О свойствах положительно определенных матриц
Пармонов, Х. Ф. О свойствах положительно определенных матриц / Х. Ф. Пармонов. — Текст : непосредственный // Молодой ученый. — 2017. — № 15 (149). — С. 109-110. — URL: https://moluch.ru/archive/149/41870/ (дата обращения: 30.04.2024).
Пусть 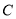 множество комплексных чисел,
множество комплексных чисел, 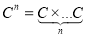 — декартовое произведение, а
— декартовое произведение, а  множество матриц размера
множество матриц размера  с комплексными элементами.
с комплексными элементами.
Если для матрицы 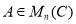 имеет место неравенство
имеет место неравенство 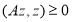 при всех
при всех 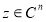 , то матрица
, то матрица  называется положительно определенным. Если выполняется условие
называется положительно определенным. Если выполняется условие 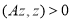 при всех ненулевых
при всех ненулевых 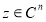 , то матрица называется строго положительно определенным.
, то матрица называется строго положительно определенным.
Если матрица  является положительной, то говорят, что
является положительной, то говорят, что  .
.
Если при всех 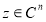 выполняется равенство
выполняется равенство 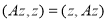 , то матрица называется эрмитовой или самосопряженной.
, то матрица называется эрмитовой или самосопряженной.
Приведем некоторые факты о положительно определенных матриц.
Предложение 1. Матрица является положительной тогда и только тогда, когда она эрмитова и ее все собственные значения неотрицательны. Матрица является строго положительной тогда и только тогда, когда она эрмитова и ее все собственные значения положительны.
Предложение 2. Матрица является положительной тогда и только тогда, когда она эрмитова и ее главные миноры неотрицательные. Матрица является строго положительной тогда и только тогда, когда она эрмитова и ее все главные миноры положительные.
Предложение 3. Матрица 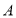 является положительной тогда и только тогда, когда существует матрица
является положительной тогда и только тогда, когда существует матрица 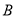 такая, что
такая, что 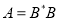 . Матрица является строго положительной тогда и только тогда, когда матрица не сингулярная.
. Матрица является строго положительной тогда и только тогда, когда матрица не сингулярная.
Предложение 4. Матрица является положительной тогда и только тогда, когда существует положительная матрица такая, что 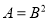 . Матрица является строго положительной тогда и только тогда, когда матрица строго положительна.
. Матрица является строго положительной тогда и только тогда, когда матрица строго положительна.
Заметим, что в Предложение 4, матрица является единственной, и она называется квадратным корнем матрицы 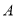 и обозначается через
и обозначается через 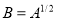 .
.
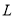
Пусть евклидово пространство, т. е. линейное пространство со скалярным произведением.
Теорема 1. Матрица 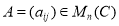 является положительной тогда и только тогда, когда существуют элементы
является положительной тогда и только тогда, когда существуют элементы 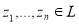 такие, что,
такие, что,
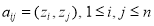
.
Матрица является строго положительной тогда и только тогда, когда элементы 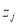 ,
, 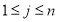 линейно независимы.
линейно независимы.
Рассмотрим пример на применении теоремы 1.
Пример 1. Пусть 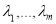 фиксированные вещественные положительные числа. Определим матрицу размера
фиксированные вещественные положительные числа. Определим матрицу размера 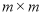 с элементами
с элементами
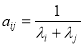
.
Такая матрица называется матрицей Коши. Тогда имеет место соотношение
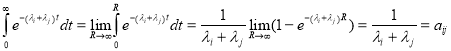
.
Если 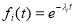 ,
, 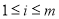 , то
, то 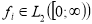 и при всех
и при всех 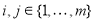 имеет место равенство
имеет место равенство 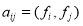 , где для элементов
, где для элементов 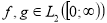 справедливо равенство
справедливо равенство
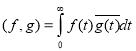
.
В силу теоремы 1 матрица является положительной.
Если и 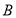 положительные эрмитовы матрицы, то
положительные эрмитовы матрицы, то 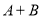 также положительная эрмитова матрица. Произведение матриц
также положительная эрмитова матрица. Произведение матриц 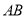 является эрмитовым тогда и только тогда, когда и коммутативные матрицы.
является эрмитовым тогда и только тогда, когда и коммутативные матрицы.
Матрица 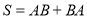 называется симметрическим произведением матриц и . Если матрицы и эрмитовы, то
называется симметрическим произведением матриц и . Если матрицы и эрмитовы, то 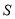 также эрмитова. Вообще говоря, из положительности матриц и не всегда вытекает положительность матрицы
также эрмитова. Вообще говоря, из положительности матриц и не всегда вытекает положительность матрицы 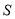 .
.
Пример 2. Для любых определим эрмитовы матрицы
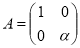 ,
, 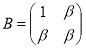 .
.
Видно, что если 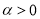 , то матрица
, то матрица 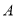 является положительно определенной. Для любого элемента
является положительно определенной. Для любого элемента 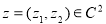 имеет место равенство
имеет место равенство
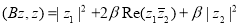
.
Через 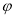 обозначим аргумент комплексного числа
обозначим аргумент комплексного числа 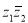 . Тогда имеет место равенство
. Тогда имеет место равенство 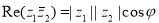 . Поэтому квадратичная форма
. Поэтому квадратичная форма 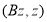 записывается в виде
записывается в виде 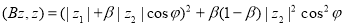 . Таким образом, при
. Таким образом, при 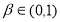 матрица
матрица 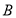 является положительно определенной. По определению
является положительно определенной. По определению 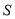 имеет место равенство
имеет место равенство
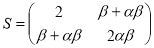
,
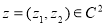
следовательно, для любого элемента имеет место равенство
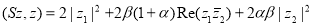
.
При этом, если 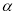 близко к нулю, а
близко к нулю, а 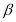 близко к 1, то матрица
близко к 1, то матрица 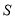 не является положительно. Например, для элемента
не является положительно. Например, для элемента 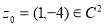 имеет место равенство
имеет место равенство 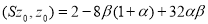 . Если положить
. Если положить 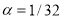 и
и 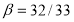 , то
, то 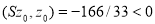 .
.
Пусть 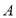 и
и 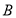 эрмитовы матрицы и матрица
эрмитовы матрицы и матрица 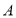 строго положительна. Если симметрическое произведение
строго положительна. Если симметрическое произведение 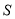 является положительным (строго положительным), то матрица
является положительным (строго положительным), то матрица 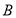 также является положительным (строго положительным).
также является положительным (строго положительным).
- R. Bhatia. Matrix analysis. Springer-Verlag, New York, 1997.
- R. Bhatia. Positive definite matrices. In: Princeton Series in Applied Mathematics. Princeton University Press, 1997.
Как сделать положительно определенную матрицу
Если в системе линейных уравнений матрица является симметричной и к тому же положительно определённой ( xAx > 0, если x != 0 ), то в этом случае можно использовать для решения специальные методы.
