. it has no solutions).
The first three predicate calls have exactly the same effect as above: an ancestor is found (if such one exists, of course) and then it is written. But then we call fail this will of course fail. Therefore we must pursuit a backtrack point if we have any.
When pursuing this backtrack point, we will find another ancestor (if such one exists) and write that, and then we will fail again. And so forth.
So, we will find and write all ancestors. and eventually there will be no more backtrack points, and then the complete goal will fail.
There are a few important points to notice here:
- The goal itself did not have a single solution, but nevertheless all the solutions we wanted was given as side effects.
- Side effects in failing computations are not undone.
These points are two sides of the same thing. But they represent different level of optimism. The first optimistically states some possibilities that you can use, while the second is more pessimistic and states that you should be aware about using side effects, because they are not undone even if the current goal does not lead to any solution.
Anybody, who learns Prolog, will sooner or later experience unexpected output coming from failing parts of the program. Perhaps, this little advice can help you: Separate the «calculating» code from the code that performs input/output.
In our examples above all the stated predicate are «calculating» predicates. They all calculate some family relation. If you need to write out, for example, «parents», create a separate predicate for writing parents and let that predicate call the «calculating» parent predicate.
Conclusion
In this tutorial we have looked at some of the basic features of Prolog. You have seen facts, rules and goals. You learned about the execution strategy for Prolog including the notion of failing and backtracking. You have also seen that backtracking can give many results to a single question. And finally you have been introduced to side effects.
See also
Основы Системы Visual Prolog
В этом руководстве мы представляем программу, разработанную на платформе системы программирования Visual Prolog. Алгоритмы, используемые в руководстве , — те же, что и в руководстве «Fundamental Prolog» (Часть 2).
- 1 Отличия между Visual Prolog и традиционным Прологом
- 1.1 Различия в структуре программ
- 1.1.1 Декларации и Определения
- 1.1.2 Ключевые слова
- 1.1.3 Goal (цель)
- 2.1 Шаг 1: Создайте в IDE новый консольный проект
- 2.2 Шаг 2: Постройте пустой проект
- 2.3 Шаг 3: Поместите в файл family1.pro актуальный код
- 2.4 Шаг 4: Перестроение кода проекта
- 2.5 Шаг 5: Исполнение Программы
- 2.6 Рассмотрение программы
Отличия между Visual Prolog и традиционным Прологом
Различия между традиционным Прологом и Visual Prolog можно провести по следующим категориям:
- Различия в структуре программы:
Различия между Visual Prolog и традиционным Прологом имеются, но они не существенны. Они сводятся к пониманию того, как различаются декларации (declarations) от определений (definitions), а также к явному выделению цели Goal. Все это поддержано специальными ключевыми словами.
- Файловая структура программы::
Visual Prolog предоставляет возможности структуризации программ с использованием файлов различного типа.
- Границы видимости:
Программа системы Visual Prolog может поддерживать функционирование, располагающееся в различных модулях с использованием концепции идентификация пространств.
- Объектная ориентированность:
Программа на языке Visual Prolog может быть написана как объектно ориентированная программа с использованием классических свойств объектно-ориентированной парадигмы.
Различия в структуре программ
Декларации и Определения
В Прологе, когда необходимо использовать предикат, то это делается без каких-либо предварительных указаний движку Пролога о таких намерениях. Например, в предыдущих руководствах клауз предиката grandFather (дедушка) был непосредственно записан с использованием традиционной для Пролога конструкции голова-тело. Мы не беспокоились о том, чтобы в тексте программы предупредить движок явно, что такая конструкция придиката потребуется.
Аналогично, когда в традиционном Прологе требуется использовать составной домен, мы можем его использовать без предупреждения движка по поводу этого намерения. Мы просто используем домен тогда, когда в этом возникает необходимость.
Однако, в Visual Prolog, перед написанием кода для тела клауза предиката мы должны сначала объявить о существовании такого предиката компилятору. Аналогично, перед использованием любых доменов они должны быть объявлены и представлены компилятору.
Причиной такой необходимости в предупреждениях является попытка как можно раньше обнаружить возможность исключений периода исполнения.
Под «исключениями периода исполнения (runtime exceptions)», мы понимаем события, возникающие только во время исполнения программы. Например, если Вы вознамерились использовать целое число в качестве аргумента функтора, а вместо этого вы по ошибке использовали вещественное число, то в процессе исполнения возникла бы ошибка периода исполнения (в программах, написанных для ряда компиляторов, не не для Visual Prolog) и программа в этом случае завершилась бы неуспешно.
Когда Вы объявляете предикаты или доменты, которые определены, то появляется своего рода позиционная грамматика (какому домену принадлежит какой аргумент), доступная компилятору. Более того, когда Visual Prolog выполняет компиляцию, он тщательно проверяет программу на наличие таких грамматических ошибок, наряду с другими.
Благодяря этому свойству Visual Prolog, повышается конечная эффективность программиста. Программист не должен ждать, когда реально работаящая программа совершит ошибку. Действительно, те из Вас, кто имеет опыт в программировании, понимает насколько этот код безопасен. Часто конкретная последовательность событий, приводящая к исключению периода исполнения кажется настолько неуловимой, что ошибка может проявиться через много лет, или она может заявить о себе в критической ситуации и привести к непредсказуемым последствиям!
Все это автоматически ведет к тому, что компилятор должен получать точные инструкции по поводу предикатов и доменов в виде соответствующих объявлений, которые должны предшествовать определениям.
Ключевые слова
Программа на Visual Prolog, представляемая кодом, разделяется ключевыми словами на секции разного вида путем использования ключевых слов, предписывающих компилятору, какой код генерировать. К примеру, есть ключевые слова, обозначающие различие между декларациями и определениями предикатов и доменов. Обычно, каждой секции предшествует ключевое слово. Ключевых слов, обозначающих окончание секции, нет. Наличие другого ключевого слова обозначает окончание предыдущей секции и начало другой.
Исключением из этого правила являются ключевые слова implement и end implement. Код, содержащийся между этими ключевыми словами, есть код, который относится к конкретному классу. Те, кто не понимает концепцию класса, может пока (в рамках этого руководства) представлять себе его как модуль или раздел какой-то программы более высокого уровня.
В рамках этого руководства мы представляем только часть ключевых слов, приведенных ниже. Мы также объясняем назначение этих ключевых слов, а конкретный синтаксис легко может быть изучен по документации. В Visual Prolog есть и другие ключевые слова, они упоминаются в других рукодствах.
В этом руководстве используются следующие ключевые слова:
implement и end implement
Среди всех ключевых слов, обсуждаемых здесь, это единственные ключевые слова, используемые парно. Visual Prolog рассматривает код, помещенный между этими ключевыми словами, как код, принадлежащий одному классу. За ключевым словом implement обязательно ДОЛЖНО следовать имя класса.
