Как на MySQL сделать небольшую модель соцсети?
Здравствуйте. Вопрос, как реализовать хранение id друзей для каждого id? Например есть у меня 7000 юзверей, для их id я создаю таблицу, с primary key от id, или хеша какого-нибудь уникального от того же id. А как правильно хранить друзей каждого id?

Eof
23.03.17 18:07:59 MSK
В другой таблице.
anonymous
( 23.03.17 18:51:07 MSK )

Храни в отдельной таблице ManyToMany отношение.
orm-i-auga ★★★★★
( 23.03.17 18:52:48 MSK )
Забавный топик, лакмусовый.
emptykiev
( 24.03.17 10:35:45 MSK )

Поставить mysql workbench с офф сайта?
artb1sh ★
( 24.03.17 23:20:20 MSK )

Для начала — почитать про реляционные базы данных. Хотя бы самые азы.
morse ★★★★★
( 24.03.17 23:33:27 MSK )
Ну можно завести поле friends и ложить туда строку из склеенных через пробелы идентификаторов. Или заделать файл friends/id.txt и ложить в него массив друзей, или создать табличку friends и делать там записи с ключем id_holder_friend_of_friend_id и проверять существование идентификатора. если есть — значит друзья. идей много придумать можно, что, ни одной не получилось? все из-за mysql? можно написать скрипт который сгенерит в таблице пользователей поля с именем-идентификатором и расставлять в них 1 если пересечение полей друзья
id | name | id_1 | id_2 | id_3 1 | foo | — | — | 1
— users with id1 and id3 are friends!
emptykiev
( 26.03.17 07:39:18 MSK )
Да можно создать массив friends в глобальной перменной и загружать-созранять при запуске программы!
emptykiev
( 26.03.17 07:40:34 MSK )
Ответ на: комментарий от morse 24.03.17 23:33:27 MSK
Посоветуй конкретно книгу которую можно купить, только не 600 страниц чтобы.
Как правильно хранить друзей?
Всем привет! Столкнулся с таким вопросом. Сделал таблицу пользователей и таблицу друзей.
Таблица друзей выглядит так:
id — ID записи в таблице
user_id — пользователь отправивший заявку
friend_id — пользователь которому отправили заявку
status — 1 == друг, 2 == еще не принятая заявка
Все бы ничего, но когда нам нужно проверить, является ли один пользователь другом второго, приходится делать вот такой страшный запрос, потому как пользователь мог пригласить и пользователя могли пригласить в друзья.
SELECT f.`status` FROM `friends` f WHERE (f.`user_id` = 111 AND f.`friend_id` = 222) OR (f.`user_id` = 222 AND f.`friend_id` = 111)Так же проблема возникает, когда нужно сделать JOIN, приходится делать такой:
LEFT JOIN `friends` ON (f.`user_id` = 111 AND f.`friend_id` = 222) OR (f.`user_id` = 222 AND f.`friend_id` = 111)И хуже всего, когда нужно вывести список друзей (для пользователя 111), тогда в SELECT приходится добавлять что-то подобное, чтобы получить ID друга:
IF(f.`user_id` = 111, f.`friend_id`, f.`user_id`) as friend_id- Вопрос задан более трёх лет назад
- 435 просмотров
2 комментария
Простой 2 комментария
Оптимальная структура БД для дружбы пользователей
Основные таблицы базы данных, аналогичной Facebook, включают: users (пользователи), posts (посты) и comments (комментарии) – отвечают за взаимодействия пользователей, и friendships (дружба) – отражает дружественные связи пользователей. Основой структуры таблиц служат внешние ключи и индексированные столбцы, которые обеспечивают быстрый поиск, в частности, по идентификаторам. Примерная схема может выглядеть следующим образом:
Скопировать код
-- Пользователи являются основой нашей базы данных. CREATE TABLE users (user_id INT PRIMARY KEY, name VARCHAR(100)); -- Посты – инструменты внимания пользователей. CREATE TABLE posts (post_id INT PRIMARY KEY, user_id INT REFERENCES users(user_id), content TEXT); -- Комментарии – потому что всем нужно живое общение. CREATE TABLE comments (comment_id INT PRIMARY KEY, post_id INT REFERENCES posts(post_id), user_id INT REFERENCES users(user_id)); -- Дружба – она становится началом и концом любого общения в сети. CREATE TABLE friendships (user_id1 INT, user_id2 INT, status ENUM('requested', 'accepted'), PRIMARY KEY (user_id1, user_id2));В центре внимания такой подход помещает производительность и масштабируемость – критически важные аспекты для обработки больших объемов данных и обслуживания многочисленных пользователей. Это подходящий старт для дальнейшего усовершенствования и реализации сложных функций.