Одним из таких методов является разложение Холецкого. Он представляет исходную матрицу в виде произведения: A = LL T , где L — нижняя треугольная матрица. Для того, чтобы найти решение системы Ax = b, последовательно решаются системы Ly = b, L T x = y. Здесь разложение Холецкого реализовано в виде класса SM_Chol. Конструктор осуществляет разложение исходной матрицы и хранит результат в одномерном массиве. Для диагональных элементов матрицы L записаны обратные значения. Метод determinant вычисляет определитель матрицы, а метод solve решает систему уравнений. Заметим, что в качестве аргументов для метода solve могут быть указатели на один и тот же массив. В этом случае исходные данные заменятся на вектор решения. Для того, чтобы найти обратную матрицу нужно n раз применить метод solve к соответствующему столбцу единичной матрицы, при этом будет получаться столбец обратной матрицы.
class SM_Chol < const nat n; DynArrayg; // Запрет конструктора копии и оператора присваивания: SM_Chol ( SM_Chol & ); void operator = ( SM_Chol & ); public: SM_Chol ( nat k, const double * const * a ); bool solve ( const double * b, double * x ) const; // b[n], x[n] double determinant () const; >;
Другим методом является LDL T разложение, где L — нижняя треугольная матрица с единичной диагональю, а D — диагональная матрица. В отличии от разложения Холецкого этот метод не использует операцию извлечения квадратного корня. Класс SM_LDLt имеет интерфейс аналогичный интерфейсу класса SM_Chol.
class SM_LDLt < const nat n; DynArrayg; // Запрет конструктора копии и оператора присваивания: SM_LDLt ( SM_LDLt & ); void operator = ( SM_LDLt & ); public: SM_LDLt ( nat k, const double * const * a ); bool solve ( const double * b, double * x ) const; // b[n], x[n] double determinant () const; >;
Оба класса были написаны на основе соответствующих программ из книги «Справочник алгоритмов на языке Алгол» ( Уилкинсон, Райнш ).
Если матрица сильно разреженна, то для неё применяют специальный вариант метода LDL T :
bool slu_LDLt ( nat n, const nat * m, double * a, const double * b, double * x ); bool slu_LDLt ( nat n, const Suite > * data, const double * b, double * x );
Массив m содержит количество лидирующих нулей в каждой строке.
Функция slu_LDLtO ( O — оптимизирующая ) вначале переставляет строки и столбцы матрицы для того, чтобы увеличить количество лидирующих нулей и тем самым ускоряет вычисления:
bool slu_LDLtO ( nat n, const Suite > * data, const double * b, double * x );
Также для разреженных матриц применяют метод сопряжённых градиентов:
void slu_cg ( nat n, const Suite > * data, const double * b, double * x );
Описание шаблонов классов DynArray и Suite находится здесь.
Исходники находятся в файле mathem.cpp.
Как сделать положительно определенную матрицу

Положительно определенные матрицы являются одним из ключевых объектов линейной алгебры. Они играют важную роль в различных областях, включая оптимизацию, статистику и теорию управления. В этой статье мы рассмотрим основные методы получения положительно определенных матриц.
Первый метод заключается в использовании квадратных матриц с неотрицательными элементами. Если все главные миноры такой матрицы положительны, то она будет положительно определенной. Этот метод используется для получения матриц в задачах статистики и теории управления.
Второй метод основан на использовании симметричных матриц. Если симметричная матрица имеет положительные собственные значения, то она будет положительно определенной. Этот метод широко применяется в теории оптимизации и машинном обучении.
Важно отметить, что положительно определенные матрицы имеют множество полезных свойств, таких как положительность всех углов прямоугольников, образованных столбцами или строками матрицы. Это делает их незаменимыми инструментами при решении различных задач.
В этой статье мы рассмотрели основные методы получения положительно определенных матриц. Знание этих методов позволяет эффективно работать с такими матрицами и использовать их в различных областях науки и техники.
Метод Гаусса для положительно определенных матриц
Метод Гаусса является одним из основных методов получения положительно определенной матрицы. Он основан на использовании элементарных преобразований матрицы, которые позволяют привести ее к требуемому виду.
Для начала, необходимо иметь квадратную матрицу размером n x n. Далее, следует последовательно применять элементарные преобразования к матрице до тех пор, пока она не примет требуемый вид.
- Сначала необходимо привести матрицу к ступенчатому виду. Это делается путем вычитания из одной строки других строк, умноженных на определенный коэффициент.
- Затем следует привести матрицу к улучшенному ступенчатому виду. Для этого нужно привести все ненулевые строки к виду, в котором первый ненулевой элемент равен 1, а все остальные элементы этой строки равны 0.
- Далее, нужно привести матрицу к диагональному виду. Для этого нужно заменить каждую строку с ненулевым первым элементом на строку, в которой первый элемент равен 1, а все остальные элементы равны 0.
После выполнения этих шагов, получается положительно определенная матрица. Однако, метод Гаусса не всегда дает положительно определенную матрицу. В некоторых случаях, может возникнуть необходимость в использовании других методов для достижения требуемого результата.
Метод Гаусса является одним из самых популярных методов построения положительно определенных матриц и находит свое применение в различных областях, таких как линейная алгебра, численные методы и искусственный интеллект.
Метод Холецкого для положительно определенных матриц
Метод Холецкого является одним из основных методов получения положительно определенной матрицы. Этот метод основан на разложении матрицы А в произведение верхней и нижней треугольных матриц: A = L * L^T, где L — нижняя треугольная матрица, а L^T — транспонированная верхняя треугольная матрица.
Для применения метода Холецкого необходимо выполнение следующих условий:
- Матрица A должна быть симметричной;
- Матрица A должна быть положительно определенной.
Суть метода Холецкого заключается в последовательном вычислении элементов матрицы L и L^T. Первый элемент первого столбца матрицы L вычисляется по формуле: L[1][1] = √(A[1][1]). Затем вычисляются остальные элементы первого столбца матрицы L аналогично: L[i][1] = (A[i][1]) / L[1][1].
После этого происходит итерационный процесс, при котором вычисляются остальные столбцы матрицы L и строки матрицы L^T по формулам:
- L[i][j] = (A[i][j] — sum(L[i][k] * L[j][k]) / L[j][j]) / L[j][j] (для i > j);
- L^T[j][i] = L[i][j] (для i ≤ j).
Таким образом, последовательное заполнение элементов матрицы L и L^T приводит к получению разложения матрицы А на произведение двух треугольных матриц. Полученные матрицы L и L^T являются верхней и нижней треугольными матрицами соответственно.
Основными преимуществами метода Холецкого являются:
- Высокая эффективность и скорость вычислений;
- Получение положительно определенной матрицы, которая может быть использована для решения систем линейных уравнений, определения собственных значений и восстановления матрицы.
Вместе с тем, метод Холецкого обладает рядом особенностей и ограничений:
- Необходимость выполнения условий симметричности и положительной определенности матрицы;
- Итерационный процесс может быть неустойчивым при плохо обусловленных матрицах.
В целом, метод Холецкого является важным инструментом для работы с положительно определенными матрицами и имеет широкий спектр применений.
Метод Якоби для положительно определенных матриц
Метод Якоби является одним из основных методов для получения положительно определенных матриц. Он основан на итерационном процессе, который последовательно вычисляет приближенные значения главных элементов матрицы.
Данный метод используется для нахождения собственных значений и собственных векторов положительно определенных матриц. Основная идея состоит в том, чтобы последовательно преобразовывать матрицу таким образом, чтобы главные элементы увеличивались на каждой итерации.
Алгоритм метода Якоби приведен ниже:
- Инициализировать матрицу A.
- Пока не будет достигнута необходимая точность:
- Выбрать ненулевой элемент A[ij], такой что i ≠ j и |A[ij]| максимально.