Это ключевое слово используется для расширения области видимости класса. Оно должно быть помещено вначале кода класса, сразу после ключевого слова implement (с именем класса и, возможно именем интерфейса — прим. перев.).
Это ключевое слово исползуется для обозначения секции кода, котора определяет неоднократно используемые значения, применяемые в коде. Например, если строковый литерал «PDC Prolog» предполагается использовать в различных местах кода, тогда можно единожды определить мнемоническое (краткое, легко запоминаемое слово) для использовани в таких местах:
constants pdc="PDC Prolog".
Заметьте, что определение константы завершается точкой (.). В отличие от переменных Пролога константы должны начинаться со строчной буквы (нижний регистр).
Это ключевое слово используется для обозначения секции, объявляющей домены, которые будут использованы в коде. Синтаксис таких объявлений позволяет порождать множество вариантов объявлений доменов, используемых в тексте программы. В пределах этого руководства начального уровня мы не будем вдаваться в детали объаявлений доменов. Вообще говоря, объявляется функтор, который будет использоваться в качестве домена и ряд доменов, которые используются в качестве его аргументов. Функторы и составные домены рассматриваются в соответствующем руководстве.
class facts
Это ключевое слово представляет секцию, в которой объявляются факты, которые будут в дальнейшем использоваться в тексте программы. Каждый факт объявляется как имя, используемое для обозначения факта, и набор аргументов, каждый из которых должен соответствовать либо стандартному (предопределенному), либо объявленному домену.
class predicates
Эта секция содержит объявления предикатов, которые определяются в тексте программы в разделе clauses. И опять, объявление предиката — это имя, которое присваивается предикату, и набор аргументов, каждый из которых должен соответствовать либо стандартному (предопределенному), либо объявленному домену.
Среди всех разделов, существующих в тексте программ на Visual Prolog, это единственный раздел, который близко совпадает с традиционными программами на Прологе. Он содержит конкретные определения объявленных в разделе class predicates предикатов, причем синтаксически им соответствующие.
Этот раздел определяет главную точку входа в программу на языке системы Visual Prolog. Более детальное описание приводится ниже.
Goal (цель)
В традиционном Прологе, как только какой-либо предикат определен в тексте, Пролог-машине может быть предписано выполнение программы, начиная с этого предиката. В Visual Prolog это не так. Будучи компилятором, он отвечает за генерацию эффективного исполняемого кода написанной программы. Этот код исполняется не в то же время, когда компилятор порождает код. Поэтому компилятору надо знать заранее точно, с какого предиката начнется исполнение программы. Благодаря этому, когда программа вызывается на исполнение, она начинает работу с правильной начальной точки. Как можно уже догадаться, откомпилированная программа может работать независимо от компилятора Visual Prolog и без участия среды IDE.
Для того, чтобы это стало возможным, введен специальный раздел, обозначенный ключевым словом Goal. Его можно представлять как особый предикат, не имеющий аргументов. Это предикат — именно тот предикат, с которого вся программа начинает исполняться.
Файловое структурирование программ
Необходимость помещения всех частей большой программы в один файл несомненно является неудобством. Это ведет к тому, что программа становится нечитаемой и иногда неправильной. Visual Prolog предусматривает возможность деления текста программы на отдельные файлы, используя среду IDE (Integrated Development Environment) и, кроме того, IDE позволяет помещать логически связанные фрагменты текста программы в отдельные файлы. Несмотря на такое разделение программы на части, сущности, находящиеся в общем использовании, доступны.
Например, если имеется домен, который используется несколькими файлами, то объявление домена делается в отдельном файле и к этому файлу из других файлов существует доступ.
Для упрощения этого руководства мы будем использовать один файл для разработки текста программы. На самом деле в процессе построения программы среда IDE создавала бы автоматически несколько файлов, но мы сейчас будем это умалчивать. Об этом написано в других руководствах.
Расширение Области Видимости
В Visual Prolog текст программы разделен на отдельные части, какждая часть определяется как класс (class). В объектно-ориентированных языках программирования, класс — это пакет кода и ассоциированные с ним данные. Это требует длительных объяснений и сделано в других руководствах. Те, кто не знаком с объектно-ориентированным программированием, может представлять себе класс нестрого как синоним понятия модуль. В Visual Prolog каждый класс обычно помещается в отдельный файл.
В процессе исполнения программы, часто бывает так, что программе может потребоваться вызвать предикат, который определен в другом классе (файле). Аналогично, данные (константы) или домены могут быть востребованы в другом файле.
Visual Prolog позволяет делать такие взаимные ссылки на предикаты или данные используя так называемую концепцию области видимости (scope access). Это может стать понятным на примере. Предположим имеется предикат, называемый pred1 и определенный в классе называемом class1 (который помещается в другом файле, согласно стратегии среды IDE), и мы хотим вызвать этот предикат в теле клауза некоторого другого предиката pred2, находящегося в другом файле (скажем, class2). Тогда вот как предикат pred1 должен бы быть вызван в теле клауза предиката pred2 :
clauses pred3:- . !. pred2:- class1::pred1, % pred1 неизвестен в этом файле. % Он определен в другом файле, % поэтому требуется квалификатор класса. pred3, .
В приведенном примере видно, что тело клауза предиката pred2 вызывает два предиката pred1 и pred3. Поскольку pred1 определен в другом файле (где определен класс class1), постольку слово class1 с символом :: (два двоеточия) предшествует слову pred1. Это можно назвать как квалификатор класса. Но предикат pred3 определен внутри того же самого файла, что и предикат pred2. Поэтому здесь нет необходимости использовать class2:: перед вызовом предиката pred3.
Технически такое поведение объясняется следующим: Область видимости (scope visibility) предиката pred3 находится внутри той же области, где находится предикат pred2. Поэтому здесь не нужно показывать, что pred3 и pred2 находятся в одном классе. Компилятор автоматически увидит определение предиката pred3 внутри той же области, в классе class2.
Область видимости конкретного класса лежит внутри границ, где класс определен (то есть в интервале между ключевыми словами implement — end implement ). Предикаты, определенные здесь, могут вызывать друг друга без квалификатора класса и двойного двоеточия (::).
Область видимости класса может быть расширена использованием ключевого слова open. Это ключевое слово информирует компилятор о том, что в этот класс должны быть «доставлены» имена (предикатов / констант / доменов), которые были определены в других файлах. Если область видимости расширена, то необходимости использования квалификатора класса (с двойным двоеточием) нет.
open class1 . clauses pred3:- . !. pred2:- pred1, % Внимание: квалификатор "class1::" больше не нужен, % поскольку область видимости расширена % использованием ключевого слова 'open' pred3, .
Объектная ориентированность
Visual Prolog является полностью объектно-ориентированным языком.
Весь код, который разрабатывается для программы, помещается в класс. Это происходит само собой, даже если Вы не интересуетесь объектными свойствами языка. Это свойство обнаруживается в примере, разбираемом в этом руководстве. Код помещается в класс, называемый «family1», несмотря на то, что мы не используем объекты, порождаемые этим классом. Кроме того, вы этом классе мы используем общедоступные предикаты, находящиеся в других классах.
