ASCII
ASCII — это таблица кодировки символов, в которой каждой букве, числу или знаку соответствует определенное число. В стандартной таблице ASCII 128 символов, пронумерованных от 0 до 127. В них входят латинские буквы, цифры, знаки препинания и управляющие символы.

«IT-специалист с нуля» наш лучший курс для старта в IT
Что такое ASCII
Таблицу разработали в Америке в 60-х, и ее название расшифровывается как American Standard Code for Information Interchange — Американская стандартная кодировка для обмена информацией. Аббревиатура читается как «аски».
Существуют национальные расширения ASCII, которые кодируют буквы и символы, принятые в других алфавитах. «Стандартная» таблица называется US-ASCII, или международной версией. В большинстве национальных расширений заменена только часть символов, например знак доллара на знак фунта. Но для языков, где используются нелатинские алфавиты, заменяется большинство символов. Русский относится к таким языкам.
Профессия / 16 месяцев
Тестировщик-автоматизатор
Лучший выбор для быстрого старта в IT

Для чего нужна таблица ASCII
Цифровое устройство по умолчанию не понимает символы — только числа. Поэтому буквы, цифры и знаки приходится кодировать, чтобы задавать компьютеру соответствие между определенным начертанием и числовым значением. Сейчас вариантов кодирования несколько, и ASCII — одна из наиболее ранних кодировок. Она задала стандарты для последующих решений.
Когда появилась эта кодировка, компьютеров в современном представлении еще не существовало. Ее разработали для телетайпов — устройств обмена информацией, похожих на телеграфы с печатной машинкой. Сейчас ими практически не пользуются, но некоторые стандарты остались с тех времен. В том числе набор ASCII, который теперь применяется для кодирования информации в компьютерах.
Сейчас с помощью ASCII кодируются данные в компьютерных устройствах, на ней основано несколько других кодировок, кроме того, ее используют в творчестве — создают с помощью символов картинки. Это называется ASCII art.
Читайте также Кто такой frontend-разработчик?
Применение на практике
- При разработке сайта или приложения разработчику может понадобиться пользоваться ASCII, чтобы закодировать символы, не входящие в национальную кодировку.
- Можно сохранить документ или иной файл в формате ASCII — тогда все символы в нем будут закодированы этим набором. Такое может понадобиться, если человеку нужно передать информацию, которая будет читаться везде, — но некоторые функции форматирования в таком режиме будут недоступны.
- Можно ввести код ASCII с клавиатуры напрямую: при зажатом Alt набрать числовое значение, которое соответствует тому или иному символу из таблицы. Так можно печатать и символы, которые есть в расширенных версиях набора: смайлики, иероглифы, буквы алфавитов других стран и так далее. Код для таких символов может быть намного длиннее, чем для стандартных 128 букв и цифр.

Станьте Frontend-разработчиком
и создавайте интерфейсы сервисов, которыми пользуются все
Как устроена ASCII внутри
С помощью ASCII вводят, выводят и передают информацию, поэтому она должна описывать самые часто используемые символы и управляющие элементы (перенос, шаг назад и так далее). Таблица восьмибитная, а числа, которые соответствуют символам, переводятся в двоичный код, чтобы компьютер мог их распознавать. Десятичное же написание удобнее для людей. Еще используют шестнадцатеричное — с его помощью легче представить набор в виде таблицы.
Заглавные и строчные буквы в ASCII — это разные элементы. Причем в таблице строчные буквы расположены под заглавными, в том же столбце, но в разных строчках. Так набор оказывается нагляднее, а информацию легче проверять и работать с ней, например редактировать регистр с помощью автоматических команд.
Как расположены символы в ASCII
- Первые две строчки таблицы — управляющие символы: Backspace, перевод строки, начало и конец абзаца и прочие.
- В третьей строке расположены знаки препинания и специальные символы, такие как процент % или астериск * .
- Четвертая строка — числа и математические символы, а также двоеточие, точка с запятой и вопросительный знак.