- Вычислить угол φ, такой что cos(φ) = A[ij] / sqrt(A[ii] * A[jj]).
- Вычислить матрицу поворота J с элементами J[kl], где k ≠ l:
- J[kk] = J[ll] = cos(φ)
- J[kl] = -sin(φ)
- J[lk] = sin(φ)
- Вычислить новую матрицу A’ = J^T * A * J, где J^T — транспонированная матрица J.
- Заменить матрицу A на A’.
После выполнения всех итераций матрица А будет содержать приближенные значения главных элементов, которые являются собственными значениями положительно определенной матрицы. Собственные векторы можно получить из столбцов матрицы J.
Преимущество метода Якоби заключается в его простоте и универсальности. Он позволяет получать точные результаты для положительно определенных матриц любого размера. Однако, данный метод требует большого количества итераций для достижения необходимой точности и может быть медленным для больших матриц.
Метод Гаусса-Зейделя для положительно определенных матриц
Метод Гаусса-Зейделя является итерационным численным методом для решения системы линейных уравнений. Он применяется в основном для решения систем, матрицы которых являются положительно определенными.
Для начала, давайте разберемся, что значит, что матрица является положительно определенной. Матрица A называется положительно определенной, если для любого ненулевого вектора x выполняется условие x’Ax > 0, где x’ — это транспонированный вектор x.
Процесс решения системы линейных уравнений методом Гаусса-Зейделя состоит из следующих шагов:
- Инициализировать начальное приближение решения x^0.
- Вычислить следующее приближение решения x^k по формуле x^k = D^(-1)(Lx^(k-1) + Ux^k-1 + b), где D, L, U — диагональная, нижняя треугольная и верхняя треугольная части матрицы A, соответственно, b — вектор свободных членов системы уравнений.
- Повторять шаг 2, пока не будет достигнута необходимая точность или не будет превышено максимальное количество итераций.
Преимуществом метода Гаусса-Зейделя является его сходимость для положительно определенных матриц. Кроме того, этот метод позволяет решить систему уравнений, даже если матрица является плохо обусловленной.
Однако метод Гаусса-Зейделя имеет и некоторые ограничения. Количество итераций, необходимых для достижения заданной точности, может быть достаточно большим. Кроме того, сходимость метода может быть замедлена, если матрица системы близка к вырожденной или несимметричной.
В заключение, метод Гаусса-Зейделя является эффективным инструментом для решения системы линейных уравнений с использованием положительно определенных матриц. Его применение может быть особенно полезным в задачах оптимизации и моделирования, где требуется найти точное или приближенное решение системы уравнений.
Метод сопряженных градиентов для положительно определенных матриц
Метод сопряженных градиентов является одним из эффективных численных методов для решения систем линейных уравнений. В основе метода лежит идея минимизации квадратичной функции, что делает его особенно полезным при решении задач оптимизации и при работе с матрицами, которые являются положительно определенными.
Матрица называется положительно определенной, если для любого ненулевого вектора x выполнено условие x T Ax > 0, где A — исходная матрица. В случае положительно определенной матрицы метод сопряженных градиентов оказывается особенно эффективным и быстрым.
Основная идея метода заключается в постепенном улучшении приближения к точному решению путем выбора «сопряженных» направлений. В каждом шаге метода строится новое направление, которое ортогонально всем предыдущим направлениям исходя из скалярного произведения матрицы и градиента функции.
Алгоритм метода сопряженных градиентов:
- Выбрать начальное приближение x0.
- Вычислить градиент функции f(x) в точке xk.
- Вычислить новое направление по формуле: pk+1 = -∇f(xk) + βkpk, где βk — коэффициент, вычисляемый по формуле: βk = (∇f(xk))^T∇f(xk) / (∇f(xk-1))^T∇f(xk-1)
- Найдите оптимальное значение шага αk по формуле: αk = (∇f(xk))^T∇f(xk) / (∇f(xk))^TA(∇f(xk))
- Вычислите новое приближение к точному решению: xk+1 = xk + αk * pk+1.
- Повторите шаги 2-5 до достижения условия сходимости.
Преимущество метода сопряженных градиентов заключается в том, что он требует очень мало памяти и производительных ресурсов для работы. Это делает его особенно полезным при решении больших и сложных задач.
Однако следует отметить, что метод сопряженных градиентов применим только для положительно определенных матриц. В случае, когда матрица не является положительно определенной, метод может давать неустойчивые или неверные результаты.
В заключение, можно сказать, что метод сопряженных градиентов является мощным инструментом для решения систем линейных уравнений с положительно определенными матрицами. Он позволяет достичь высокой точности и эффективности при минимальных затратах ресурсов.
Вариационный метод для положительно определенных матриц
Вариационный метод является одним из основных подходов для получения положительно определенной матрицы. Он основан на принципе минимума (или максимума) функционала, который задается матрицей и зависит от ее элементов.
Для получения положительно определенной матрицы с помощью вариационного метода необходимо выполнить следующие шаги:
- Выбрать вариационный принцип, который будет определять функционал, зависящий от элементов матрицы.
- Провести вариацию функционала путем изменения значений элементов матрицы.
- Найти условия экстремума функционала, например, найти нули производной функционала или точки максимума/минимума функционала.
- Проверить полученные условия экстремума на достаточные и необходимые условия положительной определенности матрицы.
- Если все условия выполнены, полученная матрица положительно определена.
Одним из примеров вариационного метода для положительно определенных матриц является метод наименьших квадратов. В этом методе минимизируется разница между значениями некоторой функции и ее приближением, полученным с использованием матрицы.
Вариационный метод является эффективным и мощным инструментом для получения положительно определенных матриц. Он широко применяется в различных областях науки и техники, таких как математика, физика, экономика и т. д.
Использование вариационного метода требует глубоких знаний в математике и умения проводить сложные вычисления. Однако, благодаря современным вычислительным методам и программам, вариационный метод становится более доступным для широкого круга исследователей.
Метод Ланцоша для положительно определенных матриц
Метод Ланцоша — это итерационный метод, используемый для приближенного нахождения собственных значений и собственных векторов положительно определенных матриц.
Основная идея метода Ланцоша заключается в нахождении последовательности ортогональных векторов, которые образуют базис Крылова пространства, связанного с данной матрицей.
Шаги метода Ланцоша:
- Выбрать вектор взаимно ортогонального и отличного от нулевого, который будет использоваться в качестве начального приближения для собственного вектора.
- Построить базис Крылова пространства, используя матрицу и предыдущие векторы базиса.
- На каждом шаге процесса выбрать новый вектор базиса, ортогональный всем предыдущим и имеющий наибольшее собственное значение в подпространстве Крылова.
- Итеративно повторять шаги 2 и 3, пока не будет достигнут требуемый уровень точности.
Метод Ланцоша позволяет находить только несколько самых больших по модулю собственных значений и соответствующие им собственные векторы. Для получения всех собственных значений и векторов положительно определенной матрицы часто используются комбинированные методы, совмещающие метод Ланцоша с другими методами, например, методом QR-алгоритма или степенным методом.
Метод Ланцоша широко применяется в различных областях, таких как машинное обучение, численные методы, физика и инженерия. Он является эффективным инструментом для приближенного решения задач, требующих работы с положительно определенными матрицами.