В этом руководстве объектные свойства языка не используются. Объектные свойства языка используются в других руководствах.
Полностью работающий пример: family1.prj6
Сгрузитe: Исходные Файлы проекта, используемого в этом руководстве.
Давайте теперь все полученные знания соберем вместе и создадим первую программу на языке системы Visual Prolog. Общая логика будет та же, что и рассмотренная в руководстве «Fundamental Prolog. Part 2». Текст программы приведен ниже. Его надо поместить в файл с именем family1.pro. Реальный текст программы мы напишем с помощью среды IDE (Integrated Development Environment) системы Visual Prolog. На самом деле файлов больше, чем требуется для этого руководства, но они будут созданы (и в дальнейшем будут поддерживаться) автоматически средой IDE. Пошаговая инструкция по использованию IDE (с фрагментами экрана) для разработки программы приводится ниже.
Но прежде всего ознакомимся с главным текстом программы:
implement family1 open core constants className = "family1". classVersion = "$JustDate: $$Revision: $". clauses classInfo(className, classVersion). domains gender = female(); male(). class facts - familyDB person : (string Name, gender Gender). parent : (string Person, string Parent). class predicates father : (string Person, string Father) nondeterm anyflow. clauses father(Person, Father) :- parent(Person, Father), person(Father, male()). class predicates grandFather : (string Person, string GrandFather) nondeterm anyflow. clauses grandFather(Person, GrandFather) :- parent(Person, Parent), father(Parent, GrandFather). class predicates ancestor : (string Person, string Ancestor) nondeterm anyflow. clauses ancestor(Person, Ancestor) :- parent(Person, Ancestor). ancestor(Person, Ancestor) :- parent(Person, P1), ancestor(P1, Ancestor). class predicates reconsult : (string FileName). clauses reconsult(FileName) :- retractFactDB( familyDB), file::consult(FileName, familyDB). clauses run():- console::init(), stdIO::write("Load data\n"), reconsult("fa.txt"), stdIO::write("\nfather test\n"), father(X, Y), stdIO::writef("% is the father of %\n", Y, X), fail. run():- stdIO::write("\ngrandFather test\n"), grandFather(X, Y), stdIO::writef("% is the grandfather of %\n", Y, X), fail. run():- stdIO::write("\nancestor of Pam test\n"), X = "Pam", ancestor(X, Y), stdIO::writef("% is the ancestor of %\n", Y, X), fail. run():- stdIO::write("End of test\n"). end implement family1 goal mainExe::run(family1::run).
Шаг 1: Создайте в IDE новый консольный проект
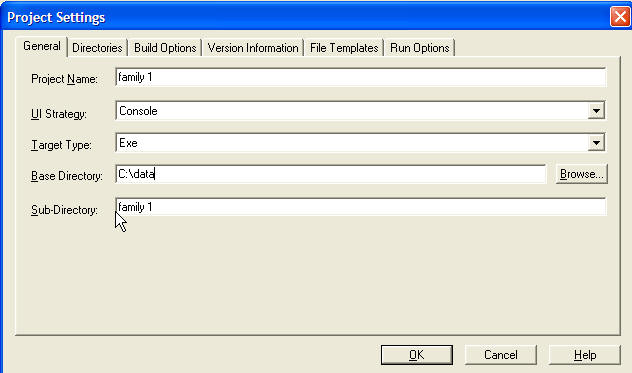
Шаг 1a. После старта среды программирования Visual Prolog, выберите New из меню Project.

Шаг 1b. Появляется диалог. Введите соответствующую информацию. Удостоверьтесь, что стратегия пользовательского интерфейса (UI Strategy) Console, а НЕ GUI.
Шаг 2: Постройте пустой проект
Шаг 2a. Когда проект только что создан, среда будет показывать проектное окно, как показано ниже. В этот момент пока никакой информации о том, от каких файлов зависит проект, нет. Однако основные тексты программ проектных файлов уже созданы.
Шаг 2b. Выберите из меню Build позицию Build. Пустой проект, который ничего не делает, будет построен. (В этот момент времени никаких сообщений о ошибках быть не должно).
В процессе построения проекта посмотрите на сообщения, которые динамически появляются в окне Messages среды IDE. (Если окно Messages не видно, его можно вызвать на передний план, используя меню Window в среде IDE). Вы заметите, что среда IDE разумно включит в Ваш проект ВСЕ в необходимые модули PFC (Prolog Foundation Classes). Классы PFC являются теми классами, которые содержат поддержку функционирования программ, которые Вы строите.
Шаг 3: Поместите в файл family1.pro актуальный код
Шаг 3a. Начальный код, созданный самой средой IDE имеет самый общий вид и сам по себе не делает ничего полезного. Вам необходимо удалить этот код полностью и скопировать (через Copy и Paste) полностью (актуальный на данный момент) код программы family1.pro (приведенный в этом руководстве) в окно редактора.
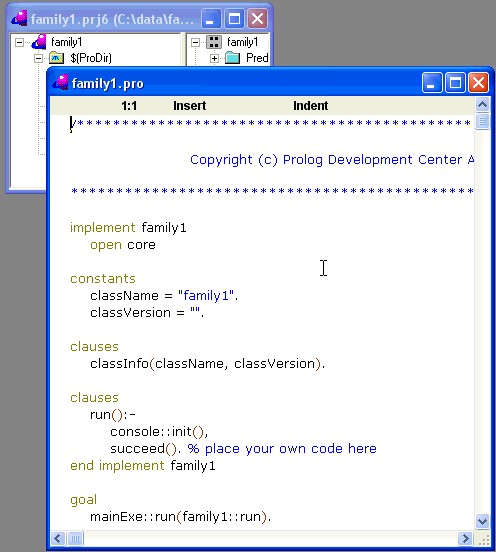
Шаг 3b. После выполнения операции copy-paste окошко с текстом файла family1.pro должно выглядеть так, как показано ниже:

Шаг 4: Перестроение кода проекта
Повторите вызов команды меню Build. IDE теперь уведомит, что исходный текст поменялся, и выполнит все необходимые действия для перекомпиляции соответствующих разделов. Если Вы вызовите команду меню Rebuild All, тогда ВСЕ модули проекта будут перекомпилированы. В случае больших проектов это может занимать значительное время. Rebuild All обычно используется в качестве финальной фазы после ряда небольших изменений и соответствующих компиляций, дабы удостовериться в том, что все в полном порядке.
В процессе выполнения команды Build среда IDE выполняет не только компиляцию. В это же время выясняется, нужны ли проекту другие модули из набора PFC (Prolog Faundation Classes), и, если это так, то такие модули добавляются и вызывается повторная перекомпиляция, если необходимо. Этот процесс можно наблюдать по сообщениям, появляющимся в окне сообщений (Message Window). Можно увидеть как IDE вызвало построение проекта дважды, поскольку были обнаружены директивы «include», повлиявшие на это.
