Разница между стеком и очередью

Стек и Очередь оба являются непримитивными структурами данных. Основные различия между стеком и очередью заключаются в том, что в стеке используется метод LIFO (последний пришел первым вышел) для доступа и добавления элементов данных, тогда как в очереди используется метод FIFO (первый пришел первым вышел) для доступа и добавления элементов данных.
С другой стороны, в стеке открыт только один конец для перемещения и извлечения элементов данных. В очереди имеются открытые оба конца для постановки в очередь и удаления из очереди элементов данных.
Стек и очередь — это структуры данных, используемые для хранения элементов данных, и фактически они основаны на каком-то реальном эквиваленте. Например, стопка — это стопка компакт-дисков, где вы можете извлечь и вставить компакт-диск через верх стопки компакт-дисков. Аналогично, очередь представляет собой очередь для билетов в театр, где человек, стоящий на первом месте, т. Е. Сначала будет обслужен фронт очереди, а прибывающий новый человек появится в задней части очереди (задний конец очереди).
Сравнительная таблица
| Основа для сравнения | стек | Очередь |
|---|---|---|
| Принцип работы | LIFO (последний пришел первым вышел) | FIFO (первый на первом) |
| Состав | Тот же конец используется для вставки и удаления элементов. | Один конец используется для вставки, т. Е. Задний конец, а другой конец используется для удаления элементов, т. Е. Передний конец. |
| Количество использованных указателей | Один | Два (в простом случае очереди) |
| Выполненные операции | Push и Pop | Ставить в очередь и оставлять в очередь |
| Экспертиза пустого состояния | Топ == -1 | Фронт == -1 || Фронт == Тыл + 1 |
| Экспертиза полного состояния | Топ == Макс — 1 | Задний == Макс — 1 |
| Варианты | У него нет вариантов. | У этого есть варианты как круговая очередь, приоритетная очередь, дважды законченная очередь. |
| Реализация | Simpler | Сравнительно сложный |
Определение стека
Стек — это не примитивная линейная структура данных. Это упорядоченный список, в который добавляется новый элемент, а существующий элемент удаляется только с одного конца, называемого вершиной стека (TOS). Поскольку все удаление и вставка в стек выполняется с вершины стека, последний добавленный элемент будет первым, который будет удален из стека. По этой причине стек называется списком типа «последний пришел — первым обслужен» (LIFO).
Обратите внимание, что элемент, к которому часто обращаются в стеке, является самым верхним элементом, тогда как последний доступный элемент находится в нижней части стека.
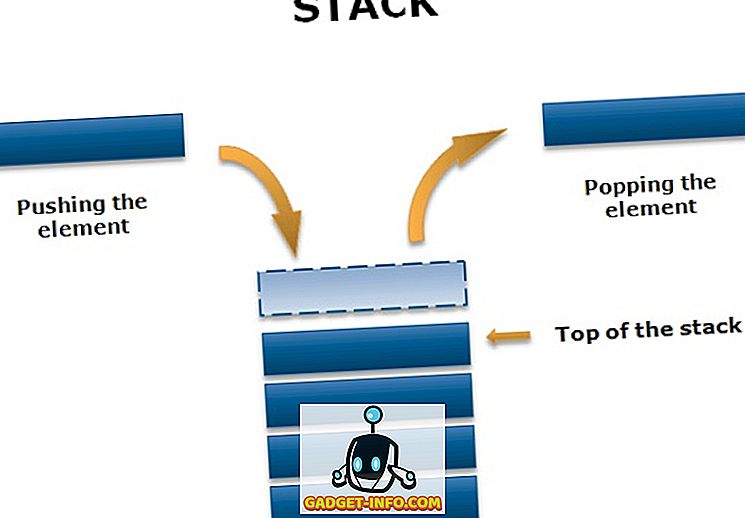
пример
Некоторые из вас могут есть печенье (или Поппинс). Если вы предполагаете, порвана только одна сторона крышки, и печенье вынимается одна за другой. Это то, что называется хлопаньем, и аналогичным образом, если вы хотите сохранить печенье в течение некоторого времени позже, вы положите его обратно в пачку через тот же порванный конец, называемый толканием.
Определение очереди
Очередь с линейной структурой данных относится к категории непримитивного типа. Это коллекция элементов подобного типа. Добавление новых элементов происходит на одном конце, называемом задним концом. Точно так же удаление существующих элементов происходит на другом конце, называемом Front-end, и это логически тип списка «первым пришел — первым обслужен» (FIFO).
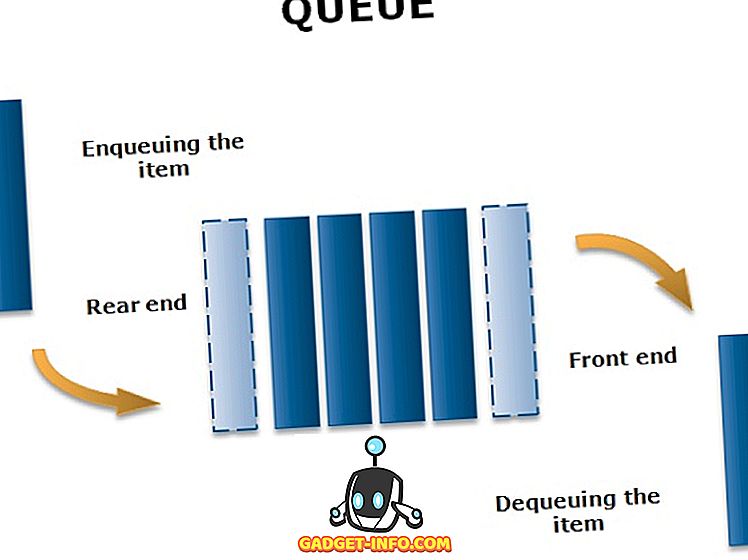
пример
В нашей повседневной жизни мы сталкиваемся со многими ситуациями, когда нам приходится ждать желаемого обслуживания, и мы вынуждены стоять в очереди на обслуживание своей очереди. Эту очередь ожидания можно рассматривать как очередь.
Ключевые различия между стеком и очередью
- Стек следует за механизмом LIFO с другой стороны. Очередь следует за механизмом FIFO для добавления и удаления элементов.
- В стеке один и тот же конец используется для вставки и удаления элементов. Напротив, два разных конца используются в очереди для вставки и удаления элементов.
- Поскольку в стеке есть только один открытый конец, это является причиной использования только одного указателя для ссылки на вершину стека. Но очередь использует два указателя для ссылки на передний и задний конец очереди.
- Стек выполняет две операции, известные как push и pop, а в очереди его называют enqueue и dequeue.
- Реализация стека проще, тогда как реализация очереди сложна.
- Очередь имеет варианты, такие как круговая очередь, приоритетная очередь, очередь с двойным окончанием и т. Д. В отличие от стека нет вариантов.
Реализация стека
Стек может быть применен двумя способами:
- Статическая реализация использует массивы для создания стека. Статическая реализация, хотя и является легким методом, но не гибким способом создания, так как объявление размера стека должно быть сделано во время разработки программы, после чего размер не может быть изменен. Кроме того, статическая реализация не очень эффективна в отношении использования памяти. Поскольку массив (для реализации стека) объявляется до начала операции (во время разработки программы). Теперь, если количество элементов, подлежащих сортировке, в стеке очень мало, статически выделенная память будет потрачена впустую. С другой стороны, если в стеке будет храниться больше элементов, мы не сможем изменить размер массива, чтобы увеличить его емкость, чтобы он мог вместить новые элементы.
- Динамическая реализация также называется представлением связанного списка и использует указатели для реализации стекового типа структуры данных.
Реализация очереди
Очередь может быть реализована двумя способами:
- Статическая реализация : если очередь реализована с использованием массивов, точное количество элементов, которые мы хотим сохранить в очереди, должно быть заранее определено, поскольку размер массива должен быть объявлен во время разработки или до начала обработки. В этом случае начало массива станет передней частью очереди, а последнее местоположение массива будет действовать в качестве задней части очереди. Следующее отношение дает всем элементам, существующим в очереди, при реализации с использованием массивов:
спереди — сзади + 1
Если задний , то в очереди не будет элементов, или очередь всегда будет пустой. - Динамическая реализация . При реализации очередей с использованием указателей основным недостатком является то, что узел в связанном представлении потребляет больше памяти, чем соответствующий элемент в представлении массива. Поскольку в каждом узле имеется по меньшей мере два поля, одно для поля данных, а другое для хранения адреса следующего узла, тогда как в связанном представлении присутствует только поле данных. Преимущество использования связанного представления становится очевидным, когда требуется вставить или удалить элемент в середине группы других элементов.
Операции над стеком
Основные операции, которые могут выполняться в стеке:
- PUSH : когда новый элемент добавляется на вершину стека, называется операцией PUSH. Нажатие элемента в стеке вызывает добавление элемента, так как новый элемент будет вставлен сверху. После каждой операции толчка верх увеличивается на единицу. Если массив заполнен и новый элемент не может быть добавлен, это называется условием STACK-FULL или STACK OVERFLOW. РАБОТА С НАЖИМОМ — функция в С:
Учитывая стек объявлен как
int stack [5], top = -1;
void push()
<
int item;
if (top < 4)
<
printf («Enter the number») ;
scan («%d», & item) ;
top = top + 1;
stack [top] = item;
>
else
<
printf (» Stack is full»);
>
> - POP : когда элемент удаляется из верхней части стека, он называется операцией POP. Стек уменьшается на единицу после каждой операции pop. Если в стеке не осталось элемента и выполняется всплывающее окно, это приведет к условию STACK UNDERFLOW, означающему, что ваш стек пуст. POP OPERATION — функции в C:
Учитывая стек объявлен как
int stack [5], top = -1;
void pop()
<
int item;
if (top >= 4)
<
item = stack [top];
top = top — 1;
printf («Number deleted is = %d», item) ;
>
else
<
printf (» Stack is empty»);
>
>
Операции в очереди
Основные операции, которые могут быть выполнены в очереди:
- Постановка в очередь : для вставки элемента в очередь. Операция постановки в очередь в C:
Очередь объявлена как
int queue [5], Front = -1 and rear = -1;
void add ()
<
int item;
if ( rear < 4)
<
printf («Enter the number») ;
scan («%d», & item) ;
if (front == -1)
<
front =0 ;
rear =0 ;
>
else
<
rear = rear + 1;
>
queue [rear] = item ;
>
else
<
printf («Queue is full») ;
>
> - Исключение : Для удаления элемента из очереди. Функция операции извлечения в C:
Очередь объявлена как
int queue [5], Front = -1 and rear = -1;
void delete ()
<
int item;
if ( front ! = -1)
<
item = queue [ front ] ;
if (front == rear)
<
front =-1 ;
rear =-1 ;
>
else
<
front = front + 1;
printf («Number deleted is = %d», item) ;
>
>
else
<
printf («Queue is empty») ;
>
>
Приложения стека
- Разбор в компиляторе.
- Виртуальная машина Java.
- Отменить в текстовом редакторе.
- Кнопка «Назад» в веб-браузере.
- Язык PostScript для принтеров.
- Реализация вызовов функций в компиляторе.
Приложения очереди
- Буферы данных
- Асинхронная передача данных (файловый ввод-вывод, каналы, сокеты).
- Распределение запросов по общему ресурсу (принтер, процессор).
- Анализ трафика.
- Определите количество кассиров в супермаркете.
Заключение
Stack и Queue — это линейные структуры данных, отличающиеся определенными способами, такими как рабочий механизм, структура, реализация, варианты, но оба они используются для хранения элементов в списке и выполнения операций в списке, таких как добавление и удаление элементов. Хотя есть некоторые ограничения простой очереди, которая возмещается с использованием других типов очереди.
Разница между массивом, очередью и стеком
Массив — это набор элементов, хранящихся в непрерывных ячейках памяти. Идея состоит в том, чтобы хранить вместе несколько предметов одного типа. Это упрощает вычисление положения каждого элемента, просто добавляя смещение к базовому значению, то есть к месту в памяти первого элемента массива (обычно обозначаемого именем массива).
Схематическое изображение массива приведено ниже:
Очередь:
Очередь — это линейная структура, которая следует определенному порядку выполнения операций. Порядок действий — « первым пришел — первым обслужен» (FIFO) . Хорошим примером очереди является любая очередь потребителей ресурса, в которой первым обслуживается потребитель, пришедший первым. Разница между стеками и очередями заключается в удалении. В стеке мы удаляем последний добавленный элемент; в очереди мы удаляем элемент, который добавлялся не так давно.
Схематическое изображение очереди приведено ниже:
Куча:
Стек — это линейная структура данных, в которой элементы можно вставлять и удалять только с одной стороны списка, называемой верхней . Стек следует принципу LIFO (Last In First Out), т. Е. Элемент, вставленный последним, является первым выходящим элементом. Вставки элемента в стек вызывается нажатием операции, а также удаление элемента из стека называется поп — операцией. В стеке мы всегда отслеживаем последний элемент, присутствующий в списке, с помощью указателя, называемого top .
Схематическое изображение стека приведено ниже:
Ниже представлено табличное представление различий между массивом, стеком и очередью:
Очередь и стек — Основы алгоритмов и структур данных
Мы привыкли записывать математические выражения, опираясь на приоритет операций и на скобки. Именно поэтому:
Далеко не все помнят из школьной математики приоритеты сложения и умножения, поэтому в социальных сетях распространены задачи «Сколько будет
Польский математик Ян Лукасевич около ста лет назад предложил необычный способ записи выражений, в котором не нужны ни приоритеты операций, ни скобки. Сейчас этот способ называют обратной польской записью.
Обратная запись непривычна и не получила широкого распространения, но ее можно встретить в таких языках программирования, как Forth и PostScript.
В обратной польской записи знак операции записывается не между операндами, а после них. Посмотрим, как это выглядит на примерах:
- Обычная запись — , обратная —
- Обычная запись — , обратная —
Операторы в обратной записи не всегда должны быть в конце. Например,
можно записать так:
Эта запись читается слева направо и воспринимается так:
- Число
- Число
- Операция сложения
- Число
- Число
- Операция сложения
- Операция умножения
Преимущество обратных выражений в том, что они не вызывают разночтения.
Чтобы разобраться на примере, дальше мы пошагово вычислим это выражение:
Шаг 1. Берем из стопки два верхних числа —
. Выполняем над ними первую операцию — сложение:
Шаг 2. Идем дальше по выражению — нужно взять следующие два значения и второй оператор. Берем эти значения и применяем к ним вторую операцию сложения:
Шаг 3. Вспомним изначальное выражение:
Мы провели две операции сложения. Оставим только умножение и запишем в выражение результаты первых двух вычислений:
Шаг 4. Проводим последнюю операцию и получаем результат:
Алгоритм вычисления очень прост, но требует новой для нас структуры данных. Представьте, что в вычислениях выше мы бы записывали каждое число на карточки и складывали бы из них стопку. Наверху стопки лежало бы число 45.
В программировании такие стопки называются стеком — от английского stack, то есть стопка или кипа.
В стеке, как и в стопке, мы имеем дело только с верхней карточкой — вершиной. Задача, которую решает стек — запомнить промежуточный результат для будущих вычислений.
В отличие от ранее изученных нами структур, стек обычно реализуют поверх других структур — массива или односвязного списка.
Реализация стека через массив
Реализуя структуру данных, разработчик ради удобства может добавить в нее дополнительные методы.
Разные реализации могут быть непохожи друг на друга, но мы всегда ожидаем найти основные методы — конечно, у разных структур они разные. У стека должны быть реализованы три обязательных метода:
- Метод push() помещает элемент на вершину стека, как карточку наверх стопки
- Метод pop() убирает элемент с вершины и возвращает его
- Метод isEmpty() проверяет, пуст ли стек
В JavaScript методы push() и pop() уже присутствуют в массиве, поэтому мы можем использовать их как есть:
class Stack items = []; push(value) this.items.push(value); > pop() return this.items.pop(); > isEmpty() return this.items.length == 0; > >class Stack: items = [] def push(self, value): self.items.append(value) def pop(self): return self.items.pop() def is_empty(self): return len(self.items) == 0php class Stack public $items = []; public function push($value) array_push($this->items, $value); > public function pop() return array_pop($this->items); > public function isEmpty() return count($this->items) == 0; > >import java.util.List; import java.util.ArrayList; class StackT> ListT> items = new ArrayList<>(); public void push(T item) items.add(item); > public T pop() var lastElementIndex = items.size() - 1; var lastElement = (T) items.get(lastElementIndex); items.remove(lastElementIndex); return lastElement; > public boolean isEmpty() return items.isEmpty(); > >Метод isEmpty() возвращает true , потому что массив пуст — содержит
Воспользуемся нашим стеком, чтобы вычислить значение выражения
let stack = new Stack(); const expression = '3 2 + 4 5 + *'; const lexems = expression.split(' '); for (lexem of lexems) let a; let b; switch (lexem) case '+': b = stack.pop(); a = stack.pop(); stack.push(a + b); break; case '-': b = stack.pop(); a = stack.pop(); stack.push(a - b); break; case '*': b = stack.pop(); a = stack.pop(); stack.push(a * b); break; case '/': b = stack.pop(); a = stack.pop(); stack.push(a / b); break; default: stack.push(parseFloat(lexem)); > > console.log(stack.pop()); // 45stack = Stack() expression = '3 2 + 4 5 + *' lexems = expression.split(' ') for lexem in lexems: # В Python версии 3.10 и выше возможно использовать конструкцию match/case, но в данном случае рассмотрим реализацию через if/else if lexem == '+': a = stack.pop() b = stack.pop() stack.push(a + b) elif lexem == '-': a = stack.pop() b = stack.pop() stack.push(a - b) elif lexem == '*': a = stack.pop() b = stack.pop() stack.push(a * b) elif lexem == '': a = stack.pop() b = stack.pop() stack.push(a / b) else: stack.push(float(lexem)) print(stack.pop()) # 45php $stack = new Stack(); $expression = '3 2 + 4 5 + *'; $lexems = explode(' ', $expression); foreach ($lexems as $lexem) $a; $b; switch ($lexem) case '+': $b = $stack->pop(); $a = $stack->pop(); $stack->push($a + $b); break; case '-': $b = $stack->pop(); $a = $stack->pop(); $stack->push($a - $b); break; case '*': $b = $stack->pop(); $a = $stack->pop(); $stack->push($a * $b); break; case '/': $b = $stack->pop(); $a = $stack->pop(); $stack->push($a / $b); break; default: $stack->push(floatval($lexem)); > > print_r($stack->pop()); // 45var stack = new Stack(); var expression = "3 2 + 4 5 + *"; String[] lexems = expression.split(" "); for (String lexem : lexems) float a; float b; switch (lexem) case "+": b = stack.pop(); a = stack.pop(); stack.push(a + b); break; case "-": b = stack.pop(); a = stack.pop(); stack.push(a - b); break; case "*": b = stack.pop(); a = stack.pop(); stack.push(a * b); break; case "/": b = stack.pop(); a = stack.pop(); stack.push(a / b); break; default: stack.push(Float.parseFloat(lexem)); > > stack.pop(); // 45Как видите, решение не очень сложное. Мы разбиваем строку с выражением на лексемы и обрабатываем каждую лексему в цикле.
Если лексема — это знак операции, то мы «снимаем» с вершины стека два числа, выполняем операцию и помещаем результат обратно на стек.
При выполнении операций важно обращать внимание на порядок чисел. Числа в стеке расположены в порядке, обратном тому, в котором мы их туда помещали. Поэтому сначала мы извлекаем второй операнд b , а потом первый a .
Порядок операндов не важен для таких операций, как сложение и умножение, потому что
. Но при делении это уже не так —
Простейшие структуры данных: стек, очередь, дек
Чаще всего данные, с которыми работают программы, хранятся во встроенных в используемый язык программирования массивах, константной или переменной длины. Массив константной длины можно назвать простейшей структурой данных. Но иногда для решения задачи требуется большая эффективность некоторых операций, чем у массива. В таких случаях используются другие структуры данных, часто гораздо более сложные.
По определению, структура данных — способ представления данных в памяти, позволяющий эффективно выполнять с ними определённый набор операций. Например, простой массив лучше всего подходит для частого обращения к элементам по индексам и их изменению. А удаление элемента из середины массива работает за \(O(N)\). Если вам для решения задачи нужно часто удалять элементы, то придётся воспользоваться другой структурой данной. Например, бинарное дерево ( std::set ) позволяет делать это за \(O(\log N)\), но не поддерживает работу с индексами, только поочерёдный обход всех элементов и поиск по значению (тоже за \(O(\log N)\)).
Таким образом, структура данных характеризуется операциями, которые она может выполнять, и скоростью их выполнения.
В качестве примера рассмотрим несколько простейших структур данных, которые не предоставляют выгоды в эффективности, но имеют чётко определённый набор поддерживаемых операций.
Стек
Стек (англ. stack — стопка) — одна из простейших структур данных, представляющая собой скорее ограничение простого массива, чем его расширение. Классический стек поддерживает всего лишь три операции:
- Добавить элемент в стек (Сложность: \(O(1)\))
- Извлечь элемент из стека (Сложность: \(O(1)\))
- Проверить, пуст ли стек (Сложность: \(O(1)\))
Для объяснения принципа работы стека часто используется аналогия со стаканом с печеньем. Представьте, что на дне вашего стакана лежат несколько кусков печенья. Вы можете положить наверх ещё один кусок или достать уже находящийся наверху. Остальные куски закрыты верхним, и вы про них ничего не знаете. Для описания стека часто используется аббревиатура LIFO (Last In, First Out), подчёркивающая, что элемент, попавший в стек последним, первым будет из него извлечён.
Приведём простую реализацию стека на C++. Для простоты максимальный размер нашего стека будет ограничен тысячей элементов:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22struct stack int a[1000]; int head = -1; //Индекс крайнего элемента. void push(int x) head++; a[head] = x; > int pop() if (head != -1) head--; return a[head + 1]; > else //Ошибка, попытка извлечь элемент из пустого стека. > > bool is_empty() return head == -1; > >;Как видите, для реализации стека хватает одного массива и одного указателя, обозначающего крайний элемент.
Очередь
Очередь поддерживает тот же набор операций, что и стек, но имеет противоположную семантику. Для описания очереди используется аббревиатура FIFO (First In, First Out), так как первым из очереди извлекается элемент, раньше всех в неё добавленный. Название этой структуры говорит само за себя: принцип работы совпадает с обычными очередями в магазине или на почте.
Реализация очереди похожа на реализацию стека, но в этот раз нам понадобятся два указателя: для первого элемента очереди (“головы”) и последнего (“хвоста”):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30struct queue int a[1000]; //Для более лаконичной реализации работы, мы будем //хранить указатель не на последний элемент, а //на следующий за ним (несуществующий). //Это, в частности, позволит нам проверять очередь на пустоту //простым условием head == tail int head = 0; //Индекс первого элемента. int tail = 0; //Индекс элемента, следующего за последним. void push(int x) a[tail] = x; tail++; > int pop() if (head != tail) head++; return a[head - 1]; > else //Ошибка, попытка извлечь элемент из пустой очереди. > > bool is_empty() return head == tail; > >;При такой реализации очередь будет постепенно “ползти” вправо по выделенной области памяти (массиву), и достаточно быстро выйдет за её границы. Впрочем, эта реализация иллюстративная, на практике вы просто будете использовать уже готовую реализацию очереди из стандартной библиотеки (об этом ниже). В ней этот дефект отсутствует из-за более сложной работы с памятью.
Дек
Структура, объединяющая стек и очередь, называется дек (англ. deque - сокращение от double-ended queue, очередь с двумя концами). Как можно догадаться, она поддерживает уже знакомый набор операций:
- Добавить элемент в начало дека (Сложность: \(O(1)\))
- Извлечь элемент из начала дека (Сложность: \(O(1)\))
- Добавить элемент в конец дека (Сложность: \(O(1)\))
- Извлечь элемент из конца дека (Сложность: \(O(1)\))
- Проверить, пуст ли дек (Сложность: \(O(1)\))
В принципе мы можем реализовать её таким же способом, как и две предыдущих, но как и в случае с очередью, эта реализация будет далека от оптимальной.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40struct deque int a[2000]; //Используя такие начальные значения индексов, у нас //будет свободная память как слева, так и справа. int head = 1000; //Индекс первого элемента. int tail = 1000; //Индекс элемента, следующего за последним. void push_front(int x) head--; a[head] = x; > void push_back(int x) a[tail] = x; tail++; > int pop_front() if (head != tail) head++; return a[head - 1]; > else //Ошибка, попытка извлечь элемент из пустого дека. > > int pop_back() if (head != tail) tail--; return a[tail]; > else //Ошибка, попытка извлечь элемент из пустого дека. > > bool is_empty() return head == tail; > >;Стек, очередь и дек в стандартной библиотеке C++
Все три структуры данных являются базовыми и относительно часто встречаются в програмировании, поэтому они уже реализованы в стандартной библиотеке в виде трёх шаблонных классов. Пример работы со стеком и очередью:
stackint> s; //создание стека s.push(5); //добавление элемента cout <s.top(); //обращение к верхнему элементу if (!s.empty()) //проверка на пустоту s.pop(); //извлечение элемента (не возвращает значения, //нужно предварительно использовать .top()) > queueint> q; //создание очереди q.push(5); //добавление элемента cout <q.front() <' ' <q.back(); //обращение к первому и последнему элементам if (!q.empty()) //проверка на пустоту q.pop(); //извлечение элемента (не возвращает значения, //нужно предварительно использовать .top()) >С реализацией дека дела обстоят несколько иначе. Стандартный класс std::deque является не классическим деком, а скорее вектором с возможностью вставки и добавления в начало за \(O(1)\). Он поддерживает все операции, поддерживаемые классом std::vector , в том числе обращение к элементу по индексу и итераторы с произвольным доступом. Так что для работы с ним используйте те же методы, что и при работе с вектором.
Более сложные структуры данных
Приведённый выше материал мог вызвать у вас лёгкое недоумение и сомнения в целесообразности всех этих ограничений на обычные массивы. На самом деле, стек, очередь и дек являются лишь простейшими примерами структур данных, не предоставляющими выгоды в скорости выполнения операций. Серьёзным структурам данных посвящены отдельные темы. Стек, очередь и дек призваны проиллюстрировать, что главными характеристиками структуры данных являются набор поддерживаемых операций и скорость их выполнения.
brestprog
Олимпиадное программирование в Бресте и Беларуси