- Пятая и шестая строчка — заглавные буквы, а также некоторые другие особые символы.
- Седьмая и восьмая строки описывают строчные буквы и еще несколько символов.
Отличия от Unicode
Когда мы говорим о кодировании, сразу вспоминается система международной кодировки символов Unicode. Важно не путать ее с ASCII — эти понятия не идентичны.
ASCII появилась раньше и включает в себя меньше символов. В стандартной таблице их всего 128, если не считать расширений для других языков. А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона. В набор входят практически все существующие сегодня символы, он очень широкий.
Unicode можно рассматривать как «продолжение», расширение ASCII. Первые 128 символов в «Юникоде» кодируются так же, как в ASCII, и это те же самые символы.
Fullstack-разработчик на Python
Fullstack-разработчики могут в одиночку сделать IT-проект от архитектуры до интерфейса. Их навыки востребованы у работодателей, особенно в стартапах. Научитесь программировать на Python и JavaScript и создавайте сервисы с нуля.

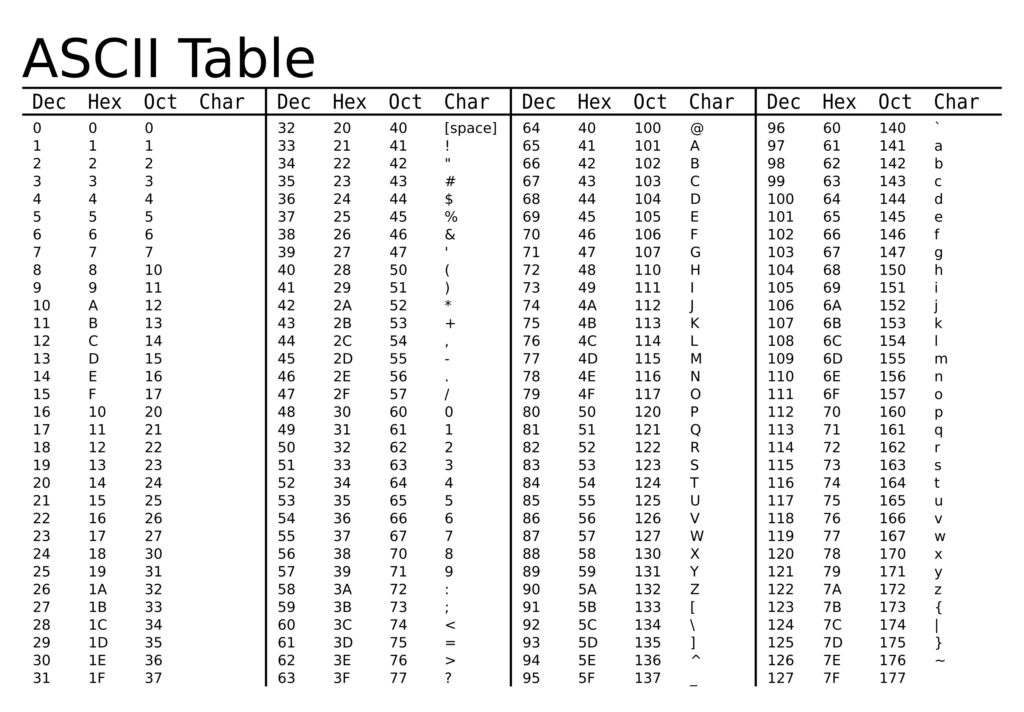
Так выглядит таблица ASCII (American Standard Code for Information Interchange) с символами от 0 до 127:
DEC HEX CHAR ------------- 0 00 NUL (Null) 1 01 SOH (Start of Heading) 2 02 STX (Start of Text) 3 03 ETX (End of Text) 4 04 EOT (End of Transmission) 5 05 ENQ (Enquiry) 6 06 ACK (Acknowledgment) 7 07 BEL (Bell) 8 08 BS (Backspace) 9 09 TAB (Horizontal Tab) 10 0A LF (Line Feed) 11 0B VT (Vertical Tab) 12 0C FF (Form Feed) 13 0D CR (Carriage Return) 14 0E SO (Shift Out) 15 0F SI (Shift In) 16 10 DLE (Data Link Escape) 17 11 DC1 (Device Control 1) 18 12 DC2 (Device Control 2) 19 13 DC3 (Device Control 3) 20 14 DC4 (Device Control 4) 21 15 NAK (Negative Acknowledgement) 22 16 SYN (Synchronous Idle) 23 17 ETB (End of Transmission Block) 24 18 CAN (Cancel) 25 19 EM (End of Medium) 26 1A SUB (Substitute) 27 1B ESC (Escape) 28 1C FS (File Separator) 29 1D GS (Group Separator) 30 1E RS (Record Separator) 31 1F US (Unit