Шаг 5: Исполнение Программы
Теперь у нас есть приложение, успешно откомпилированное с помощью Visual Prolog. Для того, чтобы проверить работу приложения, которое только что построено, можно запустить ее выполнение, вызвав команду из меню Build | Run in Window. Но в нашем случае это приведет к ошибке. Причина заключается в том, что наша маленькая программа для обеспечения своей работы пытается читать текстовый файл fa.txt. Этот текстовый файл содержит содержит записи относительно лиц, которые (записи) программа должна обработать. Вопросов синтаксита представления данных в этом файле мы коснемся позже.
Сейчас нам необходимо написать этот текстовый файл с использованием текстового редактора и поместить его в ту же директорию, где располагается сама исполняемая программа. Обычно исполняемая программа помещается в поддиректории проектной директории, имеющей имя EXE.
Давайте создадим такой файл сами с использованием среды IDE. Вызовите команду меню File | New. Появляется окно создания новой сущности Create Project Item. Выберите Текстовый файл (Text File) в списке слева. Затем выберите директорию, где будет размещаться файл (та же директория, где располагается исполняемое приложение family1.exe). Присвойте теперь имя fa.txt файлу и нажмите кнопку Create (создать). До тех пор, пока имя файла не введено, кнопка Create (создать) будет неактивна (надпись серого цвета). Удостоверьтесь, что флажот Add to project as module (добавить в проект на правах модуля) включен. Полезность включения файла в проект заключается в том, что это будет удобно для последующей отладки и других действий.
Файл следует заполнить текстом следующего содержания:
clauses person("Judith",female()). person("Bill",male()). person("John",male()). person("Pam",female()). parent("John","Judith"). parent("Bill","John"). parent("Pam","Bill").
Несмотря на то, что это файл данных, Вы заметите, что синтаксис файла очень похож на обычный код Пролога! Даже несмотря на то, что программа теперь откомпилирована и представлена в двоичном формате, Вы можете менять ход и результаты ее исполнения, изменяя данные, которые программа обрабатывает. И эти данные записываются в этот текстовый файл с использованием того же самого синтаксиса Пролога. Visual Prolog таким образом эмулирует свойство использования динамически изменяемого кода, характерное для традиционного пролога. Хотя не все свойства использования динамически изменяемого кода традиционного Пролога воспроизводятся, но достаточно сложные структуры данных (или не сложные, как в этом примере) могут быть использованы.
Синтаксис файла fa.txt ДОЛЖЕН быть совместим с определениями доменов в программе. Например, функтор, применяемый для определения персоны ДОЛЖЕН быть person и никак иначе. В противном случае соответствующий составной домен не будет инициализирован. (Понятия функторов и составных доменов рассматриваются в других руководствах).
Теперь, запустив программу по команде меню Build | Run in the Window вы увидите:

Программа обрабатывает данные, помещенные в файл fa.txt и порождает логические связи персон, данные о которых там помещены.
Рассмотрение программы
Логика программы очень проста. Мы ее уже обсуждали в других руководствах, где рассматривалось как корректное представление данных может помочь построить эффективную программу на Прологе. Давайте теперь обратим внимание на логику используемого метода.
При старте непосредственно будет вызван главный предикат. Здесь все построена вокруг предиката run. Предикат run прежде всего зачитывает данные, записанные в файле fa.txt. После загрузки данных, программа систематически переходит от одной проверки к другой, обрабатывая данные, и выводит на консоль выводы на базе этих проверок.
Обработка данных основывается на стандартных механизмах отката и рекурсивных вызовов. В этом руководстве детально не рассматривается как работает Пролог, но приведем краткое описание работы.
Когда предикат run вызывает предикат father, он не ограничивается первым удовлетворяющим решением предиката father. Применение предиката fail в конце последовательности понуждает механизм Пролога к поиску следующего прохода предиката father. Такое поведение, называется backtracking (откат), поскольку кажется, что механизм Пролога буквально перепрыгивает назад, минуя ранее исполненный код.
Это происходит рекурсивно (то есть как повтояющийся или циклический процесс) и в каждом цикле предикат father вырабатывает новый результат. В итоге все возможные определения «отцов», представленные данными исчерпываются и у предиката run нет другого выхода как перейти к следующему своему клаузу.
Предикат father (так же как и ряд других предикатов) объявлен как нетерминированный. Для обозначения недетерминированных предикатов используется ключевое слово nondeterm, обозначающее, что предикат может вырабатывать множество решений посредством бэктрекинга (отката).
Если никакое ключевое слово в объявлении предиката не используется, то предикат получает режим процедуры, которая может выработать только одно решение, и предикат father прекратил бы работу после получения первого же результата и не смог бы быть вызван повторно. Заметим, следует быть очень осторожными в использовании отсечения (cut), обозначаемого как !, в клаузах таких недетерминированных предикатов. Если в конце клаузы предиката father помещено отсечение, то предикат выработает только одно решение (даже если он объявлен как недетерминированный).
Квалификатор направлений ввода-вывода anyflow говорит компилятору о том, что параметры, назначенные предикату могут быть как связанными, так и свободными, без каких либо ограничений. Это означает, что используя одну и ту же декларацию предиката father, можно будет получать как имя отца (в случае, если имя потомка связано) так и имя потомка (в случае, если имя отца связано). Ситуация, когда оба параметра связаны, также обрабатывается — и в этом случае проверяется существует ли отношение между данными, представленными параметрами.
И, наконец, квалификатор anyflow включает ситуацию, когда оба параметра предиката father являются свободными переменными. В этом случае, предикат father вернет в ответ на запрос различные комбинации отношений родитель-потомок, предусмтотренные в программе (представленные в загружаемом файле fa.txt). Последний вариант как раз и использован в предикате run, как видно во фрагменте, приведенном ниже. Можно заметить, что переменные X и Y переданные предикату father не связаны при его вызове.
clauses run():- console::init(), stdIO::write("Load data\n"), reconsult("fa.txt"), stdIO::write("\nfather test\n"), father(X,Y), stdIO::writef("% is the father of %\n", Y, X), fail.
Заключение
На этом материале мы познакомились с тем, что программы, написанные в системе программирования Visual Prolog, часто очень похожи на программы, написанные в традиционном Прологе. Некоторый набор ключевых слов используется для обозначения различий частей исходного кода на языке системы Visual Prolog. Хотя Visual Prolog является объектно-ориентированным языком, сохраняется возможность разработки кода, не использующего свойства объектной ориентированности. Было показано работающее приложение консольного типа, которое поясняет как создавать подобные программы.