Улучшение производительности и масштабируемости
Таблицы дружественных связей часто громоздки и запутаны. При описании каждой дружбы следует вводить две записи – одну для каждого пользователя, чтобы сохранить симметрию при поиске друзей. Композитный первичный ключ (user_id1, user_id2) способствует целостности данных и повышает эффективность поиска.
Скопировать код
-- Понимаем внутренний код дружбы. ALTER TABLE friendships ADD CONSTRAINT fk_user_id1 FOREIGN KEY (user_id1) REFERENCES users(user_id); ALTER TABLE friendships ADD CONSTRAINT fk_user_id2 FOREIGN KEY (user_id2) REFERENCES users(user_id);Для управления сложными отношениями полезными будут графовые базы данных, например, Neo4j. В реляционных базах данных рекомендуется использовать оптимизированные индексы и партиционирование таблиц для эффективной обработки больших объёмов данных.
CQRS (command query responsibility segregation) паттерны разделяют операции записи и чтения, улучшая масштабируемость системы и повышая эффективность асинхронных операций пользователей. Кроме того, можно задействовать Redis для управления сессиями и использования в качестве альтернативы основной базе данных.
Разработка надёжной и масштабируемой архитектуры
Трансформация от монолитной архитектуры к микросервисам позволяет заменить громоздкую и негибкую систему на мелкозернистые, удобные для контроля и независимо масштабируемые сервисы. Каждый такой микросервис берет на себя конкретную задачу, например, управление учетными записями пользователей, распространение контента или обмен сообщениями.
NoSQL базы данных, такие как Cassandra или MongoDB, обеспечивают гибкость структуры данных и подходят для хранения неструктурированных данных (вроде постов или активности пользователей), облегчая задачу горизонтального масштабирования.
Добавление полей, отображающих изменения, например, времени создания или обновления записей в таблицу friendships, дополняет её и позволяет учесть возможные несоответствия данных.
Применение продвинутых запросов и анализ данных
Вкладывание усилий в графовые алгоритмы позволяет улучшить работу с социальными связями. Методы, такие как поиск в глубину (DFS) или поиск в ширину (BFS), могут быть полезны при анализе сети знакомств пользователей и рекомендации друзей.
Таблица users должна иметь надёжный первичный ключ user_id, а user_email следует использовать как уникальный ключ для идентификации, что обеспечивает целостность данных. Проводите регулярные оптимизационные работы и возвращайтесь к схеме, проработанной Лубарским, чтобы глубже понять архитектуру Facebook.
Визуализация
Визуализация дизайна базы данных Facebook напоминает сложную экосистему леса:
Хранение ваших данных
Нашим друзьям, изучающим физику, повезло меньше. Термометр не может измерить температуру в непосредственно заданное время. Температура распространяется не мгновенно, поэтому все, что мы можем получить — среднюю температуру за какой-то период. И чем больше мы будем сужать этот период, тем дороже нам придется заплатить за оборудование. Так или иначе, это не застрахует нас от погрешностей и неисправностей.
Мы же с вами можем делать столько дискретных измерений, сколько пожелаем. Мы даже можем на ходу менять измерения, полагаясь на сложную логику. И, конечно, мы знаем, как работать с большими массивами данных. Так зачем же мы от них избавляемся? Вот, посмотрите на документацию одного популярного инструмента для анализа RRDtool:
Вы заметили, что в созданной нами базе мы использовали усреднение, зачем? Оказывается, если мы будем записывать данные каждую секунду, а потом захотим вывести среднее значение за год, то вычисления и сам процесс выборки из БД может потребовать большое количество ресурсов. Чтобы избежать этого, в RRDtool консолидация данных происходит при записи, а не во время считывания. Использование разных функций консолидации позволяет вам сохранять только те данные, которые вам нужны: максимальная нагрузка на канал LAN в течении одной минуты, минимальная температура вашего винного погреба, количество минут простоя.
RRDtool
Такой подход в корне неверен. И не только из-за пространственных суждений об оптимизации. Выбрасывать исходные данные и оставлять только собранную метрику во избежание захламления диска — очень непродуманно.
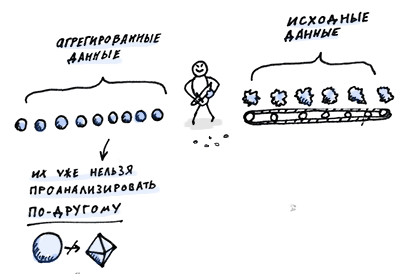
В замену сохраненному месту на диске вы впадаете в зависимость от потребности предугадывать результат. Такой подход сработает разве что если вам нужно посчитать «максимальную нагрузку на канал в течении одной минуты» и больше ничего. Если потом вам понадобится узнать, какая была средняя нагрузка или 95-й процентиль, или вам нужно будет сгруппировать данные по протоколу, исключить некоторые хосты, или что-либо еще, — вы не сможете.