Separator) 32 20 SPACE (Space) 33 21 ! (Exclamation Mark) 34 22 " (Double Quote) 35 23 # (Number Sign) 36 24 $ (Dollar Sign) 37 25 % (Percent Sign) 38 26 & (Ampersand) 39 27 ' (Single Quote) 40 28 ( (Left Parenthesis) 41 29 ) (Right Parenthesis) 42 2A * (Asterisk) 43 2B + (Plus Sign) 44 2C , (Comma) 45 2D - (Hyphen-Minus) 46 2E . (Period) 47 2F / (Slash) 48 30 0 (Digit Zero) 49 31 1 (Digit One) 50 32 2 (Digit Two) 51 33 3 (Digit Three) 52 34 4 (Digit Four) 53 35 5 (Digit Five) 54 36 6 (Digit Six) 55 37 7 (Digit Seven) 56 38 8 (Digit Eight) 57 39 9 (Digit Nine) 58 3A : (Colon) 59 3B ; (Semicolon) 60 3C < (Less-Than Sign) 61 3D = (Equal Sign) 62 3E >(Greater-Than Sign) 63 3F ? (Question Mark) 64 40 @ (Commercial At) 65 41 A 66 42 B 67 43 C 68 44 D 69 45 E 70 46 F 71 47 G 72 48 H 73 49 I 74 4A J 75 4B K 76 4C L 77 4D M 78 4E N 79 4F O 80 50 P 81 51 Q 82 52 R 83 53 S 84 54 T 85 55 U 86 56 V 87 57 W 88 58 X 89 59 Y 90 5A Z 91 5B [ (Left Square Bracket) 92 5C \ (Backslash) 93 5D ] (Right Square Bracket) 94 5E ^ (Caret / Circumflex) 95 5F _ (Underscore) 96 60 ` (Grave Accent) 97 61 a 98 62 b 99 63 c 100 64 d 101 65 e 102 66 f 103 67 g 104 68 h 105 69 i 106 6A j 107 6B k 108 6C l 109 6D m 110 6E n 111 6F o 112 70 p 113 71 q 114 72 r 115 73 s 116 74 t 117 75 u 118 76 v 119 77 w 120 78 x 121 79 y 122 7A z 123 7B < (Left Curly Brace) 124 7C | (Vertical Bar) 125 7D >(Right Curly Brace) 126 7E ~ (Tilde) 127 7F DEL (Delete) Пожалуйста, обратите внимание, что таблица содержит только основные управляющие символы, цифры, латинские буквы (строчные и заглавные), а также некоторые специальные символы. В более расширенной таблице ASCII (расширенная ASCII) есть символы с кодами от 128 до 255, но они могут варьироваться в зависимости от кодировки (например, UTF-8 или ISO-8859-1).
Статьи по теме:
Функции получения символа по коду ASCII и наоборот.
Есть ли функцию, с помощью которой можно получить символ по коду ASCII, а также функция получения кода ASCII по символу? Например: А->65; 90->Z.