Мы увидели, кроме того, как эмулируется работа с динамическими данными, характерная для традиционного Пролога. Это делается путем помещения части кода в виде внешнего файла, отделенного от программы, представленной в двоичном формате. Синтаксис данных такого рода полностью соответствует синтаксису Пролога.
Логическое программирование на Prolog для чайников

Меня зовут Михаил Горохов, и эта статья написана в рамках вузовского курсового проекта. В первую очередь эта статья ориентирована на студентов ПМ и ПМИ , на долю которых выпало изучение прекрасного мощного языка Prolog, и которым приходится изучать совершенно новый и непривычный для них подход. Первое время он даже голову ломает.
Особенно любителям оптимизации.В конце статьи я оставлю полезные ссылки. Если у вас останутся вопросы — пишите в комментариях!
Начнем туториал: Пролог для чайников!
Логическое программирование
Существуют разные подходы к программированию. Часто выделяют такие парадигмы программирования:
- Императивное (оно же алгоритмическое или процедурное). Самая известная парадигма. Программист четко прописывает последовательность команд, которые должен выполнить процессор. Примеры: C/C++, Java, C#, Python, Golang, машина Тюрьнга, алгоритмы Маркова. Все четко, последовательно
как надо. Синоним императивного — приказательное. - Аппликативное (Функциональное). Менее известная, но тоже широко используемая. Примеры языков: Haskell, F#, Лисп. Основывается на математической абстракции лямбда вычислениях. Благодаря чистым функциям очень удобно параллелить такие программы. Чистые функции — функции без побочных эффектов. Если такой функции передавать одни и те же аргументы, то результат всегда будет один и тот же. Такие языки обладают высокой надежностью кода.
- И наконец — Декларативное (Логическое). Основывается на автоматическом доказательстве теорем на основе фактов и правил. Примеры языков: Prolog и его диалекты, Mercury. В таких языках мы описываем пространство состояний, в которых сам язык ищет решение к задаче. Мы просто даем ему правила, факты, а потом говорим, что «сочини все возможные стихи из этих слов», «реши логическую задачу», «найди всех братьев, сестер, золовок, свояков в генеалогическом древе», или «раскрась граф наименьшим кол-вом цветов так, что смежные ребра были разного цвета». Что такое ЛП я обозначил. Предлагаю сразу перейти к практике, к основам Prolog (PROgramming in LOGic). На практике все становится понятнее. Практику и теорию я буду чередовать. Не беспокойтесь, если сразу будет что-то не понятно. Повторяйте за мной, и вы разберетесь.
Установка Prolog
Существую разные реализации (имплементации) Пролога: SWI Prolog, Visual Prolog, GNU Prolog. Мы установим SWI Prolog.
Установка на Arch Linux:
sudo pacman -S swi-prologУстановка на Ubuntu:
sudo apt install swi-prologProlog работает в режиме интерпретатора. Теперь можем запустить SWI Prolog. Запускать не через swi-prolog, а через swipl:
[user@Raft ~]$ swipl Welcome to SWI-Prolog (threaded, 64 bits, version 8.2.3) SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software. Please run ?- license. for legal details. For online help and background, visit https://www.swi-prolog.org For built-in help, use ?- help(Topic). or ?- apropos(Word). ?-Ура! Оно работает!
Теперь поставим на Windows.
Перейдем на официальный сайт на страницу скачивания стабильной версии. Ссылка на скачивание. Клик. Скачаем 64х битную версию. Установка стандартная. Чтобы ничего не сломать, я решил галочки не снимать. Ради приличия я оставлю скрины установки.

Основы Prolog. Факты, правила, предикаты
Есть утверждения, предикаты:
- Марк изучает книгу (учебник, документацию)
- Маша видит клавиатуру (мышку, книгу, тетрадь, Марка)
- Миша изучает математику (ЛП, документацию, учебник)
- Саша старше Лёши
С английского «predicate» означает «логическое утверждение».
Есть объекты: книга, клавиатура, мышка, учебник, документация, тетрадь, математика, ЛП, Марк, Маша, Саша, Даша, Лёша, Миша, да что угодно может быть объектом.
Есть отношения между объектами, т.е то, что связывает объекты. Связь объектов можно выразить через глаголы, например: читать, видеть, изучать. Связь можно выразить через прилагательное. Миша старше Даши. Даша старше Лёши.Получается.. связью может быть любая часть речь? Получается так.Прекрасно! Давайте попробуем запрограммировать эти утверждения на Прологе. Для этого нам нужно:
- Создать новый текстовый файл, который я назову simple.pl (.pl — расширение Пролога)
- В нем написать простой однострочный код на Прологе
- Запустить код с помощью SWI Prolog
- Спросить у Пролога этот факт
study(mark, book).Запустим. На линуксе это делается таким образом:
[user@Raft referat]$ swipl simple.pl Welcome to SWI-Prolog (threaded, 64 bits, version 8.2.3) SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software. Please run ?- license. for legal details. For online help and background, visit https://www.swi-prolog.org For built-in help, use ?- help(Topic). or ?- apropos(Word). ?-На Windows я использую notepad++ для написания кода на Прологе. Я запущу SWI-Prolog и открою файл через consult.