Метод Брауэра для положительно определенных матриц
Метод Брауэра является одним из основных методов получения положительно определенных матриц. Данный метод позволяет преобразовать любую матрицу в положительно определенную матрицу путем взятия последовательности приближений.
Простая итерационная формула для получения положительно определенной матрицы методом Брауэра выглядит следующим образом:
| Шаг 1: | Пусть дана матрица A размерности n x n. |
| Шаг 2: | Вычислить матрицу B по формуле B = (A + A T )/2, где A T — транспонированная матрица A. |
| Шаг 3: | Повторять шаг 2 до достижения требуемой точности или сходимости. |
| Шаг 4: | Матрица B будет приближениями ко всем положительно определенным матрицам близких размерностей. |
Метод Брауэра обладает рядом важных свойств:
- Сходимость метода Брауэра для получения положительно определенной матрицы гарантирована;
- Метод работает для положительно определенных матриц любой размерности;
- Метод имеет эффективное время выполнения, что делает его применимым для больших матриц;
- Полученные приближения положительно определенных матриц могут быть использованы для решения различных задач в математике, физике, экономике и других областях.
Таким образом, метод Брауэра представляет собой мощный инструмент для получения положительно определенных матриц и может быть использован в различных научных и практических приложениях.
Вопрос-ответ
Что такое положительно определенная матрица?
Положительно определенная матрица — это квадратная матрица, у которой все главные миноры положительны. Главным минором называется определитель подматрицы, полученной выбором любого набора строк и столбцов из исходной матрицы.
Какие методы существуют для получения положительно определенной матрицы?
Существует несколько методов для получения положительно определенной матрицы. Один из них — это проверка всех главных миноров матрицы на положительность. Если все главные миноры положительны, то матрица положительно определена. Еще один метод — это применение алгоритма Холецкого, который разлагает матрицу на произведение верхней и нижней треугольных матриц, и проверка положительности диагональных элементов. Также можно использовать методы собственных значений, такие как теорема Гурвица или критерий Сильвестра.
Как проверить положительность главных миноров матрицы?
Для проверки положительности главных миноров матрицы нужно вычислить определители всех подматриц, полученных выбором любого набора строк и столбцов из исходной матрицы. Если все эти определители положительны, то все главные миноры положительны, и матрица является положительно определенной.
Можете рассказать подробнее о методе Холецкого для получения положительно определенной матрицы?
Метод Холецкого — это алгоритм, который разлагает положительно определенную матрицу на произведение верхней и нижней треугольных матриц. Для получения разложения матрицы A необходимо найти верхнетреугольную матрицу R и ее транспонированную нижнетреугольную матрицу R^T такие, что A = RR^T. При этом верхнетреугольная матрица R получается путем применения метода Холецкого к матрице A.
NumPy: матрицы и операции над ними
В этом ноутбуке из сторонних библиотек нам понадобится только NumPy. Для удобства импортируем ее под более коротким именем:
import numpy as np
1. Создание матриц
Приведем несколько способов создания матриц в NumPy.
Самый простой способ — с помощью функции numpy.array(list, dtype=None, . ).
В качестве первого аргумента ей надо передать итерируемый объект, элементами которого являются другие итерируемые объекты одинаковой длины и содержащие данные одинакового типа.
Второй аргумент является опциональным и определяет тип данных матрицы. Его можно не задавать, тогда тип данных будет определен из типа элементов первого аргумента. При задании этого параметра будет произведена попытка приведения типов.
Например, матрицу из списка списков целых чисел можно создать следующим образом:
a = np.array([1, 2, 3]) # Создаем одномерный массив print(type(a)) # Prints "" print(a.shape) # Prints "(3,)" - кортеж с размерностями print(a[0], a[1], a[2]) # Prints "1 2 3" a[0] = 5 # Изменяем значение элемента массива print(a) # Prints "[5, 2, 3]" b = np.array([[1,2,3],[4,5,6]]) # Создаем двухмерный массив print(b.shape) # Prints "(2, 3)" print(b[0, 0], b[0, 1], b[1, 0]) # Prints "1 2 4" print(np.arange(1, 5)) #Cоздает вектор с эелементами от 1 до 4
(3,) 1 2 3 [5 2 3] (2, 3) 1 2 4 [1 2 3 4]
matrix = np.array([[1, 2, 3], [2, 5, 6], [6, 7, 4]]) print ("Матрица:\n", matrix)
Матрица: [[1 2 3] [2 5 6] [6 7 4]]
Второй способ создания — с помощью встроенных функций numpy.eye(N, M=None, . ), numpy.zeros(shape, . ), numpy.ones(shape, . ).
Первая функция создает единичную матрицу размера N×M ; если M не задан, то M = N .
Вторая и третья функции создают матрицы, состоящие целиком из нулей или единиц соответственно. В качестве первого аргумента необходимо задать размерность массива — кортеж целых чисел. В двумерном случае это набор из двух чисел: количество строк и столбцов матрицы.
Примеры:
b = np.eye(5) print ("Единичная матрица:\n", b)
Единичная матрица: [[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 1. 0.] [0. 0. 0. 0. 1.]]
c = np.ones((7, 5)) print ("Матрица, состоящая из одних единиц:\n", c)
Матрица, состоящая из одних единиц: [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]]
d = np.full((2,2), 7) # Создает матрицу (1, 2) заполненую заданным значением print(d) # Prints "[[ 7. 7.] # [ 7. 7.]]" e = np.random.random((2,2)) # Создает еденичную матрицу (2, 2) заполненую случаными числами (0, 1) print(e) # Might print "[[ 0.91940167 0.08143941] # [ 0.68744134 0.87236687]]"
[[7 7] [7 7]] [[0.25744383 0.48056466] [0.13767881 0.40578168]]
Обратите внимание: размерность массива задается не двумя аргументами функции, а одним — кортежем!
Вот так — np.ones(7, 5) — создать массив не получится, так как функции в качестве параметра shape передается 7, а не кортеж (7, 5).
И, наконец, третий способ — с помощью функции numpy.arange([start, ]stop, [step, ], . ), которая создает одномерный массив последовательных чисел из промежутка [start, stop) с заданным шагом step, и метода array.reshape(shape).
Параметр shape, как и в предыдущем примере, задает размерность матрицы (кортеж чисел). Логика работы метода ясна из следующего примера:
v = np.arange(0, 24, 2) print ("Вектор-столбец:\n", v)
Вектор-столбец: [ 0 2 4 6 8 10 12 14 16 18 20 22]
d = v.reshape((3, 4)) print ("Матрица:\n", d)
Матрица: [[ 0 2 4 6] [ 8 10 12 14] [16 18 20 22]]
Более подробно о том, как создавать массивы в NumPy, см. документацию.
2. Индексирование
Для получения элементов матрицы можно использовать несколько способов. Рассмотрим самые простые из них.
Для удобства напомним, как выглядит матрица d:
print ("Матрица:\n", d)
Матрица: [[ 0 2 4 6] [ 8 10 12 14] [16 18 20 22]]
Элемент на пересечении строки i и столбца j можно получить с помощью выражения array[i, j].