Отслеживать
Yaroslav Schubert
задан 10 авг 2011 в 19:04
Yaroslav Schubert Yaroslav Schubert
1,075 4 4 золотых знака 15 15 серебряных знаков 35 35 бронзовых знаков
А они не нужны. Попробуйте: printf («%d\n»,’A’); printf («%c\n»,90); и Вы убедитесь, что символ и его ASCII код это одно и то же.
10 авг 2011 в 19:24
Мне нужно считать символ, который явялвется const char *, от него отнять 65(‘A’), таким образом если прийдет на вход «A», то получится 0(координата первого элемента массива). Пример: char c; int x=c-‘A’; cin>>c; Таким образом мы получим в с — символ типа сonst char *, компилятор выдаст ошибку «cant convert const char * to int». Поетому мне нужно чтобы ASCII код символа был в переменной, дабы выполнить математические действия над ним.
10 авг 2011 в 19:50
. А кавычки точно те поставили? > Мне нужно считать символ, который явялвется const char * бред. Символ не может быть const char*. Это указатель на константную строку (массив символов).
Язык Си в примерах/ASCII-коды символов
Дано произвольная кодовая (октетная) последовательность (возможно — в коде ASCII) на стандартном вводе программы. Последовательность конечна, но ее длина заранее неизвестна. Надо вывести на стандартный вывод дамп последовательности — разделенные пробельными символами числовые значения считанных кодов.
Решение править
#include #include int main () int c; while ((c = getchar ()) != EOF) printf (" %3d%s", c, (c == '\n' ? "\n" : "")); > assert (! ferror (stdin)); return 0; >
Главный цикл этой программы напоминает таковой для рассмотренной в разделе Максимум; в частности, мы вновь используем цикл «пока» ( while ). [1] Однако, вместо scanf для чтения чисел, здесь мы обращаемся к функции getchar для чтения отдельных знаков (кодов.) [2] Мы по-прежнему используем printf — для вывода кода символа в десятичной записи. [3]
С другой стороны, из условия корректности ввода исключается требование возврата именно EOF (как признака исчерпания входного потока), поскольку это условие уже является условием завершения главного цикла. Это различие связано с тем, что в данной программе не требуется опозновать «подходящий» ввод — допустимой является совершенно любая последовательность символов (кодов.) Напротив, в предыдущей программе мы принимали исключительно целые числа в десятичной записи.
Требование ложности значения функции признака ошибки ferror для стандартного ввода ( stdin ) по завершении главного цикла остается в силе. [4]
Подчеркнем, что диапазон возвращаемых функцией getchar значений — это диапазон «символьного» типа char плюс одно значение, а именно — признак конца потока EOF . [2] Как следствие, иногда встречаемое в примерах кода чтение символа из потока непосредственно в переменную типа char не вполне корректно — для этих целей следует всегда использовать переменную типа int .
Обратите внимание, что сформировать условие «конец потока» при вводе с клавиатуры можно вводом (в зависимости от системы и предполагая настройки по-умолчанию) Control-d или Control-z (также обозначаются C-d , ^D , C-z , ^Z .)
Задания править
- Проверьте работу программы вводом строки Hello! В коде ASCII, выводом программы окажется 72 101 108 108 111 33 10 (где 10 — управляющий код разрыва строки.)
- Введите строку Привет! . В зависимости от системы и ее настроек (так называемой локали), вывод может содержать 8 (при использовании однобайтных кириллических кодировок) или 14 кодов (UTF-8).
- Изучите коды, формируемые такими клавишами и сочетаниями, как ESC , F5 , ↑ , Alt-x , Control-r .
- Исследуйте работу программы на «нетекстовых» потоках небольшого (до примерно 500 байт) объема — изображениях ( .png , .jpeg ), упакованных файлах ( .gz , .bz2 ) и др. Попробуйте установить закономерности. (Указание: обратите внимание на значения первых пяти—десяти кодов.)