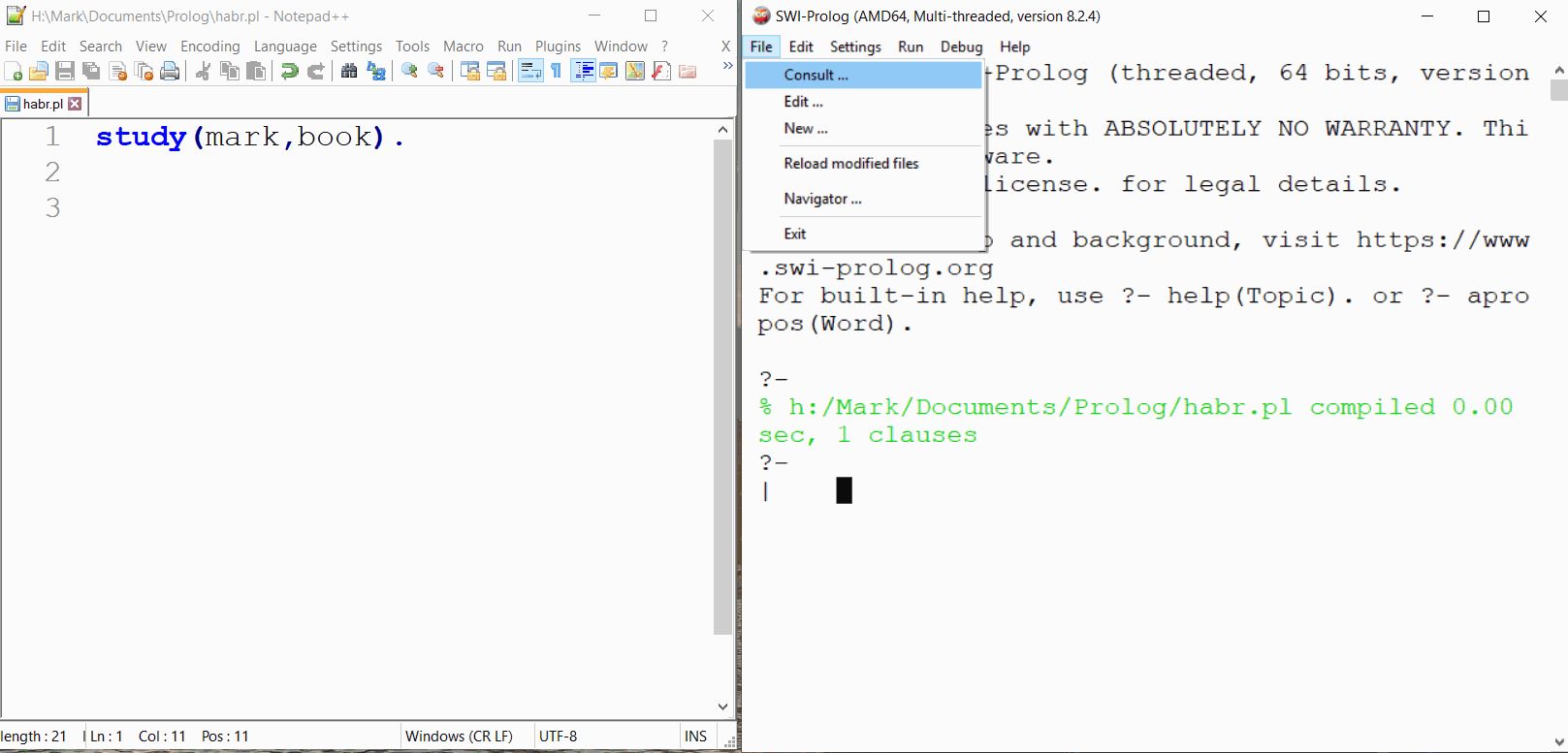
Что мы сделали? Мы загрузили базу знаний (те, которые мы описали в простом однострочном файле simple.pl) и теперь можем задавать вопросы Прологу. То есть система такая: пишем знания в файле, загружаем эти знания в SWI Prolog и задаем вопросы интерпретатору. Так мы будем решать поставленную задачу. (Даже видно, в начале интерпретатор пишет «?- «. Это означает, что он ждет нашего вопроса
, как великий мистик)Давайте спросим «Марк изучает книгу?» На Прологе это выглядит так:
?- study(mark, book). true. ?-По сути мы спросили «есть ли факт study(mark, study) в твоей базе?», на что нам Пролог лаконично ответил «true.» и продолжает ждать следующего вопроса. А давайте спросим, «изучает ли Марк документацию?»
?- study(mark, book). true. ?- study(mark, docs). false. ?-Интерпретатор сказал «false.». Это означает, что он не нашел этот факт в своей базе фактов.
Расширим базу фактов. После я определю более строгую терминологию и опишу, что происходит в этом коде.
Сделаю важное замечание для начинающих. Сложность Пролога состоит в специфичной терминологии и в непривычном синтаксисе, в отсутствии императивных фич, вроде привычного присвоения переменных.
% Код на прологе. Я описал 11 фактов. % Каждый факт оканчивается точкой ".", как в русском языке, как любое утверждение. % Комментарии начинаются с "%". % Интерпретатор пролога игнорирует такие комментарии. /* А это многострочный комментарий */ % Факты. 11 штук study(mark, book). % Марк изучает книгу study(mark, studentbook). % Марк изучает учебник study(mark, docs). % Марк изучает доки see(masha, mouse). % Маша видит мышь see(masha, book). % Маша видит книгу see(masha, notebook). % Маша видит тетрадь see(masha, mark). % Маша видит Марка study(misha, math). % Миша изучает матешу study(misha, lp). % Миша изучает пролог study(misha, docs). % Миша изучает доки study(misha, studentbook). % Миша изучает учебникТерминология. Объекты данных в Прологе называются термами (предполагаю, от слова «термин»). Термы бывают следующих видов:
- Константами. Делятся на числа и атомы. Начинаются с маленькой буквы. Числа: 1,36, 0, -1, 123.4, 0.23E-5. Атомы — это просто символы и строки: a, abc, neOdinSimvol, sTROKa. Если атом состоит из пробела, запятых и тд, то нужно их обрамлять в одинарные кавычки. Пример атома: ‘строка с пробелами, запятыми. Eto kirilicca’.
- Переменными. Начинаются с заглавной буквы: X, Y, Z, Peremennaya, Var.
- Структурами (сложные термы). Например, study(misha, lp).
- Списками. Пример: [X1], [Head|Tail]. Мы разберем их позже в этой статье. Есть хорошая статья, которая подробно рассказывает про синтаксис и терминологию Пролога. Рекомендую её, чтобы лучше понять понятия Пролог.
Пролог использует методы полного перебора и обход дерева. Во время проверки условий (доказательства утверждений) Пролог заменяет переменные на конкретные значения. Через пару абзацев будут примеры.
study(mark, book). — такие конструкции называются фактами. Они всегда истинны. Если факта в базе знаний нету, то такой факт ложный. Факты нужно оканчивать точкой, так же как утверждения в русском языке.
«Задавать вопросы Прологу» означает попросить Пролог доказать наше утверждение. Пример: ?- study(mark, book). Если наше утверждение всегда истинно, то Пролог напечатает true, если всегда ложно, то false. Если наше утверждение верно при некоторых значениях переменных, то Пролог выведет значения переменных, при которых наше утверждение верно.
Давайте загрузим факты в Пролог и будем задавать вопросы. Давайте узнаем, что изучал mark. Для этого нам нужно написать «study(mark, X).» Если мы прожмем «Enter«, то Пролог нам выдаст первое попавшееся решение
?- study(mark, X). X = book .Чтобы получить все возможные решения, нужно прожимать точку с запятой «;«.
?- study(mark, X). X = book ; X = studentbook ; X = docs.Можем узнать, кто изучал документацию.
?- study(Who, docs). Who = mark ; Who = misha.Можно узнать, кто и что изучал!
?- study(Who, Object). Who = mark, Object = book ; Who = mark, Object = studentbook ; Who = mark, Object = docs ; Who = misha, Object = math ; Who = misha, Object = lp ; Who = misha, Object = docs ; Who = misha, Object = studentbook.Пролог проходится по всей базе фактов и находит все такие переменные Who и Object, что предикат study(Who, Object) будет истинным. Пролог перебирает факты и заменяет переменные на конкретные значения. Пролог выведет такие значения переменных, при которых утверждения будут истинными. У нас задача состояла только из фактов, и решение получилось очевидным.
Переменная Who перебирается среди имен mark, misha, а переменная Object среди book, studentbook, docs, lp, math.