Обратите внимание: строки и столбцы нумеруются с нуля!
print ("Второй элемент третьей строки матрицы:", d[2, 1])
Второй элемент третьей строки матрицы: 18
Из матрицы можно получать целые строки или столбцы с помощью выражений array[i, :] или array[:, j] соответственно:
print ("Вторая строка матрицы d:\n", d[1, :]) print ("Четвертый столбец матрицы d:\n", d[:, 3])
Вторая строка матрицы d: [ 8 10 12 14] Четвертый столбец матрицы d: [ 6 14 22]
Еще один способ получения элементов — с помощью выражения array[list1, list2], где list1, list2 — некоторые списки целых чисел. При такой адресации одновременно просматриваются оба списка и возвращаются элементы матрицы с соответствующими координатами. Следующий пример более понятно объясняет механизм работы такого индексирования:
print ("Элементы матрицы d с координатами (1, 2) и (0, 3):\n", d[[1, 0], [2, 3]])
Элементы матрицы d с координатами (1, 2) и (0, 3): [12 6]
# Slicing # Создадим матрицу (3, 4) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) # Используя слайсинг, созадим матрицу b из элементов матрицы а # будем использовать 0 и 1 строку, а так же 1 и 2 столебц # [[2 3] # [6 7]] b = a[:2, 1:3] print(b) # ОБРАТИТЕ ВНИМАНИЕ НА ИЗМЕНЕНИЕ ИСХОДОЙ МАТРИЦЫ print(a[0, 1]) # Prints "2" b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1] print(a[0, 1]) # Prints "77"
[[2 3] [6 7]] 2 77
# Integer array indexing a = np.array([[1,2], [3, 4], [5, 6]]) print(a) print() # Пример Integer array indexing # В результате получится массив размерности (3,) # Обратите внимание, что до запятой идут индексы строк, после - столбцов print(a[[0, 1, 2], [0, 1, 0]]) # Prints "[1 4 5]" print() # По-другому пример можно записать так print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints "[1 4 5]"
[[1 2] [3 4] [5 6]] [1 4 5] [1 4 5]
Примеры использования слайсинга:
# Создадим новый маассив, из которого будем выбирать эллементы a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]]) print(a) # prints "array([[ 1, 2, 3], # [ 4, 5, 6], # [ 7, 8, 9], # [10, 11, 12]])" # Создадим массив индексов b = np.array([0, 2, 0, 1]) # Выберем из каждой строки элемент с индексом из b (индекс столбца берется из b) print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]" print() # Добавим к этим элементам 10 a[np.arange(4), b] += 10 print(a) # prints "array([[11, 2, 3], # [ 4, 5, 16], # [17, 8, 9], # [10, 21, 12]])
[[ 1 2 3] [ 4 5 6] [ 7 8 9] [10 11 12]] [ 1 6 7 11] [[11 2 3] [ 4 5 16] [17 8 9] [10 21 12]]
a = np.array([[1,2], [3, 4], [5, 6]]) bool_idx = (a > 2) # Найдем эллементы матрицы a, которые больше 2 # В результате получим матрицу b, такой же размерности, как и a print(bool_idx) # Prints "[[False False] print() # [ True True] # [ True True]]" # Воспользуемся полученным массивом для создания нового массива, ранга 1 print(a[bool_idx]) # Prints "[3 4 5 6]" # Аналогично print(a[a > 2]) # Prints "[3 4 5 6]"
[[False False] [ True True] [ True True]] [3 4 5 6] [3 4 5 6]
#Помните, что вы можете пользоваться сразу несколькими типами индексирования a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) row_r1 = a[1, :] row_r2 = a[1:2, :] print(row_r1, row_r1.shape) # Prints "[5 6 7 8] (4,)" print(row_r2, row_r2.shape) # Prints "[[5 6 7 8]] (1, 4)"
[5 6 7 8] (4,) [[5 6 7 8]] (1, 4)
Более подробно о различных способах индексирования в массивах см. документацию.
3. Векторы, вектор-строки и вектор-столбцы
Следующие два способа задания массива кажутся одинаковыми:
a = np.array([1, 2, 3]) b = np.array([[1], [2], [3]])
Однако, на самом деле, это задание одномерного массива (то есть вектора) и двумерного массива:
print ("Вектор:\n", a) print ("Его размерность:\n", a.shape) print ("Двумерный массив:\n", b) print ("Его размерность:\n", b.shape)
Вектор: [1 2 3] Его размерность: (3,) Двумерный массив: [[1] [2] [3]] Его размерность: (3, 1)
Обратите внимание: вектор (одномерный массив) и вектор-столбец или вектор-строка (двумерные массивы) являются различными объектами в NumPy, хотя математически задают один и тот же объект. В случае одномерного массива кортеж shape состоит из одного числа и имеет вид (n,), где n — длина вектора. В случае двумерных векторов в shape присутствует еще одна размерность, равная единице.
В большинстве случаев неважно, какое представление использовать, потому что часто срабатывает приведение типов. Но некоторые операции не работают для одномерных массивов. Например, транспонирование (о нем пойдет речь ниже):
a = a.T b = b.T
print ("Вектор не изменился:\n", a) print ("Его размерность также не изменилась:\n", a.shape) print ("Транспонированный двумерный массив:\n", b) print ("Его размерность изменилась:\n", b.shape)
Вектор не изменился: [1 2 3] Его размерность также не изменилась: (3,) Транспонированный двумерный массив: [[1 2 3]] Его размерность изменилась: (1, 3)
4. Datatypes
Все элементы в массиве numpy принадлежат одному типу. В этом плане массивы ближе к C, чем к привычным вам листам питона. Numpy имеет множество встренных типов, подходящих для решения большинства задач.
x = np.array([1, 2]) # Автоматический выбор типа print(x.dtype) # Prints "int64" x = np.array([1.0, 2.0]) # Автоматический выбор типа print(x.dtype) # Prints "float64" x = np.array([1, 2], dtype=np.int64) # Принудительное выставление типа print(x.dtype) # Prints "int64"
int32 float64 int64
5. Математические операции
К массивам (матрицам) можно применять известные вам математические операции. Следут понимать, что при этом у элементов должны быть схожие размерности. Поведение в случае не совпадения размерностей хорошо описанно в документации numpy.
x = np.array([[1,2],[3,4]], dtype=np.float64) y = np.array([[5,6],[7,8]], dtype=np.float64) arr = np.array([1, 2])
# Сложение происходит поэлеметно # [[ 6.0 8.0] # [10.0 12.0]] print(x + y) print() print(np.add(x, y)) print('С числом') print(x + 1) print('C массивом другой размерности') print(x + arr)
[[ 6. 8.] [10. 12.]] [[ 6. 8.] [10. 12.]] С числом [[2. 3.] [4. 5.]] C массивом другой размерности [[2. 4.] [4. 6.]]
# Вычитание print(x - y) print(np.subtract(x, y))
[[-4. -4.] [-4. -4.]] [[-4. -4.] [-4. -4.]]
# Деление # [[ 0.2 0.33333333] # [ 0.42857143 0.5 ]] print(x / y) print(np.divide(x, y))
[[0.2 0.33333333] [0.42857143 0.5 ]] [[0.2 0.33333333] [0.42857143 0.5 ]]
# Другие функции # [[ 1. 1.41421356] # [ 1.73205081 2. ]] print(np.sqrt(x))
[[1. 1.41421356] [1.73205081 2. ]]
6. Умножение матриц и столбцов
Напоминание теории. Операция умножения определена для двух матриц, таких что число столбцов первой равно числу строк второй.