- Предложенный вариант программы разрывает ( \n ) выходные строки по границам входных. Реализуйте также разрыв выходных строк по достижению определенного количества выведенных в одной строке кодов (например, каждые 16.)
- Разработайте варианты программы, выводящие считанные коды в шестнадцатиричном и восьмеричном представлениях. (Указание: воспользуйтесь материалом раздела Скалярные типы.)
- Напишите программу, которая печатает все символы и их ASCII-коды.
- Попробуйте напечатать как символ число больше 255. Что получается?
- Ознакомьтесь с описанием программы od в стандарте POSIX и в документации к пакету GNU Coreutils. [5][6]
См. также править
- Кодирование текста
- ASCII
- http://asciitable.com/
- http://digteh.ru/proc/text.php — запись текстов (букв) двоичным кодом.
Примечания править
- ↑6.8.5.1 The while statement (англ.) WG14 N1570 Committee Draft. ISO/IEC (2011-04-12). Проверено 2012-11-19 г.
- ↑ аб7.21.7.6 The getchar function (англ.) WG14 N1570 Committee Draft. ISO/IEC (2011-04-12). Проверено 2012-11-19 г.
- ↑7.21.6.1 The fprintf function (англ.) WG14 N1570 Committee Draft. ISO/IEC (2011-04-12). Проверено 2012-11-19 г.
- ↑7.21.10.3 The ferror function (англ.) WG14 N1570 Committee Draft. ISO/IEC (2011-04-12). Проверено 2012-11-19 г.
- ↑od – dump files in various formats (англ.) IEEE Std 1003.1-2013. The IEEE and The Open Group. Проверено 2015-03-13 г.
- ↑od invocation (англ.) GNU Coreutils. Free Software Foundation. Проверено 2015-03-13 г.
ASCII: объяснение и примеры

Код ASCII кодирует символы, чтобы определить их представление электронными устройствами, такими как ПК. Для этого отдельные символы преобразуются в двоичные, десятичные и шестнадцатеричные значения, которые компьютер может обрабатывать.
Что такое ASCII?
ASCII — это стандарт для представления символов электронными устройствами. Чтобы лучше понять, что это значит, необходимо знать, как работает компьютер. В компьютере вычислительные процессы всегда основаны на двоичной системе. Это означает: единицы и нули определяют процессы в компьютере. ASCII тоже основан на этой системе. Оригинальный стандарт ASCII определяет различные символы в пределах семи бит — то есть семи цифр, обозначающих либо 0, либо 1.
Определение
Кодирование символов — это американский стандартный код для обмена информацией, который является предшественником ISO 646 (международные наборы символов). ASCII — это 7-битный код, что означает, что определено 128 символов (27). Код состоит из 33 непечатаемых и 95 печатаемых символов и включает в себя буквы, знаки препинания, цифры и управляющие символы.
Восьмой бит, составляющий один полный байт, традиционно используется для проверки. Расширенные версии на основе ASCII используют именно этот бит, чтобы расширить количество доступных символов до 256 (2 8 ).
Первоначальное назначение восьмого бита — проверка данных на наличие ошибок. Бит «четности» позволяет приемнику битовой последовательности обнаружить несоответствия. Однако видимым является только то, что произошло, а не причина ошибки. Это делает проверку на четность довольно непригодной для исправления ошибок.
Каждый символ соответствует семизначной последовательности нулей и единиц, которая затем может быть представлена как десятичное число или как шестнадцатеричное. Символы ASCII можно разделить на несколько групп.
- Управляющие символы (0-31 & 127): Управляющие символы не являются печатаемыми символами. Они используются для передачи команд на компьютер или принтер и основаны на технологии телексной связи. С помощью этих символов можно устанавливать разрывы строк или табуляции. Сегодня они в основном не используются.
- Специальные символы (32-47 / 58-64 / 91-96 / 123-126): К специальным символам относятся все печатные знаки, которые не являются ни буквами, ни цифрами. К ним относятся знаки препинания или технические, математические символы. ASCII также включает пробел (невидимый, но печатаемый символ), и поэтому не относится к категории управляющих символов, как можно было бы предположить.