Who не может равняться masha, потому что masha ничего не узнала согласно нашей базе фактов. Аналогично Object не может равняться tomuChevoNetuVBaze, так как такого значения не было в базе фактов. Для study на втором месте были только book, studentbook, docs, lp, math.Короче, я старался понятным языком объяснить метод полного перебора, и что Пролог
туповсе перебирает, пока что-то не подойдет. Все просто.А теперь разберем правила в Прологе. Напишем ещё одну программу old.pl.
% Это факты older(sasha, lesha). % Саша старше Лёши older(misha, sasha). % Миша старше Саши older(misha, dasha). % Миша старше Даши older(masha, misha). % Маша старше Миши % Это правило older(X,Y) :- older(X, Z), older(Z,Y). % X старше Y, если X старше Z и Z старше Y % Проще: X > Y, если X > Z и Z > Y % % X, Y, Z - это переменные. % Вместо X, Y, Z подставляются конкретные значения: misha, dasha, sasha, lesha % Main idea: если Пролог найдет среднего Z, который между X и Y, то X старше Y.older(X,Y) :- older(X, Z), older(Z,Y) — такие конструкции называются правилами. Чтобы из факта получить правило, нужно заменить точку «.» на двоеточие дефис «:-» и написать условие, когда правило будет истинным. Правила истинны только при определенных условиях. Например, это правило будет истинно в случае, когда факты older(X,Z) и older(Z,Y) истинны. Если переформулировать, то получается «X старше Y, если X старше Z и Z старше Y». Если математически: «X > Y, если X > Z и Z > Y».
Запятая «,» в Прологе играет роль логического «И». Пример: «0 < X, X < 5". X меньше 5 И больше 0.
Точка с запятой «;» играет роль логического «ИЛИ». «X < 0; X >5″. X меньше 0 ИЛИ больше 5.
Отрицание «not(Какой-нибудь предикат)» играет роль логического «НЕ». «not(X==5)». X НЕ равен 5.Факты и правила образуют утверждения, предикаты. (хорошая статья про предикаты)
Сперва закомментируйте правило и поспрашивайте Пролог, кто старше кого.
?- older(masha, X). X = misha.Маша старше Миши. Пролог просто прошелся по фактам и нашел единственное верный факт. Но.. мы хотели узнать «Кого старше Маша?». Логично же, что если Миша старше Саши И Маша старше Миши, то Маша также старше Саши. И Пролог должен решать такие логические задачи. Поэтому нужно добавить правило older(X,Y) :- older(X, Z), older(Z,Y).
Повторим вопрос.?- older(masha, X). X = misha ; X = sasha ; X = dasha ; X = lesha ; ERROR: Stack limit (1.0Gb) exceeded ERROR: Stack sizes: local: 1.0Gb, global: 21Kb, trail: 1Kb ERROR: Stack depth: 12,200,525, last-call: 0%, Choice points: 6 ERROR: Probable infinite recursion (cycle): ERROR: [12,200,525] user:older(lesha, _5658) ERROR: [12,200,524] user:older(lesha, _5678) ?-Программа смогла найти все решения. Но что это такое? Ошибка! Стек переполнен! Как вы думаете, с чем это может быть связано? Попробуйте подумать, почему это происходит. Хорошее упражнение — расписать на бумаге алгоритм older(masha,X) так, как будто вы — Пролог. Видите причину ошибки?
Это связано с бесконечной рекурсией. Это частая ошибка, которая возникает в программировании, в частности, на Прологе. older(X, Y) вызывает новый предикат older(X,Z), который в свою очередь вызывает следующий предикат older и так далее.
Нужно как-то остановить зацикливание. Если подумать, зачем нам проверять первый предикат «older(X, Z)» через правила? Если не нашел факт, то значит весь предикат older(X, Y) ложный (подумайте, почему).
Нужно объяснить Прологу, что факты и правила нужно проверять во второй части older(Z, Y), а в первой older(X, Y) — только факты
Нужно объяснить Прологу, что если он в первый раз не смог найти нужный факт, то ему не нужно приступать к правилу. Нам нужно как-то объяснить Прологу, где факт, а где правило.
Это задачу можно решить, добавив к предикатам ещё один аргумент, который будет показывать — это правило или факт.% Это факты older(sasha, lesha, fact). % Саша старше Лёши older(misha, sasha, fact). % Миша старше Саши older(misha, dasha, fact). % Миша старше Даши older(masha, misha, fact). % Маша старше Миши % Это правило older(X,Y, rule) :- older(X, Z, fact), older(Z,Y, _). % X старше Y, если X старше Z и Z старше Y % Проще: X > Y, если X > Z и Z > Y % % X, Y, Z - это переменные. % Пролог перебирает все возможные X, Y, Z. % Вместо X, Y, Z подставляются misha, dasha, sasha, lesha % Например: Миша старше Лёши, если Миша старше Саши и Саша старше ЛёшиНижнее подчеркивание «_» — это анонимная переменная. Её используют, когда нам не важно, какое значение будет на её месте. Нам важно, чтобы первая часть правила была фактом. А вторая часть может быть любой.
?- older(masha, X, _). X = misha ; X = sasha ; X = dasha ; X = lesha ; false.Наша программа вывела все верные ответы.
Возможно, возникает вопрос: откуда Пролог знает, что изучает Марк и что Миша старше Даши? Как он понимает такие человеческие понятия? Почему ассоциируется study(mark, math) с фразой «Марк изучает математику»? Почему не с «математика изучает Марка»?. Это наше представление. Мы договорились, что пусть первый терм будет обозначать «субъект», сам предикат «взаимосвязь», а второй терм «объект». Мы могли бы воспринимать по-другому. Это просто договеренность о том, как воспринимать предикаты. Пролог позволяет нам абстрактно описать взаимоотношения между термами.
Напишем предикат для нахождения факториала от N.
factorial(1, 1). factorial(N, F):- N1 is N-1, factorial(N1, F1), F is F1*N. % В Прологе пробелы, табуляция и новые строки работают также, как C/C++. % Главное в конце закончить предикат точкой.
«is» означает присвоить, т.е N1 будет равняться N-1. Присвоение значений переменным Пролога называется унификацией. «is» работает только для чисел. Чтобы можно было присваивать атомы, нужно вместо «is» использовать » full-width «>
Списки в Прологе отличаются от списков в C/C++, Python и других процедурных языков. Здесь список — это либо пустой элемент; либо один элемент, называемый головой, и присоединенный список — хвост. Список — это рекурсивная структура данных с последовательным доступом.
Списки выглядят так: [],[a], [abc, bc], [‘Слово 1’, ‘Слово 2’, 1234], [X], [Head|Tail].
Рассмотрим [Head|Tail]. Это всё список, в котором мы выделяем первый элемент, голову списка, и остальную часть, хвост списка. Чтобы отделить первые элементы от остальной части списка, используется прямая черта «|».