Пусть матрицы A и B таковы, что A ∈ ℝ n×k и B ∈ ℝ k×m . Произведением матриц A и B называется матрица C , такая что cij = ∑ k r = 1 airbrj , где cij — элемент матрицы C , стоящий на пересечении строки с номером i и столбца с номером j .
В NumPy произведение матриц вычисляется с помощью функции numpy.dot(a, b, . ) или с помощью метода array1.dot(array2), где array1 и array2 — перемножаемые матрицы.
a = np.array([[1, 0], [0, 1]]) b = np.array([[4, 1], [2, 2]]) r1 = np.dot(a, b) r2 = a.dot(b)
print ("Матрица A:\n", a) print ("Матрица B:\n", b) print ("Результат умножения функцией:\n", r1) print ("Результат умножения методом:\n", r2)
Матрица A: [[1 0] [0 1]] Матрица B: [[4 1] [2 2]] Результат умножения функцией: [[4 1] [2 2]] Результат умножения методом: [[4 1] [2 2]]
Матрицы в NumPy можно умножать и на векторы:
c = np.array([1, 2]) r3 = b.dot(c)
print ("Матрица:\n", b) print ("Вектор:\n", c) print ("Результат умножения:\n", r3)
Матрица: [[4 1] [2 2]] Вектор: [1 2] Результат умножения: [6 6]
Обратите внимание: операция * производит над матрицами покоординатное умножение, а не матричное!
r = a * b
print ("Матрица A:\n", a) print ("Матрица B:\n", b) print ("Результат покоординатного умножения через операцию умножения:\n", r)
Матрица A: [[1 0] [0 1]] Матрица B: [[4 1] [2 2]] Результат покоординатного умножения через операцию умножения: [[4 0] [0 2]]
Более подробно о матричном умножении в NumPy см. документацию.
7. Объединение массивов
Массивы можно Объединенять. Есть горизонтальное и вертикальное объединение.
a = np.floor(10*np.random.random((2,2))) b = np.floor(10*np.random.random((2,2))) print(a) print(b) print() print(np.vstack((a,b))) print() print(np.hstack((a,b)))
[[4. 0.] [1. 4.]] [[9. 7.] [2. 6.]] [[4. 0.] [1. 4.] [9. 7.] [2. 6.]] [[4. 0. 9. 7.] [1. 4. 2. 6.]]
Массивы можно переформировать при помощи метода, который задает новый многомерный массив. Следуя следующему примеру, мы переформатируем одномерный массив из десяти элементов во двумерный массив, состоящий из пяти строк и двух столбцов:
a = np.array(range(10), float) print(a) print() # Превратим в матрицу a = a.reshape((5, 2)) print(a) print() # Вернем обратно print(a.flatten()) # Другой вариант print(a.reshape((-1))) # Превратим в марицу (9, 1) print(a.reshape((-1, 1))) # Превратим в марицу (1, 9) print(a.reshape((1, -1)))
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [[0. 1.] [2. 3.] [4. 5.] [6. 7.] [8. 9.]] [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [[0.] [1.] [2.] [3.] [4.] [5.] [6.] [7.] [8.] [9.]] [[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]]
Задания: (Блок 1)
Задание 1:
Решите без использования циклов средставми NumPy (каждый пункт решается в 1-2 строчки)
- Создайте вектор с элементами от 12 до 42
- Создайте вектор из нулей длины 12, но его пятый елемент должен быть равен 1
- Создайте матрицу (3, 3), заполненую от 0 до 8
- Найдите все положительные числа в np.array([1,2,0,0,4,0])
- Умножьте матрицу размерности (5, 3) на (3, 2)
- Создайте матрицу (10, 10) так, чтобы на границе были 0, а внтури 1
- Создайте рандомный вектор и отсортируйте его
- Каков эквивалент функции enumerate для numpy массивов?
- *Создайте рандомный вектор и выполните нормализацию столбцов (из каждого столбца вычесть среднее этого столбца, из каждого столбца вычесть sd этого столбца)
- *Для заданного числа найдите ближайший к нему элемент в векторе
- *Найдите N наибольших значений в векторе
# ваш код здесь
Задание 2:
Напишите полностью векторизованный вариант
Дан трёхмерный массив, содержащий изображение, размера (height, width, numChannels), а также вектор длины numChannels. Сложить каналы изображения с указанными весами, и вернуть результат в виде матрицы размера (height, width). Считать реальное изображение можно при помощи функции scipy.misc.imread (если изображение не в формате png, установите пакет pillow: conda install pillow). Преобразуйте цветное изображение в оттенки серого, использовав коэффициенты np.array([0.299, 0.587, 0.114]).
# ваш код здесь
8. Транспонирование матриц
Напоминание теории. Транспонированной матрицей A T называется матрица, полученная из исходной матрицы A заменой строк на столбцы. Формально: элементы матрицы A T определяются как a T ij = aji , где a T ij — элемент матрицы A T , стоящий на пересечении строки с номером i и столбца с номером j .
В NumPy транспонированная матрица вычисляется с помощью функции numpy.transpose() или с помощью метода array.T, где array — нужный двумерный массив.
a = np.array([[1, 2], [3, 4]]) b = np.transpose(a) c = a.T
print ("Матрица:\n", a) print ("Транспонирование функцией:\n", b) print ("Транспонирование методом:\n", c)
Матрица: [[1 2] [3 4]] Транспонирование функцией: [[1 3] [2 4]] Транспонирование методом: [[1 3] [2 4]]
В следующих разделах активно используется модуль numpy.linalg, реализующий некоторые приложения линейной алгебры. Более подробно о функциях, описанных ниже, и различных других функциях этого модуля можно посмотреть в его документации.
9. Определитель матрицы
Напоминание теории. Для квадратных матриц существует понятие определителя.
Пусть A — квадратная матрица. Определителем (или детерминантом) матрицы A ∈ ℝ n×n назовем число
detA = ∑ α1, α2, …, αn ( − 1) N(α1, α2, …, αn) ⋅aα11⋅⋅⋅aαnn,
где α1, α2, …, αn — перестановка чисел от 1 до n , N(α1, α2, …, αn) — число инверсий в перестановке, суммирование ведется по всем возможным перестановкам длины n .
Не стоит расстраиваться, если это определение понятно не до конца — в дальнейшем в таком виде оно не понадобится.
Например, для матрицы размера 2×2 получается:
det ⎛ ⎜ ⎝ a11 a12 a21 a22 ⎞ ⎟ ⎠ = a11a22 − a12a21
Вычисление определителя матрицы по определению требует порядка n! операций, поэтому разработаны методы, которые позволяют вычислять его быстро и эффективно.