- Цифры (30-39): Эти цифры включают десять арабских цифр от 0-9.
- Буквы (65-90 / 97-122): Буквы разделены на два блока, первая группа содержит прописные буквы, а вторая — строчные.
Чтобы без труда перевести символы в код ASCII, стоит обратиться к таблице ASCII, которая содержит двоичные, десятичные и шестнадцатеричные значения для каждого символа.
Пример: Коды ASCII
В системе ASCII двоичные числа преобразуются в печатаемые и непечатаемые символы в соответствии с заданным стандартом.
Если вы посмотрите на таблицу ASCII, вы найдете символы, представленные для различных числовых значений.
Двоичное число 01000001 может быть записано в десятичном виде как 65, в шестнадцатеричном — как 41. Символ, закодированный этим числом, — буква «A». Если теперь вести отсчет дальше, то вы обнаружите заглавные буквы, перечисленные в алфавитном порядке. Таким образом, слову «ASCII» будут соответствовать следующие числовые значения:
В Windows можно вводить символы Unicode — то есть символы ASCII — с помощью комбинации клавиш. Для этого, удерживая нажатой клавишу Alt, введите десятичное значение символа с помощью цифровой клавиатуры.
Код ASCII: преимущества и области применения
ASCII широко используется и сегодня, несмотря на то, что UTF-8 стал более важным при представлении текста. Однако Unicode вытесняет старый метод кодирования символов, использовавшийся в первые дни существования Интернета, только с 2008 года. Преимущество использования UTF-8 заключается в том, что код практически обратно совместим: ASCII является подмножеством UTF-8, поэтому первые 128 символов идентичны. Поскольку ASCII можно считать наименьшим общим знаменателем большинства новых форм кодирования, старый метод кодирования по-прежнему используется в электронных письмах и URL-адресах.
Теперь пользователи могут использовать Юникод при создании электронных писем, и даже домены могут использовать умляуты благодаря интернационализации доменных имен. Однако в обоих случаях перед передачей текст должен быть преобразован в ASCII. Обычно это делается автоматически, и пользователи ничего не замечают.
Кроме того, ASCII уже давно используется как в художественных, так и в технических целях: Искусство ASCII использует исключительно печатаемые символы кода ASCII для создания творческих работ. Спектр варьируется от надписей до простых фигурок и настоящих картин. Художники ASCII используют различные уровни яркости отдельных символов для создания света и тени в своих произведениях.
Краткая история кодов ASCII
Американская ассоциация стандартов (ASA, сейчас известна как ANSI, что означает «Американский национальный институт стандартов») утвердила Американский стандартный код для обмена информацией (ASCII) в 1963 году. Он устанавливает обязательную спецификацию того, как электронные устройства должны представлять символы. Поскольку стандарт является американским, его часто называют US ASCII.
Его предшественниками были азбука Морзе и коды, используемые в телексах, где стандартизированный код (например, фиксированная последовательность акустических сигналов) переводится в текст. Поскольку компьютеры не могут работать с нашим алфавитом, так как их внутренние процессы основаны на двоичной системе, был введен стандарт ASCII.
По сей день этот стандарт редко изменяется, чтобы адаптироваться к новым требованиям. Например, существуют расширенные версии, в которых используется восьмой бит, чтобы можно было представить национальные особенности, такие как немецкие умляуты (ä, ö и ü). Латиница-1 (ISO 88591-1), которая все еще популярна в Германии, основана на коде ASCII.
Однако до сих пор невозможно переключаться между латинским алфавитом и, например, арабскими символами. Для этого в настоящее время уже созданы наборы символов, основанные в основном на Unicode, такие как UTF-8. Unicode предоставляет место для более чем миллиона различных символов. UTF-8 также совместим с ASCII, кодируя первые 128 символов таким же образом.