Можно было написать такой список [X1,X2,X3|Tail]. Тогда мы выделим первые три элемента списка и положим их в X1, X2, X3, а остальная часть списка будет в Tail.В списках хранятся данные, и нам нужно с ними работать. Например, находить минимум, максимум, медиану, среднее, дисперсию. Может нужно найти длину списка, длину самого длинного атома, получить средний балл по N предмету среди студентов группы G. Может нужно проверить, есть ли элемент Elem в списке List. И так далее. Короче, нужно как-то работать со списками. Только предикаты могут обрабатывать списки (да и в целом в Прологе все обрабатывается предикатами).
Напишем предикат для перебора элементов списка, чтобы понять принцип работы списка.
% element(Список, Элемент) element([Head|Tail], Element) :- Element = Head; element(Tail, Element). ?- element([1,2,3,4,5,6, 'abc', 'prolog'], Elem). Elem = 1 ; Elem = 2 ; Elem = 3 ; Elem = 4 ; Elem = 5 ; Elem = 6 ; Elem = abc ; Elem = prolog ; false.element([Head|Tail],Element) будет истинным, если Element равен Head (первому элементу списка) ИЛИ если предикат element(Tail, Element) истинный. В какой-то момент эта рекурсия окончится. (Вопрос читателю: когда кончится рекурсия? Какое условие будет терминирующим?) Таким образом, предикат будет истинным, если Element будет равен каждому элементу списка [Head|Tail]. Пролог найдет все решения, и мы переберем все элементы списка.
Часто бывает нужным знать длину списка. Напишем предикат для нахождения длины списка. Протестим.
% list_length(Список, Длина списка) list_length([], 0). list_length([H|T], L) :- list_length(T, L1), L is L1+1. ?- list_length([123446,232,2332,23], L). L = 4. ?- list_length([123446,232,2332,23,sdfds,sdfsf,sdfa,asd], L). L = 8. ?- list_length([], L). L = 0. ?- list_length([1], L). L = 1. ?- list_length([1,9,8,7,6,5,4,3,2], L). L = 9.Мой Пролог предупреждает, что была не использована переменная H. Код будет работать, но лучше использовать анонимную переменную _, вместо singleton переменной.
В SWI Prolog имеется встроенный предикат length. Я реализовал аналогичный предикат list_length. Если встречается пустой список, то его длина равна нулю. Иначе отсекается голова списка, рекурсивно определяется длина нового получившегося списка и к результату прибавляется единица.
Чтобы лучше понять алгоритм, пропишите его на бумаге. Последовательно, так, как делает Пролог.
Последняя задача про списки в этой статье, это определить, принадлежит ли элемент списку. Например, 1, 2, 3 и 4 являются элементами списка [1,2,3,4]. Этот предикат мы назовем list_member.
mymember(Elem, [Elem|_]). mymember(Elem, [_|Tail]) :- mymember(Elem, Tail).Очевидно, что если список начинается с искомого элемента, то элемент принадлежит списку. В противном случае необходимо отсечь голову списка и рекурсивно проверить наличие элемента в новом получившемся списке.
Преимущества и недостатки Prolog
Пролог удобен в решении задач, в которых мы знаем начальное состояние (объекты и отношения между ними) и в которых нам трудно задать четкий алгоритм поиска решений. То есть чтобы Пролог сам нашел ответ.
Список задач, в которых Пролог удобен:
- Искусственный интеллект
- Компьютерная лингвистика. Написание стихов, анализ речи
- Поиск пути в графе. Работа с графами
- Логические задачи
- Нечисловое программирование
Знаменитую логическую задачу Эйнштейна можно гораздо легче решить на Прологе, чем на любом другом императивном языке. Одна из вариаций такой задачи:
На улице стоят пять домов. Каждый из пяти домов окрашен в свой цвет, а их жители — разных национальностей, владеют разными животными, пьют разные напитки и имеют разные профессии.
- Англичанин живёт в красном доме.
- У испанца есть собака.
- В зелёном доме пьют кофе.
- Украинец пьёт чай.
- Зелёный дом стоит сразу справа от белого дома.
- Скульптор разводит улиток.
- В жёлтом доме живет математик.
- В центральном доме пьют молоко.
- Норвежец живёт в первом доме.
- Сосед поэта держит лису.
- В доме по соседству с тем, в котором держат лошадь, живет математик.
- Музыкант пьёт апельсиновый сок.
- Японец программист.
- Норвежец живёт рядом с синим домом.
Кто пьёт воду? Кто держит зебру?
Замечание: в утверждении 6 справа означает справа относительно вас.
Научиться решать логические задачи на Пролог, можно по этой статье.
Ещё одна интересная статья. В ней автор пишет программу сочинитель стихов на Prolog.Интересная задача, которую вы можете решить на Прологе: раскрасить граф наименьшим количеством цветов так, чтобы смежные вершины были разного цвета.
Пролог такой замечательный язык! Но почему его крайне редко используют?
Я вижу две причины:- Производительность
- Альтернативы (например, нейросетей на Python)
Пролог решает задачи методом полного перебора. Следовательно, его сложность растет как O(n!). Конечно, можно использовать отсечения, например, с помощью «!». Но все равно сложность останется факториальной. Простые задачи не так интересны, а сложные лучше реализовать жадным алгоритмом на императивном языке.
Области, для которых предназначен Пролог, могут также успешно решаться с помощью Python, C/C++, C#, Java, нейросетей. Например, сочинение стихов, анализ речи, поиск пути в графе и так далее.
Я не могу сказать, что логическое программирование не нужно. Оно действительно развивает логическое мышление. Элементы логического программирования можно встретить на практике. И в принципе, логическое программирование — интересная парадагима, которую полезно знать, например, специалистам ИИ.
Что дальше?
Я понимаю, что статью я написал суховато и слишком «логично» (вероятно, влияние Пролога). Я надеюсь, статья вам помогла в изучении основ Логического Программирования на примере Пролога.
(Мои мысли: я часто использую повторения в статье. Это не сочинение, это туториал. Лучше не плодить ненужные синонимы и чаще использовать термины. По крайней мере, в туториалах. Так лучше запоминается. Повторение — мать учения. А как вы считаете?).
Это моя дебютная статья, и я буду очень рад конструктивной критике. Задавайте вопросы, пишите комментарии, я постараюсь отвечать на них. В конце статьи я приведу все ссылки, которые я упоминал и которые мне показались полезными.
Статью написал Горохов Михаил, успехов в обучении и в работе!
Ссылки
- Ссылка на скачивание SWI Prolog
- Синтаксис Пролога и его терминология
- Предикаты в Пролог
- Списки в Пролог
- Логические задачи
- Сочинение стихов с помощью Пролог
- И конечно же ссылка на Википедию
- Слышали о Пролог?
- Примеры использования Пролог
- prolog
- логическое программирование
- логика
- маи
- туториал
- для чайников
- введение в алгоритмы
- введение в программирование
- пми
- 1.1 Различия в структуре программ