В NumPy определитель матрицы вычисляется с помощью функции numpy.linalg.det(a), где a — исходная матрица.
a = np.array([[1, 2, 1], [1, 1, 4], [2, 3, 6]], dtype=np.float32) det = np.linalg.det(a)
print ("Матрица:\n", a) print ("Определитель:\n", det)
Матрица: [[1. 2. 1.] [1. 1. 4.] [2. 3. 6.]] Определитель: -1.0
Рассмотрим одно интересное свойство определителя. Пусть у нас есть параллелограмм с углами в точках (0, 0), (c, d), (a + c, b + d), (a, b) (углы даны в порядке обхода по часовой стрелке). Тогда площадь этого параллелограмма можно вычислить как модуль определителя матрицы ⎛ ⎜ ⎝ a c b d ⎞ ⎟ ⎠ . Похожим образом можно выразить и объем параллелепипеда через определитель матрицы размера 3×3 .
10. Ранг матрицы
Напоминание теории. Рангом матрицы A называется максимальное число линейно независимых строк (столбцов) этой матрицы.
В NumPy ранг матрицы вычисляется с помощью функции numpy.linalg.matrix_rank(M, tol=None), где M — матрица, tol — параметр, отвечающий за некоторую точность вычисления. В простом случае можно его не задавать, и функция сама определит подходящее значение этого параметра.
a = np.array([[1, 2, 3], [1, 1, 1], [2, 2, 2]]) r = np.linalg.matrix_rank(a)
print ("Матрица:\n", a) print ("Ранг матрицы:", r)
Матрица: [[1 2 3] [1 1 1] [2 2 2]] Ранг матрицы: 2
С помощью вычисления ранга матрицы можно проверять линейную независимость системы векторов.
Допустим, у нас есть несколько векторов. Составим из них матрицу, где наши векторы будут являться строками. Понятно, что векторы линейно независимы тогда и только тогда, когда ранг полученной матрицы совпадает с числом векторов. Приведем пример:
a = np.array([1, 2, 3]) b = np.array([1, 1, 1]) c = np.array([2, 3, 5]) m = np.array([a, b, c])
print (np.linalg.matrix_rank(m) == m.shape[0])
True
11. Системы линейных уравнений
Напоминание теории. Системой линейных алгебраических уравнений называется система вида Ax = b , где A ∈ ℝ n×m , x ∈ ℝ m×1 , b ∈ ℝ n×1 . В случае квадратной невырожденной матрицы A решение системы единственно.
В NumPy решение такой системы можно найти с помощью функции numpy.linalg.solve(a, b), где первый аргумент — матрица A , второй — столбец b .
a = np.array([[3, 1], [1, 2]]) b = np.array([9, 8]) x = np.linalg.solve(a, b)
print ("Матрица A:\n", a) print ("Вектор b:\n", b) print ("Решение системы:\n", x)
Матрица A: [[3 1] [1 2]] Вектор b: [9 8] Решение системы: [2. 3.]
Убедимся, что вектор x действительно является решением системы:
print (a.dot(x))
Бывают случаи, когда решение системы не существует. Но хотелось бы все равно “решить” такую систему. Логичным кажется искать такой вектор x , который минимизирует выражение ‖ Ax − b ‖ 2 — так мы приблизим выражение Ax к b .
В NumPy такое псевдорешение можно искать с помощью функции numpy.linalg.lstsq(a, b, . ), где первые два аргумента такие же, как и для функции numpy.linalg.solve(). Помимо решения функция возвращает еще три значения, которые нам сейчас не понадобятся.
a = np.array([[0, 1], [1, 1], [2, 1], [3, 1]]) b = np.array([-1, 0.2, 0.9, 2.1]) x, res, r, s = np.linalg.lstsq(a, b, rcond=None)
print ("Матрица A:\n", a) print ("Вектор b:\n", b) print ("Псевдорешение системы:\n", x)
Матрица A: [[0 1] [1 1] [2 1] [3 1]] Вектор b: [-1. 0.2 0.9 2.1] Псевдорешение системы: [ 1. -0.95]
12. Обращение матриц
Напоминание теории. Для квадратных невырожденных матриц определено понятие обратной матрицы.
Пусть A — квадратная невырожденная матрица. Матрица A − 1 называется обратной матрицей к A , если
AA − 1 = A − 1 A = I,
где I — единичная матрица.
В NumPy обратные матрицы вычисляются с помощью функции numpy.linalg.inv(a), где a — исходная матрица.
a = np.array([[1, 2, 1], [1, 1, 4], [2, 3, 6]], dtype=np.float32) b = np.linalg.inv(a)
print ("Матрица A:\n", a) print ("Обратная матрица к A:\n", b) print ("Произведение A на обратную должна быть единичной:\n", a.dot(b))
Матрица A: [[1. 2. 1.] [1. 1. 4.] [2. 3. 6.]] Обратная матрица к A: [[ 6. 9. -7.] [-2. -4. 3.] [-1. -1. 1.]] Произведение A на обратную должна быть единичной: [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
13. Собственные числа и собственные вектора матрицы
Напоминание теории. Для квадратных матриц определены понятия собственного вектора и собственного числа.
Пусть A — квадратная матрица и A ∈ ℝ n×n . Собственным вектором матрицы A называется такой ненулевой вектор x ∈ ℝ n , что для некоторого λ ∈ ℝ выполняется равенство Ax = λx . При этом λ называется собственным числом матрицы A . Собственные числа и собственные векторы матрицы играют важную роль в теории линейной алгебры и ее практических приложениях.
В NumPy собственные числа и собственные векторы матрицы вычисляются с помощью функции numpy.linalg.eig(a), где a — исходная матрица. В качестве результата эта функция выдает одномерный массив w собственных чисел и двумерный массив v, в котором по столбцам записаны собственные вектора, так что вектор v[:, i] соотвествует собственному числу w[i].
a = np.array([[-1, -6], [2, 6]]) w, v = np.linalg.eig(a)
print ("Матрица A:\n", a) print ("Собственные числа:\n", w) print ("Собственные векторы:\n", v)
Матрица A: [[-1 -6] [ 2 6]] Собственные числа: [2. 3.] Собственные векторы: [[-0.89442719 0.83205029] [ 0.4472136 -0.5547002 ]]
Обратите внимание: у вещественной матрицы собственные значения или собственные векторы могут быть комплексными.
14. Расстояния между векторами
Вспомним некоторые нормы, которые можно ввести в пространстве ℝ n , и рассмотрим, с помощью каких библиотек и функций их можно вычислять в NumPy.
p-норма
p-норма (норма Гёльдера) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ p = ( n ∑ i = 1 | xi | p ) 1 ⁄ p , p ≥ 1.
В частных случаях при: * p = 1 получаем ℓ1 норму * p = 2 получаем ℓ2 норму
Далее нам понабится модуль numpy.linalg, реализующий некоторые приложения линейной алгебры. Для вычисления различных норм мы используем функцию numpy.linalg.norm(x, ord=None, . ), где x — исходный вектор, ord — параметр, определяющий норму (мы рассмотрим два варианта его значений — 1 и 2). Импортируем эту функцию:
from numpy.linalg import norm
ℓ1 норма
ℓ1 норма (также известная как манхэттенское расстояние) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ 1 = n ∑ i = 1 | xi | .
Ей в функции numpy.linalg.norm(x, ord=None, . ) соответствует параметр ord=1.
a = np.array([1, 2, -3]) print('Вектор a:', a)
Вектор a: [ 1 2 -3]
print('L1 норма вектора a:\n', norm(a, ord=1))
L1 норма вектора a: 6.0
ℓ2 норма
ℓ2 норма (также известная как евклидова норма) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ 2 = √ ( n ∑ i = 1 ( xi ) 2 ) .