Обрабатывать данные и выделять из них нужное — многомерная задача поисковиков. Но ведь мы – программисты. Мы знаем, как решать проблемы с поиском данных. Главное, чтобы была возможность свободно перемещаться между этими мерностями. Невозможно предугадать наперед, какие данные и параметры поиска нам понадобится использовать в будущем. Хранение всех исходных данных может и дорогостоящее удовольствие, но суммарное множество всех возможных вариантов метрик, которые мы сможем извлечь, намного ценней. С другой стороны, полезность исходных данных с каждым годом будет стремительно понижаться.
Есть и способ переосмысления этой задачи. Это то, что случается на пересечении двух сценариев использования. Новая информация должна быть всегда в «высокоэнергетическом» состоянии, очень жидкая и доступная. Напротив, старая информация может быть низкоэнергетической, собранной предварительно и иметь возможность оставаться в стабильном состоянии долгий период времени.
Таким образом, храните исходные данные в очень быстрых БД, но только в первые недели или месяцы использования. У вас всегда будет доступ к этим данным, чтобы провести нужный анализ. Затем вы можете запихнуть их в RRD или что-либо еще для хранения данных на длительной основе. На выходе мы имеем буфер со свежими и актуальными исходными данными для диагностики текущих проблем и предыдущие записи для сверки и сравнения.
Это приводит нас прямиком к системе Scuba, разработанной компанией Facebook. Когда Лиор Авраам и Дэвид Райс преподнесли нам эту идею, она показалась мне абсурдной. Хранить исходные данные в оперативной памяти? Без индексов? Каждый запрос как он есть? Чушь. Это были достаточно тяжелые времена, когда мы вынуждены были умещать все наши данные на дисках. О чем они вообще думали?
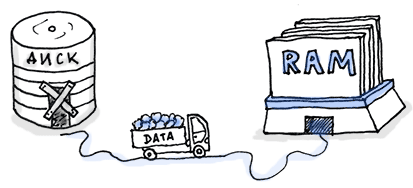
А думали они о будущем. Чопорность инструментов, с которыми ми имели дело в те времена, особенно зависимость от постоянного предугадывания, была нашей повседневной реальностью. Мы могли располагать только несколькими размерностями одновременно, и если проблема таилась где-то еще, мы просто застревали. Добавление других размерностей превращало работу в сплошную головную боль, которая, конечно же, не способствовала решению поставленной задачи. Исходные данные оказывались либо утерянными, либо доступ к ним был затруднен.
Хранение исходных образцов, всех метаданных и измерений в простой таблице в оперативной памяти позволяло делать запрос на любые данные одинаково просто. Это сократило время прохождения цепи обратной связи до секунд, что по-настоящему позволяло проводить исследования в реальном времени. Быстрое устаревание исходных данных стало преимуществом, так как ограничивало необходимое, постоянно иссякающее свободное место для хранения.
Ниже приведено начало README файла для системы анализа разработанной компанией Square, Inc.
Cube — это система сбора событий с присвоенными метками времени и последующим составлением метрики. Собирая события, а не уже готовую метрику, Cube позволяет составлять статистику постфактум. github.com/square/cube
Как же ее создать
Самым простым примером такого рода системы сбора информации может быть поисковая система, которая может составлять статистику. В ее задачи входит эффективное хранение огромного количества «документов» с помощью гибких логических структур, вероятнее всего размещенных на нескольких серверах одновременно. Она должна быстро найти подходящие для обработки данные и потом выдать их в виде количественного показателя, суммы, усредненных значений, процентного соотношения и т.п. В том числе, и разбивая по группам размерностей (например, среднее физическое время всех запросов в течение последних нескольких часов на участке в 5 минут).
Системы такого рода почти всегда гибридные: реальный поисковой движок дополняется статистикой, расширенными статистическими движками или хранилищами с добавлением сверху слоя сбора аналитики. Не думаю, что можно сойтись на одном названии, но, если бы спрашивали меня, то я, скорее всего, назвал бы их «аналитическими движками».
Я вряд ли бы порекомендовал вам для серьезной работы делать свой собственный подобный; в мире уже и так предостаточно подходящих для использования библиотек. Но понимание их внутреннего содержимого через создание своей игрушечной версии поможет понять преимущества систем, построенных вокруг сбора образцов исходных данных.
Самое сложное — это масштабирование таких систем, особенно с функцией статистики, на несколько связанных между собой машин. Мы не будем рассматривать такие варианты. Это позволит нам создать прототип системы меньшей кровью, используя стандартные реляционные БД. Функций статистики часто не хватает, но мы заменим их в полном объеме умным SQL и последующей обработкой данных. Мы также обойдем стороной некоторые принципы построения гибких логических структур во избежание лишней головной боли во время работы со структурами реляционных БД. В одном временном пространстве у нас будет только один индекс. Мы редко когда будем удалять колонки, и не будем выполнять объединения таблиц.
sqlite> .tables derp derp_cache derp_db sqlite> .schema derp CREATE TABLE derp ( timestamp int, script_path string, server_name string, datacenter string, ab_tests string, walltime int, cpu_time int, . Каждый из трех режимов в нашем примере может быть представлен постой таблицей БД. Мы можем отправлять таблицам запросы и получать данные анализа реального времени разного рода запросов на сервере, скажем, за последний час. Вот почему определение слова метрика в предыдущей главе было так схоже с описанием таблицы БД.
sqlite> select script_path, round(avg(walltime)/1000) from derp where timestamp >= 1366800000 and timestamp < 1366800000+3600 group by script_path; /account | 1532.0 /health | 2.0 /home | 1554.0 /pay | 653.0 /share | 229.0 /signup | 109.0 /watch | 459.0 Как только пользователь входит в приложение под своим профилем, оно проделывает намного больше работы и обрабатывает дополнительные данные, такие как настройки пользователя и просмотр его истории. Таким образом, состояние пользователя играет важную роль в том, какие данные будет обрабатывать приложение. Анализ данных только от небольшого количества анонимных пользователей может помешать обнаружить некоторые проблемные участки кода.
sqlite> select user_state, sum(sample_rate), round(avg(walltime)/1000), round(avg(db_count)) from derp where timestamp . and script_path = '/watch' group by user_state; logged-in | 2540 | 1502.0 | 2.3 anon | 11870 | 619.0 | 0.9 Включение разной информации о среде в логи DERP позволит анализировать производительность большего числа компонентов системы. Загружаются ли сервера равномерно? А как насчет разных дата-центров, в которых они могут находиться? Как только этот набор данных собран, в поле sample_rate будет храниться сумма всех произведенных запросов.
sqlite> select server_name, sum(sample_rate), round(avg(walltime)/1000) from derp where timestamp . group by server_name; web1 | 19520 | 1016.0 web2 | 19820 | 1094.0 . sqlite> select datacenter, sum(sample_rate), round(avg(walltime)/1000) from derp where timestamp . group by datacenter; east | 342250 | 1054.0 west | 330310 | 1049.0 Группируя запросы во временной размерности по 300 секунд, мы сможем увидеть, что заход на страницу /health, цель которой показывать нам, что сервер работоспособен и отвечает на запросы, показывает вполне стабильную производительность, что от него и ожидается.
sqlite> select group_concat(round(avg(walltime)/1000, 1), ', ') from derp where timestamp . and script_path = '/health' group by timestamp/(60*5); 1.5, 2.1, 2.2, 1.3, 1.3, 1.3, 1.4, 1.1, . Разве это не прекрасно? Все эти и тысячи других измерений мы можем проводить, исследуя одну и ту же таблицу с исходными данными. Простота запросов тоже очень кстати. Мы можем с легкостью превратить все эти цифры в диаграмму или график. Что вскоре и сделаем.
Вкратце о моделировании данных
Давнее противостояние между приверженцами реляционных моделей данных и пространственным моделированием сходится по числу требуемых объединений таблиц для завершения процедуры анализа. Другими словами, это спор на счет производительности.

Что ж, мы уже в курсе, что делать с проблемами производительности. Принцип «определи проблему и проведи анализ» одинаково применим ко всем системам, построенным для измерений. Простая, описанная выше структура таблиц очень редко разменивает место на время: она не использует объединения таблиц, так как все необходимые метаданные уже присоединены к образцу. Выглядит хорошо, но внешность иногда бывает крайне обманчивой.
Как только ваша система измерений начнет расти и развиваться, вы поймете, что вас вряд ли устроит структура, накапливающая тонны таких лишних метаданных как тип чипсета, модель, номер статива и так далее в том же духе. Вместо этого вы, скорее всего, с удовольствием соедините несколько таблиц с нужными данными в одну. Смысл в том, что нужно усложнять свою систему там, где это требуется, а не там, где это якобы положено делать. Тут главное не перемудрить.
Профессиональный фестиваль "Российские интернет-технологии" — весь спектр индустрии веб-разработки от системного администрирования до управления проектами и высоконагруженных систем, а также клиентское программирование, базы данных и системы хранения, тестирование и качество. Всё это вокруг бесплатной технологической выставки.
Флагманская конференция, самое крупное профессиональное мероприятие для разработчиков Интернет-проектов в России и одно из крупнейших во всём мире! Программа охватывает такие аспекты веб-разработок, как архитектуры крупных проектов, базы данных и системы хранения, системное администрирование, нагрузочное тестирование, эксплуатация крупных проектов и другие направления, связанные с высоконагруженными системами.