Ей в функции numpy.linalg.norm(x, ord=None, . ) соответствует параметр ord=2.
print ('L2 норма вектора a:\n', norm(a, ord=2))
L2 норма вектора a: 3.7416573867739413
Более подробно о том, какие еще нормы (в том числе матричные) можно вычислить, см. документацию.
15. Расстояния между векторами
Для двух векторов x = (x1, …, xn) ∈ ℝ n и y = (y1, …, yn) ∈ ℝ n ℓ1 и ℓ2 раccтояния вычисляются по следующим формулам соответственно:
ρ1 ( x, y ) = ‖ x − y ‖ 1 = n ∑ i = 1 | xi − yi |
ρ2 ( x, y ) = ‖ x − y ‖ 2 = √ ( n ∑ i = 1 ( xi − yi ) 2 ) .
a = np.array([1, 2, -3]) b = np.array([-4, 3, 8]) print ('Вектор a:', a) print ('Вектор b:', b)
Вектор a: [ 1 2 -3] Вектор b: [-4 3 8]
print ('L1 расстояние между векторами a и b:\n', norm(a - b, ord=1)) print ('L2 расстояние между векторами a и b:\n', norm(a - b, ord=2))
L1 расстояние между векторами a и b: 17.0 L2 расстояние между векторами a и b: 12.12435565298214
16. Скалярное произведение и угол между векторами
a = np.array([0, 5, -1]) b = np.array([-4, 9, 3]) print ('Вектор a:', a) print ('Вектор b:', b)
Вектор a: [ 0 5 -1] Вектор b: [-4 9 3]
Скалярное произведение в пространстве ℝ n для двух векторов x = (x1, …, xn) и y = (y1, …, yn) определяется как:
⟨x, y⟩ = n ∑ i = 1 xiyi.
Длиной вектора x = (x1, …, xn) ∈ ℝ n называется квадратный корень из скалярного произведения, то есть длина равна евклидовой норме вектора:
| x | = √ ( ⟨x, x⟩ ) = √ ( n ∑ i = 1 x 2 i ) = ‖ x ‖ 2.
Теперь, когда мы знаем расстояние между двумя ненулевыми векторами и их длины, мы можем вычислить угол между ними через скалярное произведение:
⟨x, y⟩ = | x | |y|cos(α) ⟹ cos(α) = ( ⟨x, y⟩ )/( | x | |y| ) ,
где α ∈ [0, π] — угол между векторами x и y .
cos_angle = np.dot(a, b) / norm(a) / norm(b) print ('Косинус угла между a и b:', cos_angle) print ('Сам угол:', np.arccos(cos_angle))
Косинус угла между a и b: 0.8000362836474323 Сам угол: 0.6434406336093618
17. Комплексные числа в питоне
Напоминание теории. Комплексными числами называются числа вида x + iy , где x и y — вещественные числа, а i — мнимая единица (величина, для которой выполняется равенство i 2 = − 1 ). Множество всех комплексных чисел обозначается буквой ℂ (подробнее про комплексные числа см. википедию).
В питоне комплескные числа можно задать следующим образом (j обозначает мнимую единицу):
a = 3 + 2j b = 1j
print ("Комплексное число a:\n", a) print ("Комплексное число b:\n", b)
Комплексное число a: (3+2j) Комплексное число b: 1j
С комплексными числами в питоне можно производить базовые арифметические операции так же, как и с вещественными числами:
c = a * a d = a / (4 - 5j)
print ("Комплексное число c:\n", c) print ("Комплексное число d:\n", d)
Комплексное число c: (5+12j) Комплексное число d: (0.0487804878048781+0.5609756097560976j)
Задания: (Блок 2)
Задание 3:
Рассмотрим сложную математическую функцию на отрезке [1, 15]:
f(x) = sin(x / 5) * exp(x / 10) + 5 * exp(-x / 2)
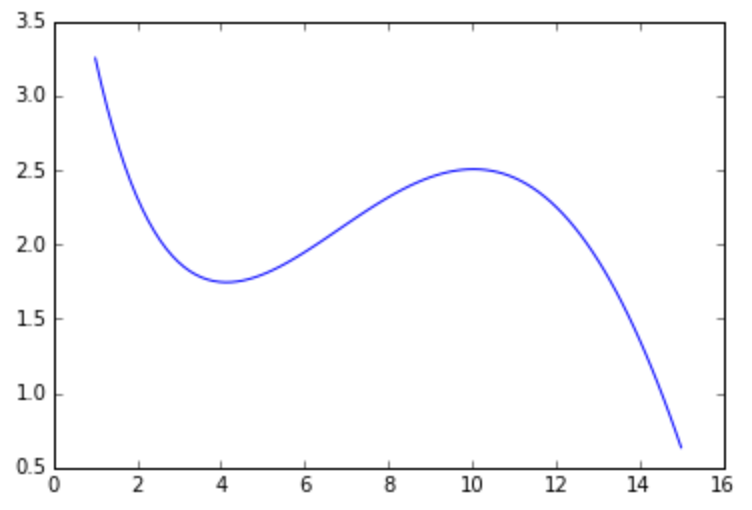
Она может описывать, например, зависимость оценок, которые выставляют определенному сорту вина эксперты, в зависимости от возраста этого вина. Мы хотим приблизить сложную зависимость с помощью функции из определенного семейства. В этом задании мы будем приближать указанную функцию с помощью многочленов.
Как известно, многочлен степени n (то есть w0 + w1x + w2x 2 + … + wnx n ) однозначно определяется любыми n + 1 различными точками, через которые он проходит. Это значит, что его коэффициенты w0 , … wn можно определить из следующей системы линейных уравнений:
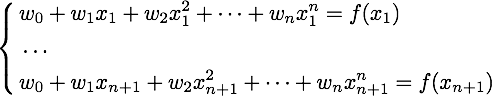
где через x1, . xn, xn + 1 обозначены точки, через которые проходит многочлен, а через f(x1), . f(xn), f(xn + 1) — значения, которые он должен принимать в этих точках.
Воспользуемся описанным свойством, и будем находить приближение функции многочленом, решая систему линейных уравнений.
- Сформируйте систему линейных уравнений (то есть задайте матрицу коэффициентов A и свободный вектор b) для многочлена первой степени, который должен совпадать с функцией f в точках 1 и 15. Решите данную систему с помощью функции scipy.linalg.solve. Нарисуйте функцию f и полученный многочлен. Хорошо ли он приближает исходную функцию?
- Повторите те же шаги для многочлена второй степени, который совпадает с функцией f в точках 1, 8 и 15. Улучшилось ли качество аппроксимации?
- Повторите те же шаги для многочлена третьей степени, который совпадает с функцией f в точках 1, 4, 10 и 15. Хорошо ли он аппроксимирует функцию? Коэффициенты данного многочлена (четыре числа в следующем порядке: w_0, w_1, w_2, w_3) являются ответом на задачу. Округлять коэффициенты не обязательно, но при желании можете произвести округление до второго знака (т.е. до числа вида 0.42)
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY.