CLIP от OpenAI: модель для обучения компьютерному зрению

Всем хорошо известно, что нейронные сети (НС) и, в частности, модели компьютерного зрения хорошо справляются с конкретными задачами, но зачастую не могут быть использованы в задачах, которым они не обучались. К примеру, модель, которая хорошо работает с информацией о продуктах питания, может не справляться с анализом снимков спутника.
CLIP – модель от OpenAI претендует на то, чтобы закрыть этот пробел.
Что подразумевается под классификацией? Имеется набор примеров, каждому из которых соответствует категория. Количество категорий ограничено. Модель обучается различать «кошек» и «собак», но при добавлении нового класса «дельфин» нам придется добавить примеры с изображением дельфинов и обучить модель заново, а хорошо работающей моделью признаем ту, которая верно определит на изображении дельфина. Однако CLIP устроен иначе и результатом будет вероятность того, что это изображение соответствует категории «кошек», «собак» или «дельфинов».
Предлагаю рассмотреть, как можно использовать CLIP для классификации фотографий людей. В моем примере представлена классификация известных людей. Вы их, конечно, узнаете, но для примера я изменю имена. Установим и запустим CLIP от PyTorch:
import subprocess CUDA_version = [s for s in subprocess.check_output(["nvcc", "--version"]).decode("UTF-8").split(", ") if s.startswith("release")][0].split(" ")[-1] print("CUDA version:", CUDA_version) if CUDA_version == "10.0": torch_version_suffix = "+cu100" elif CUDA_version == "10.1": torch_version_suffix = "+cu101" elif CUDA_version == "10.2": torch_version_suffix = "" else: torch_version_suffix = "+cu110" !pip install torch==1.7.1 torchvision==0.8.2 -f https://download.pytorch.org/whl/torch_stable.html ftfy regex import numpy as np import torch print("Torch version:", torch.__version__) !pip install gdown Скопируем репозитории CLIP:
!git clone https://github.com/openai/CLIP.git import sys from pathlib import Path clip_dir = Path(".").absolute() / "CLIP" sys.path.append(str(clip_dir)) print(f"CLIP dir is: ") import clip Установим предобученную модель:
import os device = "cuda" if torch.cuda.is_available() else "cpu" model, transform = clip.load("ViT-B/32", device=device) print(f"Model dir: ") Подготовим исходные данные. Для примера я взяла фотографии трех известных людей (2 женщины, 1 мужчина), по 4 — 6 изображений каждого из них. Фотографии хранятся в папках с именами Виктор, Тамара и Ирина.
!gdown https://ссылка_на_архив_clip !unzip clip_people.zip; rm clip_people.zip Downloading. From: https://ссылка_на_архив_clip To: /content/clip_people.zip 3.07MB [00:00, 62.4MB/s] Archive: clip_people.zip creating: clip_people/ creating: clip_people/Viktor/ extracting: clip_people/Viktor/1.jpg extracting: clip_people/Viktor/2.jpg extracting: clip_people/Viktor/3.jpg extracting: clip_people/Viktor/4.jpg extracting: clip_people/Viktor/5.jpg extracting: clip_people/Viktor/6.jpg creating: clip_people/Tamara/ extracting: clip_people/Tamara/1.jpg extracting: clip_people/Tamara/2.jpg extracting: clip_people/Tamara/3.jpg extracting: clip_people/Tamara/4.jpg extracting: clip_people/Tamara/5.jpg extracting: clip_people/Tamara/6.jpg creating: clip_people/Irina/ extracting: clip_people/Irina/1.jpg extracting: clip_people/Irina/2.jpg extracting: clip_people/Irina/3.jpg extracting: clip_people/Irina/4.jpg Для классификации изображений определим классы, которые могут быть представлены в виде текста, описывающего изображение. Например, «это изображение артиста». В этом случае артист и есть метка класса. Изображения, которые я хочу протестировать, хранятся в папках с именами классов:
import os # images we want to test are stored in folders with class names class_names = sorted(os.listdir('./clip_people/')) class_to_idx = class_names ['Viktor', 'Tamara', 'Irina'] class_captions = [f"An image depicting a " for x in class_names] class_captions ['An image depicting a Viktor', 'An image depicting a Tamara', 'An image depicting a Irina'] Далее токенизируем текст и вычисляем вложения из токенов
text_input = clip.tokenize(class_captions).to(device) print(f"Tokens shape: ") with torch.no_grad(): text_features = model.encode_text(text_input).float() text_features /= text_features.norm(dim=-1, keepdim=True) print(f"Text features shape: ") Для корректного отображения изображений воспользуемся набором данных ImageFolder от PyTorch и нормализуем снимки:
image_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073]).to('cpu') image_std = torch.tensor([0.26862954, 0.26130258, 0.27577711]).to('cpu') def denormalize_image(image: torch.Tensor) -> torch.Tensor: image *= image_std[:, None, None] image += image_mean[:, None, None] return image import matplotlib.pyplot as plt from PIL import Image from torchvision.datasets import ImageFolder from torch.utils.data import DataLoader dataset = ImageFolder(root="./clip_people", transform=transform) data_batches = DataLoader(dataset, batch_size=len(dataset), shuffle=False) Выведем все изображения из набора данных:
plt.figure(figsize=(10, 10)) for idx, (image, label_idx) in enumerate(dataset): cur_class = class_names[label_idx] plt.subplot(4, 4, idx+1) plt.imshow(denormalize_image(image).permute(1, 2, 0)) plt.title(f"") plt.xticks([]) plt.yticks([]) plt.tight_layout() 
Выполняем классификацию с помощью готовых меток. Считаем все изображения и истинные метки:
image_input, y_true = next(iter(data_batches)) image_input = image_input.to(device) with torch.no_grad(): image_features = model.encode_image(image_input).float() def show_results(image_features, text_features, class_names): # depends on global var dataset text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1) k = np.min([len(class_names), 5]) # top_probs, top_labels = text_probs.cpu().topk(k, dim=-1) text_probs = text_probs.cpu() plt.figure(figsize=(26, 16)) for i, (image, label_idx) in enumerate(dataset): plt.subplot(4, 8, 2 * i + 1) plt.imshow(denormalize_image(image).permute(1, 2, 0)) plt.axis("off") plt.subplot(4, 8, 2 * i + 2) y = np.arange(k) plt.grid() plt.barh(y, text_probs[i]) plt.gca().invert_yaxis() plt.gca().set_axisbelow(True) # plt.yticks(y, [class_names[index] for index in top_labels[i].numpy()]) plt.yticks(y, class_names) plt.xlabel("probability") plt.subplots_adjust(wspace=0.5) plt.show() show_results(image_features, text_features, class_names)
Вы можете заметить, что CLIP не очень хорошо справился с этими метками – правильно распознаны только 5 изображений из 16. Возможно, дело в незнакомых CLIP именах. Давайте поэкспериментируем и посмотрим, как это повлияет на результаты. Я изменю метки на более распространенные иностранные имена.
class_names = ['John', 'Kate', 'Jessica'] class_captions = [f"An image depicting a " for x in class_names] text_input = clip.tokenize(class_captions).to(device) with torch.no_grad(): text_features = model.encode_text(text_input).float() text_features /= text_features.norm(dim=-1, keepdim=True) show_results(image_features, text_features, class_names) 
У этого эксперимента результат лучше предыдущего – 13 из 16 изображений распознаны верно.
Проведем еще один эксперимент – классифицируем мужчин и женщин.
class_names = ['male', 'female'] class_captions = [f"An image depicting a " for x in class_names] text_input = clip.tokenize(class_captions).to(device) with torch.no_grad(): text_features = model.encode_text(text_input).float() text_features /= text_features.norm(dim=-1, keepdim=True) show_results(image_features, text_features, class_names) 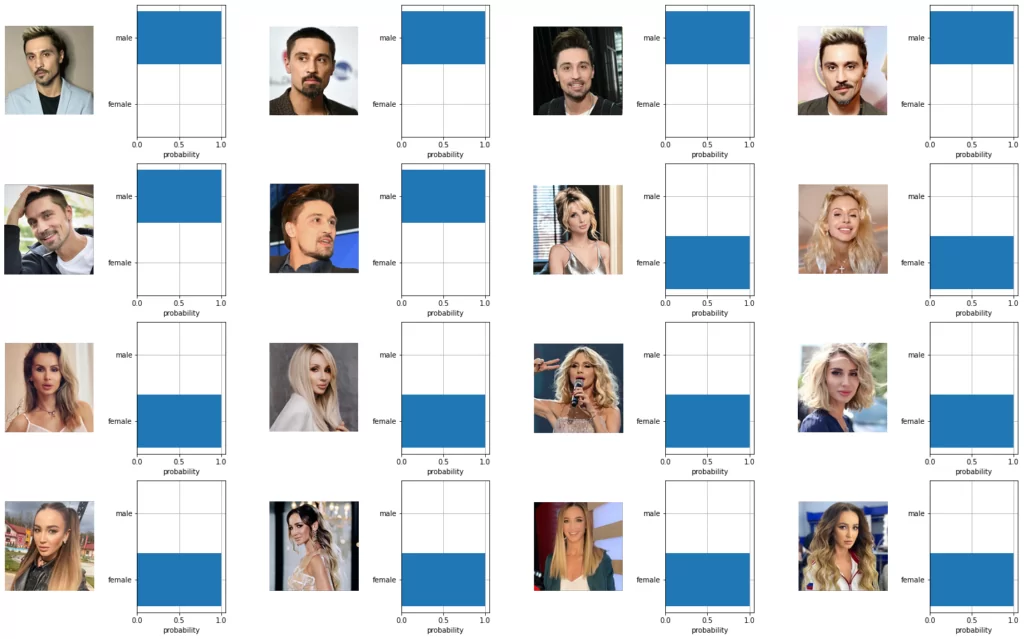
Результат этого эксперимента еще лучше – все 16 изображений распознаны правильно. Кроме уже продемонстрированных экспериментов по распознаванию людей и классификации по их полу, CLIP поможет определить вероятность присутствия различных предметов на изображениях (микрофон, гарнитура, украшения, очки и т.д.), а также их количество. На мой взгляд, это важная особенность CLIP может найти свое применение в практической деятельности аудитора: различить пустые страницы, схемы, диаграммы, технические чертежи; установить есть ли на изображении человека ключи, бейдж, медицинская маска и еще другие детали, распознавание которых в ручную отняло бы слишком много трудовых ресурсов.
Как работает Stable Diffusion: объяснение в картинках
Генерация изображений при помощи ИИ — одна из самых новых возможностей искусственного интеллекта, поражающая людей (в том числе и меня). Способность создания потрясающих изображений на основании текстовых описаний похожа на магию; компьютер стал ближе к тому, как творит искусство человек. Выпуск Stable Diffusion стал важной вехой в этом развитии, поскольку высокопроизводительная модель оказалась доступной широкой публике (производительная с точки зрения качества изображения, скорости и относительно низких требований к ресурсам и памяти).
Поэкспериментировав в генерацией изображений, вы можете задаться вопросом, как же она работает.
В этой статье я вкратце расскажу, как функционирует Stable Diffusion.

Stable Diffusion гибка, то есть может использоваться множеством разных способов. Давайте сначала рассмотрим генерацию изображений на основе одного текста (text2img). На картинке выше показан пример текстового ввода и получившееся сгенерированное изображение. Кроме превращения текста в изображение, другим основным способом применения модели является изменение изображений (то есть входными данными становятся текст + изображение).

Давайте начнём разбираться со внутренностями модели, потому что это поможет нам объяснить её компоненты, их взаимодействие и значение опций/параметров генерации изображений.
Компоненты Stable Diffusion
Stable Diffusion — это система, состоящая из множества компонентов и моделей. Это не единая монолитная модель.
Изучая внутренности, мы первым делом заметим, что в модели есть компонент понимания текста, преобразующий текстовую информацию в цифровой вид, который передаёт заложенный в текст смысл.

Мы начнём с общего обзора, а позже углубимся в подробности машинного обучения. Однако для начала можно сказать, что этот кодировщик текста — это специальная языковая модель Transformer (технически её можно описать как текстовый кодировщик модели CLIP). Она получает на входе текст и выдаёт на выходе список чисел (вектор), описывающий каждое слово/токен в тексте.
Далее эта информация передаётся генератору изображений, который состоит из двух компонентов.

Генератор изображений выполняет два этапа:
1- Создание информации изображения.
Этот компонент является секретным ингредиентом Stable Diffusion. Именно благодаря нему возник такой рост качества по сравнению с предыдущими моделями.
Этот компонент выполняется в несколько шагов (step), генерируя информацию изображения. Это параметр steps в интерфейсах и библиотеках Stable Diffusion, который часто по умолчанию имеет значение 50 или 100.
Этап создания информации изображения действует полностью в пространстве информации изображения (или в скрытом пространстве). Подробнее о том, что это значит, мы расскажем ниже. Это свойство ускоряет работу по сравнению с предыдущими моделями диффузии, работавшими в пространстве пикселей. Этот компонент состоит из нейросети UNet и алгоритма планирования.
Слово «диффузия» (diffusion) описывает происходящее в этом компоненте. Это пошаговая обработка информации, приводящая в конечном итоге к генерации высококачественного изображения (при помощи следующего компонента — декодера изображений).

2- Декодер изображений.
Декодер изображений рисует картину на основе информации, которую он получил на этапе создания информации. Он выполняется только один раз в конце процесса и создаёт готовое пиксельное изображение.

На изображении выше мы видим три основных компонента (каждый со своей собственной нейросетью), из которых состоит Stable Diffusion:
-
ClipText для кодирования текста.
Входные данные: текст.
Входные данные: эмбеддинги текста и исходный многомерный массив (структурированные списки чисел, также называемые тензором), состоящий из шума.
Входные данные: массив обработанной информации (размеры: (4,64,64))

Что такое диффузия?
Диффузия — это процесс, выполняемый внутри розового компонента «image information creator» (этапа создания информации изображения). Имея эмбеддинги токенов, описывающие введённый текст, и случайный начальный массив информации изображения (также они называются latent), процесс создаёт массив информации, который декодер изображения использует для рисования готового изображения.

Это процесс выполняется поэтапно. Каждый шаг добавляет больше релевантной информации. Чтобы представить процесс в целом, мы можем изучить массив случайных latent, и увидеть, что он преобразуется в визуальный шум. В данном случае визуальное изучение — это прохождение данных через декодер изображений.

Диффузия выполняется в несколько шагов, каждый из которых работает с входным массивом latent и создаёт ещё один массив latent, ещё больше напоминающий введённый текст, а вся визуальная информация модели собирается из всех изображений, на которых была обучена модель.

Мы можем визуализировать набор таких latent, чтобы увидеть, какая информация добавляется на каждом из шагов.

Наблюдать за этим процессом довольно увлекательно.
В данном случае нечто особо восхитительное происходит между шагами 2 и 4. Как будто контур возникает из шума.
Как работает диффузия
Основная идея генерации изображений при помощи диффузионной модели использует тот факт, что у нас есть мощные модели компьютерного зрения. Если им передать достаточно большой массив данных, эти модели могут обучаться сложным операциям. Диффузионные модели подходят к задаче генерации изображений, формулируя задачу следующим образом:
Допустим, у нас есть изображение, сделаем первый шаг, добавив в него немного шума.

Назовём «срез» (slice) добавленного нами шума «noise slice 1». Сделаем ещё один шаг, добавив к шумному изображению ещё шума («noise slice 2»).

На этом этапе изображение полностью состоит из шума. Теперь давайте возьмём их в качестве примеров для обучения нейронной сети компьютерного зрения. Имея номер шага и изображение, мы хотим, чтобы она спрогнозировала, сколько шума было добавлено на предыдущем шаге.

Хотя этот пример показывает два шага от изображения к полному шуму, мы можем управлять тем, сколько шума добавляется к изображению, поэтому можно распределить его на десятки шагов, создав десятки примеров для обучения на каждое изображение для всех изображений в обучающем массиве данных.

Красота здесь в том, что после того, как эта сеть прогнозирования шума начнёт работать правильно, она, по сути, сможет рисовать картины, удаляя шум на протяжении множества шагов.
Примечание: это небольшое упрощение алгоритма диффузии. На ресурсах по ссылкам в конце статьи представлено более подробное математическое описание.
Рисование изображений устранением шума
Обученный предсказатель шума может взять шумное изображение и количество шагов устранения шума, и на основании этого способен спрогнозировать срез шума.

Срез шума прогнозируется таким образом, что если мы вычтем его из изображения, то получим изображение, которое ближе к изображениям, на которых обучалась модель.

Если обучающий массив данных состоял из эстетически приятных изображений (например, LAION Aesthetics, на котором обучалась Stable Diffusion), то получившееся изображение будет иметь склонность к эстетической приятности.

В этом по большей мере и заключается описание генерации изображений диффузионными моделями, представленное в статье Denoising Diffusion Probabilistic Models. Теперь, когда мы понимаем, что такое диффузия, нам понятно, как работают основные компоненты не только Stable Diffusion, но и Dall-E 2 с Google Imagen.
Обратите внимание, что описанный выше процесс диффузии генерирует изображения без использования текстовых данных. В последующих разделах мы расскажем, как в процесс внедряется текст.
Увеличение скорости: диффузия сжатых (скрытых) данных, а не пиксельного изображения
Для ускорения процесса генерации изображений Stable Diffusion (по информации из исследовательской статьи) выполняет процесс диффузии не с самими пиксельными изображениями, а со сжатой версией изображения. В статье это называется «переходом в скрытое пространство».
Это сжатие (и последующая распаковка/рисование) выполняется при помощи автокодировщика. Автокодировщик сжимает изображение в скрытое пространство при помощи своего кодировщика, а затем воссоздаёт его при помощи декодера на основе только сжатой информации.

Далее со сжатыми latent выполняется прямой процесс диффузии. Используются срезы шума, применяемые к этим latent, а не к пиксельному изображению. То есть предсказатель шума на самом деле обучается прогнозировать шум в сжатом описании (в скрытом пространстве).

При помощи прямого процесса (с использованием кодировщика автокодировщика) мы генерируем данные для обучения предсказателя шума. После его обучения мы можем генерировать изображения, выполняя обратный процесс (при помощи декодера автокодировщика).

Эти два потока показаны на рисунке 3 статьи про LDM/Stable Diffusion:
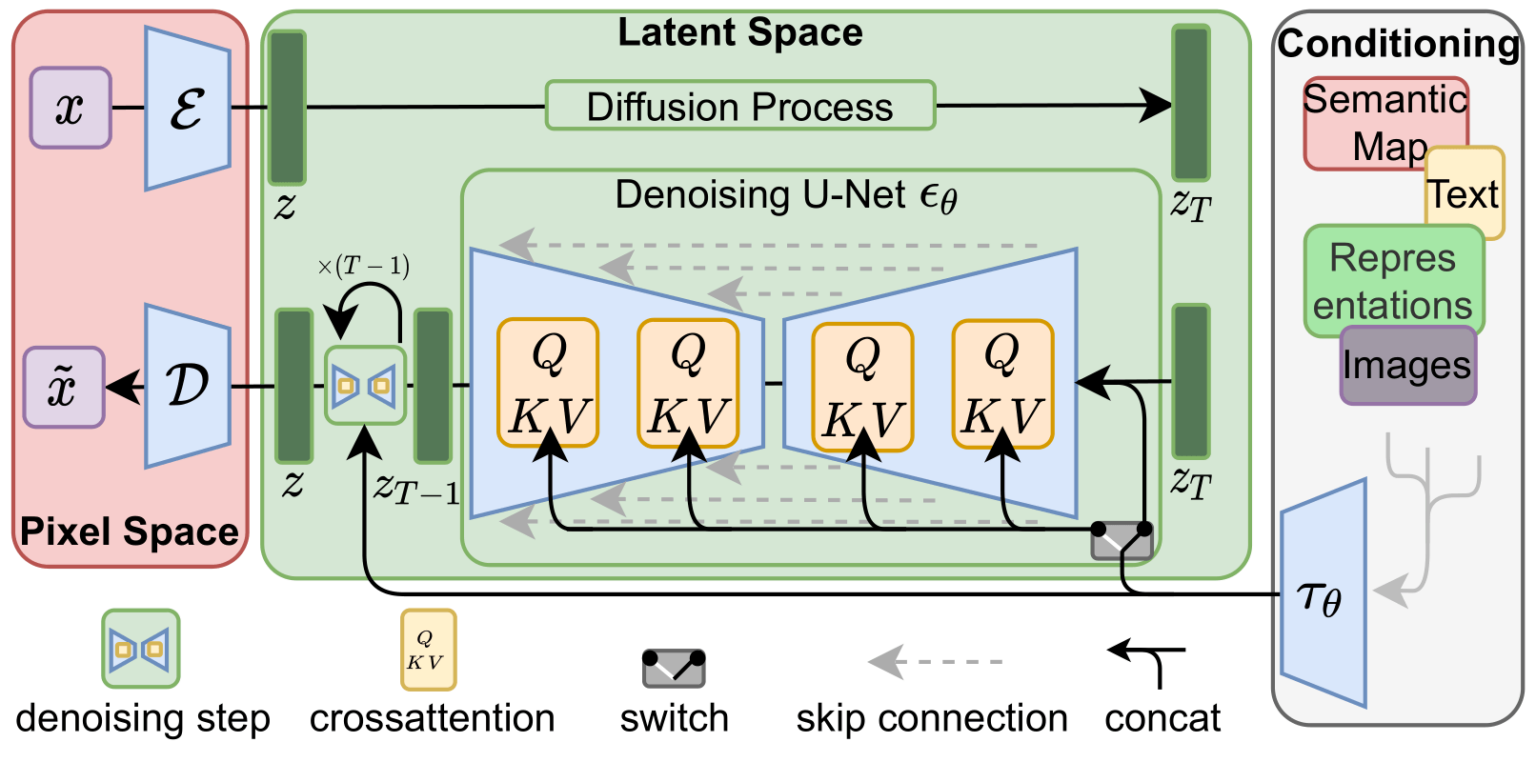
Также на этом рисунке показаны компоненты «согласования», которые в данном случае являются текстовыми строками, описывающими изображение, которое должна генерировать модель. Поэтому давайте рассмотрим эти текстовые компоненты.
Текстовый кодировщик: языковая модель Transformer
Языковая модель Transformer используется в качестве компонента понимания языка, она получает текстовую строку и создаёт эмбеддинги токенов. В опубликованной модели Stable Diffusion используется ClipText (модель на основе GPT), а в статье применяется BERT.
В статье, посвящённой Imagen, показано, что выбор языковой модели важен. Замена на более объёмные языковые модели сильнее влияет на качество генерируемого изображения, чем более объёмные компоненты генерации изображений.

Улучшение/увеличение языковых моделей существенно влияет на качество моделей генерации изображений. Источник: Статья про Google Imagen, написанная Saharia и соавторами. Рисунок A.5.
В первых моделях Stable Diffusion просто подключалась предварительно обученная модель ClipText, выпущенная OpenAI. Возможно, будущие модели перейдут на новые и гораздо более объёмные OpenCLIP-варианты CLIP. В эту новую группу входных векторов включены текстовые модели размерами до 354 миллионов параметров, в отличие от 63 миллионов параметров в ClipText.
Как обучается CLIP
CLIP обучается на массиве изображений и подписей к ним. Массив данных выглядит примерно так, только состоит из 400 миллионов изображений и подписей:

CLIP — это сочетание кодировщика изображений и кодировщика текста. Обучающий процесс модели можно упрощённо представить как кодирование изображения и его подписи кодировщиками изображений и текста.

Затем мы сравниваем получившиеся эмбеддинги при помощи косинусного коэффициента. В начале процесса обучения схожесть будет низкой, даже если тест описывает изображение правильно.

Мы обновляем две модели так, чтобы в следующий раз при создании эмбеддингов получившиеся эмбеддинги были схожими.

Повторяя этот процесс со всем массивом данных и группами входных векторов большого размера, мы получаем кодировщики, способные создавать эмбеддинги, в которых изображение собаки и предложение «a picture of a dog» схожи. Как и в word2vec, процесс обучения также должен включать в себя отрицательные примеры изображений и подписей, которые не совпадают, а модель должна присваивать им низкую оценку схожести.
Передача текстовой информации в процесс генерации изображений
Чтобы сделать текст частью процесса генерации изображений, нам нужно модифицировать предсказатель шума так, чтобы он использовал в качестве входных данных текст.

Теперь наш массив данных содержит закодированный текст. Так как мы работаем в скрытом пространстве, то входные изображения и прогнозируемый шум находятся в скрытом пространстве.

Чтобы лучше понять, как текстовые токены используются в Unet, давайте глубже разберёмся с Unet.
Слои предсказателя шума Unet (без текста)
Для начала рассмотрим диффузионную Unet, не использующую текст. Её входы и выходы выглядят так:
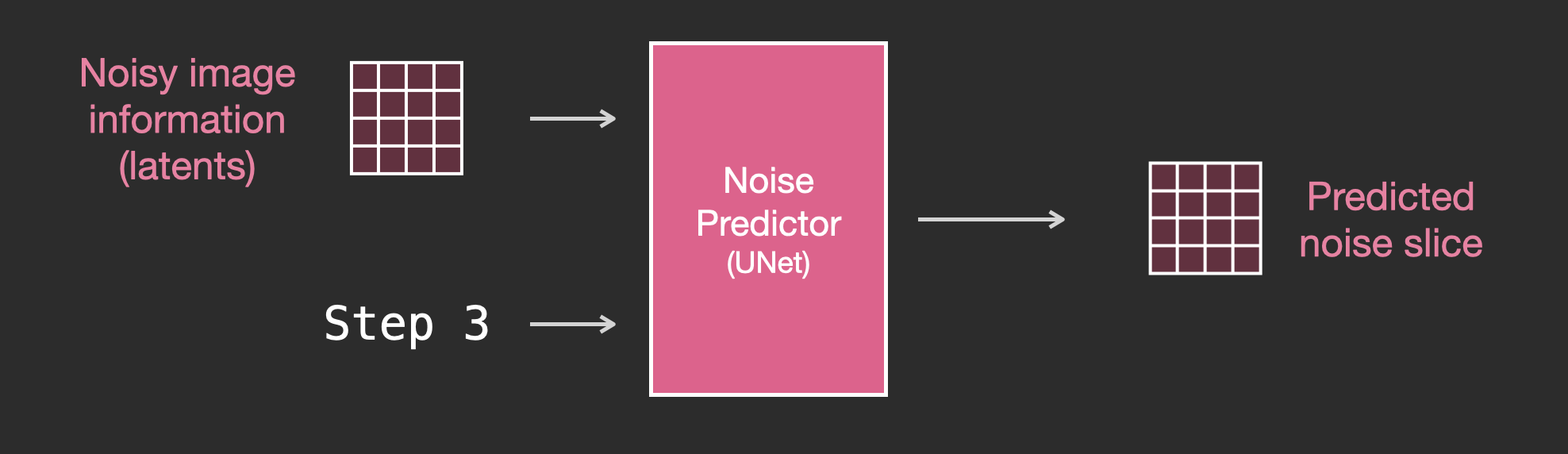
Внутри мы видим следующее:
- Unet — это последовательность слоёв, работающая над преобразованием массива latent.
- Каждый слой обрабатывает выходные данные предыдущего слоя.
- Часть выходных данных подается (через остаточные соединения) для обработки на дальнейших этапах сети.
- Шаг времени преобразуется в вектор эмбеддингов шага времени, который используется в слоях.

Слои предсказателя шума Unet с текстом
Давайте посмотрим, как изменить эту систему, чтобы уделить внимание тексту.

Основное изменение системы, которое необходимо для добавления поддержки текстового ввода (техническое название: text conditioning) — добавление слоя attention между блоками ResNet.
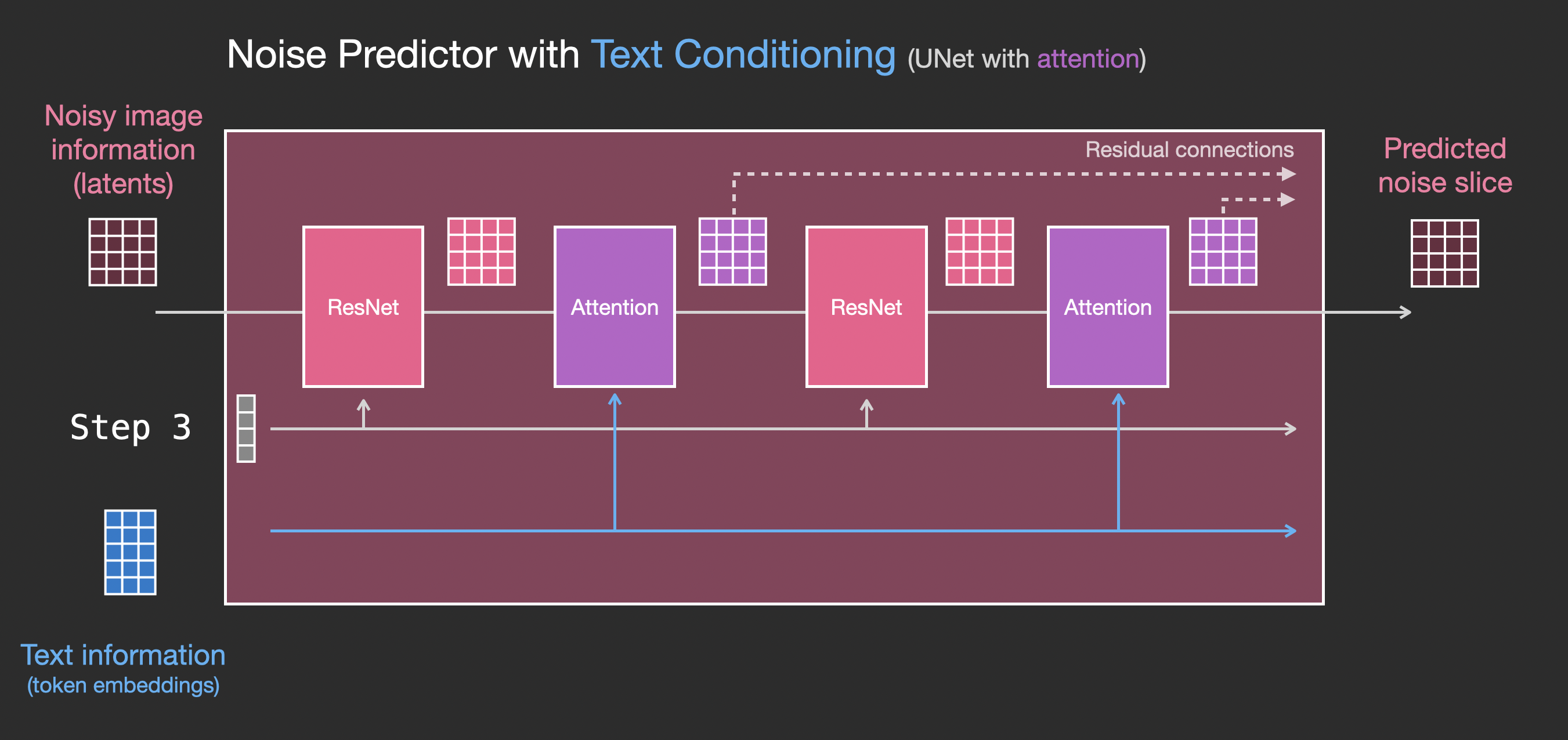
Обратите внимание, что блок resnet не смотрит непосредственно на текст. Слои attention объединяют эти текстовые описания в latent. И теперь следующий ResNet может использовать эту встроенную текстовую информацию в своей обработке.
Заключение
Надеюсь, это даст вам поверхностное понимание работы Stable Diffusion. В ней задействовано множество других концепций, но я считаю, что их проще понять, если вы знаете описанные выше строительные блоки. Для дальнейшего изучения можно воспользоваться представленными ниже полезными ресурсами.
Ресурсы
- У меня есть одноминутный клип на YouTube по использованию Dream Studio для генерации изображений при помощи Stable Diffusion.
- Stable Diffusion with �� Diffusers
- The Annotated Diffusion Model
- How does Stable Diffusion work? – Latent Diffusion Models EXPLAINED [Видео]
- Stable Diffusion — What, Why, How? [Видео]
- High-Resolution Image Synthesis with Latent Diffusion Models [Статья про Stable Diffusion]
- Более подробное изучение алгоритмов и математики представлено в статье Лилиан Венг What are Diffusion Models?
Благодарности
Благодарю Робина Ромбаха, Дэнниса Сомерса, Яна Сидякина и сообщество Cohere For AI за отзывы о ранних версиях этой статьи.
- stable diffusion
- нейронные сети
- text2img
- img2img
- генерация изображений
- Обработка изображений
- Машинное обучение
- Искусственный интеллект
Как использовать модель clip

Модель CLIP (Contrastive Language-Image Pre-training) является одной из самых инновационных разработок в области искусственного интеллекта. Она позволяет обучать компьютер распознавать и понимать содержание изображений и текстов на основе схожести и контрастности. Эта модель основывается на совместном предварительном обучении языковой и изображательной моделей, что открывает огромные возможности для решения различных задач в области компьютерного зрения и обработки естественного языка.
Преимущество модели CLIP заключается в ее способности использовать текстовые описания вместе с изображениями для обучения. Это позволяет ей понимать контекст изображений и устанавливать связи между ними и текстовыми данными. Такой подход существенно расширяет возможности машинного обучения и делает модель CLIP уникальной среди других аналогичных моделей.
С помощью модели CLIP можно решать множество задач, включая классификацию изображений, поиск похожих изображений, генерацию подписей к фотографиям и даже создание новых изображений на основе текстовых описаний. Все это делает модель CLIP мощным инструментом как для научных исследований, так и для практических применений в различных областях, включая компьютерное зрение, рекламу, медицину и многое другое.
Возможности модели clip в машинном обучении
Модель clip представляет собой инновационное решение в области машинного обучения, которое сочетает в себе методы компьютерного зрения и обработки естественного языка. Данная модель обладает значительными возможностями, которые делают ее востребованной в различных областях искусственного интеллекта.
1. Мультиязычность:
Модель clip способна работать с текстами и изображениями на различных языках, что позволяет использовать ее для межъязыковых задач. Она обучается на большом количестве данных на разных языках, что позволяет ей лучше понимать контекст и обрабатывать информацию на разных языках без необходимости дополнительной настройки.
2. Абстрактное понимание:
Модель clip не только распознает содержимое изображений и текстов, но и способна абстрагироваться от них и понимать более абстрактные концепции. Она может, например, анализировать не только конкретные объекты на фотографии, но и понимать, что фотография изображает прекрасный закат или печальный момент.
3. Связь текста и изображений:
Одной из основных возможностей модели clip является способность устанавливать связь между текстом и изображением. Она может оценивать тексты с точки зрения соответствия изображению и наоборот. Благодаря этому модель clip может быть использована для задач сопоставления текстов и изображений, отыскания связей между ними и визуального поиска информации.
4. Гибкость и адаптируемость:
Одним из важных преимуществ модели clip является ее гибкость и адаптируемость. Она может быть дообучена на новых данных и улучшена в конкретных задачах. Модель clip может быть приложена в множестве областей, таких как компьютерное зрение, обработка естественного языка, рекомендательные системы и т.д.
5. Высокая точность:
Современные исследования показывают, что модель clip достигает высоких показателей точности в широком спектре задач, таких как классификация изображений, определение похожих изображений, поиск по тексту и других. Ее точность является одной из лучших среди существующих моделей, что делает ее незаменимой в решении сложных и важных задач.
6. Простота в использовании:
Модель clip разработана с учетом не только своих возможностей, но и удобства использования. Она предоставляет простой интерфейс и легко интегрируется в различные системы. Благодаря этому, модель clip может быть применена не только исследователями и специалистами в области машинного обучения, но и разработчиками коммерческих приложений, упрощая процесс интеграции.
Модель clip представляет собой важный инструмент в задачах, связанных с обработкой текстов и изображений, визуальным поиском информации, классификацией и других задачах машинного обучения. Ее уникальные возможности позволяют использовать ее в различных областях искусственного интеллекта и значительно улучшить результаты работы таких систем.
Решение сложных задач компьютерного зрения
Модель CLIP (Contrastive Language-Image Pre-training) представляет собой инновационное решение для решения сложных задач компьютерного зрения. Она основана на идеях совместного обучения и проекции изображений и текстов, что позволяет модели понимать связь между ними и лучше работать с мультимодальными данными.
Одной из сложных задач, которые модель CLIP может решать, является классификация изображений. Благодаря обучению на большом количестве размеченных данных, модель может точно определять объекты на изображении и относить их к определенным категориям. Это полезно в таких областях, как медицина, автоматическое распознавание лиц, контроль качества и многое другое.
Кроме того, модель CLIP может использоваться для поиска по изображениям. Она способна находить похожие изображения и связанный с ними текстовый контент, что позволяет сократить время и усилия, затраченные на поиск нужной информации. С помощью этой модели можно эффективно работать с большими базами данных изображений и проводить анализ исследовательских данных.
Не менее важной задачей, которую модель CLIP может решать, является генерация описаний к изображениям. Благодаря обучению на большом количестве текстовых данных, модель способна автоматически создавать описание к изображению, а также делать выводы и формулировать суждения на основе визуальной информации. Это может быть полезно, например, для создания систем аннотирования изображений и генерации уникального контента.
В итоге, модель CLIP представляет собой мощный инструмент для решения широкого спектра сложных задач компьютерного зрения. Она сочетает в себе преимущества обучения с подкреплением и глубокого обучения, что позволяет ей эффективно работать с различными типами данных и проводить комплексный анализ мультимодальной информации. Применение модели CLIP может значительно улучшить качество и эффективность решения задач компьютерного зрения.
Повышение качества семантического поиска
Семантический поиск является одним из ключевых инструментов в современных системах информационного поиска. Он представляет собой метод поиска информации на основе смыслового содержания запроса пользователя. Однако, для достижения максимальной эффективности и точности поисковой системы, необходимо использовать соответствующие модели машинного обучения.
Одной из наиболее эффективных и широко используемых моделей машинного обучения для повышения качества семантического поиска является модель clip (Contrastive Language-Image Pretraining). Данная модель обучается с учителем на множестве мультимодальных данных, состоящих из пар изображений и текстовых описаний.
Преимуществом модели clip является то, что она способна извлекать семантическое представление для широкого спектра объектов, даже если для них нет разметки или они неизвестны. Это позволяет повысить качество семантического поиска и улучшить сопоставление между текстовыми запросами и изображениями.
Модель clip использует принцип контрастивного обучения, который заключается в сопоставлении пар изображений и текстовых описаний. Она обучается на огромном наборе пар изображений и текстовых описаний, где модель учится предсказывать, какое описание соответствует конкретному изображению, и наоборот. Таким образом, модель получает представления для изображений и текстовых описаний, которые учитывают их семантическое содержание и пригодны для семантического поиска.
При использовании модели clip в семантическом поиске происходит сопоставление текстовых запросов пользователя и изображений на основе их семантического содержания. Модель clip позволяет определить сходства и различия между запросами и изображениями, что позволяет более точно и эффективно находить соответствующую информацию в больших базах данных. Таким образом, использование модели clip позволяет повысить качество семантического поиска и обеспечить более релевантные результаты для пользователей.
Создание автономной системы распознавания объектов
Создание автономной системы распознавания объектов является одной из важнейших задач в области компьютерного зрения и машинного обучения. Такая система способна самостоятельно определить и идентифицировать объекты на изображениях или видео.
Для успешной реализации автономной системы распознавания объектов могут использоваться различные методы и алгоритмы, однако одним из наиболее эффективных и популярных подходов является использование модели CLIP (Contrastive Language-Image Pretraining).
Модель CLIP — это современная модель, разработанная командой OpenAI, которая предназначена для обучения машинного обучения на основе изображений и текста. Модель обучается на парах изображений и соответствующих текстовых описаний, что позволяет ей устанавливать связи между содержанием изображений и текстовых контекстом.
Преимущества использования модели CLIP для создания автономной системы распознавания объектов:
- Универсальность. Модель CLIP обладает значительной гибкостью и способна работать с различными типами данных, включая изображения, тексты и их сочетание.
- Обучение без учителя. Модель CLIP обучается путем максимизации сходства между изображением и текстом, что позволяет ей находить семантически связанные пары.
- Масштабируемость. Модель CLIP обучается на большом объеме данных, что позволяет ей обладать широкими возможностями распознавания объектов.
- Высокая точность. При использовании модели CLIP достигается высокая точность распознавания объектов, так как модель учитывает как визуальную, так и текстовую информацию.
Для создания автономной системы распознавания объектов на основе модели CLIP необходимо подготовить обучающий набор данных, включающий изображения и соответствующие им текстовые описания. Затем модель обучается на этих данных, что позволяет ей научиться распознавать и идентифицировать объекты на основе текстовых и визуальных контекстов.
Пример таблицы с объектами и соответствующими текстовыми описаниями
После обучения модель может быть использована для распознавания объектов на новых изображениях или в видеопотоке. Автономная система распознавания объектов, основанная на модели CLIP, может быть использована в различных областях, включая автономную навигацию роботов, видеонаблюдение, решение задач в медицине и многое другое.
В заключение, создание автономной системы распознавания объектов на основе модели CLIP является эффективным и универсальным подходом, который позволяет объединить визуальные и текстовые данные для более точного и гибкого распознавания объектов на изображениях и видео.
Улучшение процесса генерации текста и перевода
Использование модели CLIP в машинном обучении позволяет значительно улучшить процесс генерации текста и перевода, применяемый в различных приложениях и сервисах.
Модель CLIP, разработанная командой OpenAI, объединяет в себе преимущества глубокого обучения и сверточных нейронных сетей. Она обучена на большом наборе данных, что позволяет ей анализировать контекст и смысл изображений и текста, а также находить связи между ними.
Одной из ключевых функций модели CLIP является возможность генерирования текста на основе заданных изображений. Это полезно, например, в задачах описания и классификации изображений. Модель способна выдавать верные и содержательные описания, применяя свои знания и понимание взаимосвязей между изображениями и словами.
Кроме того, модель CLIP может быть использована и для задачи перевода. Она позволяет более точно и качественно переводить текст с одного языка на другой. Модель способна учесть не только лексическое значение отдельных слов, но и их смысловые связи и контекст, что делает ее перевод более естественным и точным.
Одним из преимуществ модели CLIP является ее универсальность. Она может быть применена в различных областях и с разными типами данных. Благодаря своим возможностям анализировать и понимать текст и изображения, модель способна подстраиваться под конкретные задачи и давать качественные результаты.
Таким образом, использование модели CLIP в машинном обучении позволяет улучшить процесс генерации текста и перевода, делая его более точным, содержательным и естественным. Это открывает новые возможности для различных приложений и сервисов, где требуется генерация текста на основе изображений и перевод с высокой точностью.
Вопрос-ответ
Для чего можно использовать модель CLIP в машинном обучении?
Модель CLIP может быть использована для решения различных задач в машинном обучении, таких как классификация изображений, векторизация изображений и текстов, поиск похожих изображений и многое другое. Благодаря своей универсальности и способности работать с разными видами данных, CLIP становится мощным инструментом в области машинного обучения.
Как работает модель CLIP?
Модель CLIP основана на комбинации нейронной сети обработки изображений и нейронной сети обработки текста. Она позволяет связать изображения и соответствующие им описания или заголовки, создавая векторные представления для каждого пары изображение-текст. Затем, используя эти векторные представления, CLIP может выполнять различные задачи, такие как классификация, поиск и сопоставление изображений и текстов.
В чем преимущество модели CLIP перед другими моделями в машинном обучении?
Одним из основных преимуществ модели CLIP является ее универсальность. Она может работать с разными типами данных — изображениями и текстами — без необходимости предварительного обучения на большом объеме данных. Кроме того, в отличие от других моделей, CLIP не требует разметки данных, так как она использует самонадзорную обучение, что делает ее более гибкой и удобной в использовании.
Каким образом модель CLIP помогает решать задачи в машинном обучении?
Модель CLIP создает векторные представления для изображений и текстов, что позволяет ей выполнять разнообразные задачи в машинном обучении. Например, она может классифицировать изображения и тексты, искать похожие изображения, сравнивать и сопоставлять изображения и тексты, а также выполнять другие операции, связанные с анализом и обработкой данных.
Для чего нужна модель clip

В статье пойдёт речь о том, как можно автоматически разделить датасет изображений на кластеры, которые поделены по качественному контекстному признаку, благодаря эмбедингам из нашумевшей нейронной сети CLIP от компании Илона Маска. Расскажу на примере контента из нашего приложения iFunny.
Кластеризация считается unsupervised задачей — это значит, что нет никакой явной разметки целевых значений, то есть нет «учителя». В нашем случае мы загружаем некий датасет картинок и хотим произвольно, но качественно побить его на кластеры.
Например, набор изображений животных может разделиться на кластеры по виду, по полосатости, по количеству лап или другим признакам. В любом случае ожидается понятная логика разбивки, которую можно дальше использовать для других задач.
Под катом расскажу, как мы построили логичную кластеризацию с помощью библиотеки HDBSCAN и векторов из нейронной сети CLIP, и каких результатов добились на выходе.
Что такое нейросеть CLIP
В январе 2021 года компания Илона Маска OpenAI выпустила нейросеть CLIP (официальный сайт и код на GitHub). Её обучали обобщать огромное количество категорий, чтобы затем использовать в разных ML-задачах. Разметки классов под конкретную задачу в ней нет, зато есть пары изображений и их текстовые описания в одном пространстве. Отсюда вытекает главный плюс — данную сеть можно использовать в задачах классификации изображений даже без дообучения (zero-shot).
Нейросеть CLIP обучена на 400 миллионов пар изображений и текста, каждая из которых подается на вход нейросети и объединяется с другими парами в батч. Затем сеть обучается предсказывать, какие из пар картинок в батче действительно схожи друг с другом. Тем самым векторные представления в паре текста и изображения сближаются во время обучения.
Обученная модель позволяет одновременно получать эмбединги по произвольному тексту и изображению — то есть с ней можно сравнивать текст и картинки в едином пространстве. Фактически это позволяет комбинировать категории и классифицировать изображения по более сложным текстовым описаниям.Приведу пример. Раньше, используя обучение с «учителем», модели отличали в основном лишь односложные и крупные категории вроде «cat» или «dog». А сейчас могут отличать лежащих котов от прыгающих и не только. Можно отличать изображения по стилю, наличию известных личностей на кадре, количеству предметов — многие подобные комбинации работают без дополнительного обучения уже из коробки.
Работает это так: в нейросеть подаётся изображение и текст, а она возвращает векторы изображения и текста. Затем можно посчитать косинусное расстояние и понять, насколько данный текст похож на изображение. В задаче классификации изображений можно выбирать класс по наибольшей близости векторов картинки и текстового описания класса:
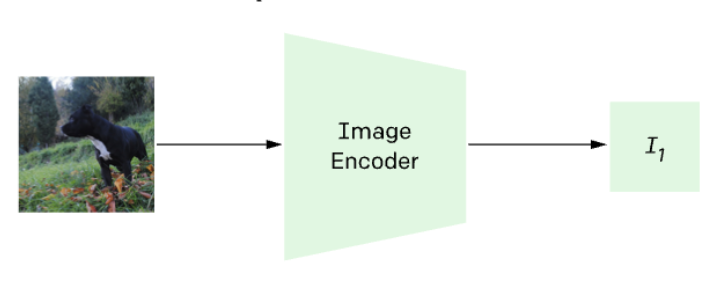
CLIP имеет кодировщик изображений (Image Encoder) и кодировщик текста (Text Encoder), которые преобразуют данные в векторное пространство и предсказывают, какие изображения с какими текстами были соединены.

Для кластеризации изображений в iFunny мы не используем тексты, но используем Image Encoder, который на выходе даёт высокосодержательные векторы, описывающие изображение в многомерном пространстве признаков.
По сути, берём только эту часть из CLIP:
Выполняем кластеризацию изображений
Нам нужно собрать вектор I(x) для каждого изображения в датасете и затем построить кластеризации этих векторов.
В общих чертах кластеризацию можно изобразить так:
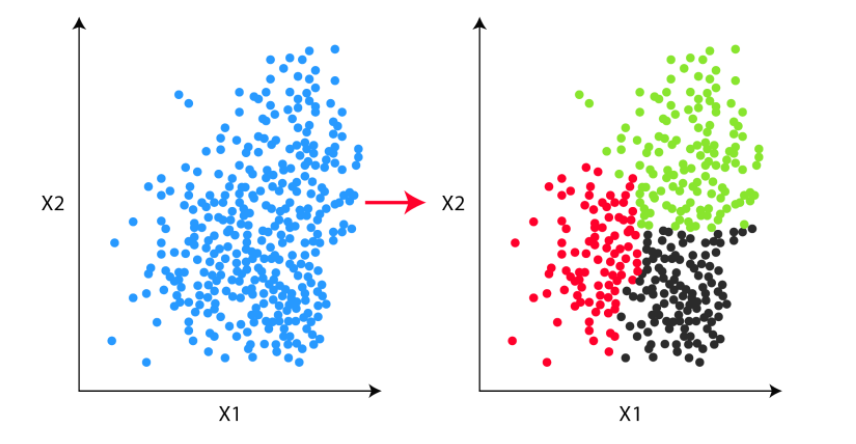
Есть набор точек/векторов в неком пространстве, который нужно разделить на n кластеров. В нашем случае берём векторы из картиночной модели CLIP. На картинке простой пример в двумерном пространстве, но модель из CLIP отдает вектор длиной 512 признаков — а это довольно много для обычных алгоритмов кластеризации.
В таких случаях стоит воспользоваться алгоритмами понижения размерности — например, PCA, TSNE или UMAP. Для кластеризации мы используем библиотеку HDBSCAN, основанную на базе одноименного алгоритма.
Не буду приводить весь код обучения, так как он специфичен под наши задачи, но опишу необходимые шаги, если захотите повторить кластеризацию на своих данных.
1. После сбора датасета, нужно собрать вектор из модели CLIP по каждой картинке. Для этого устанавливаем библиотеку CLIP и используем только функцию encode_image. Предварительно готовим изображения в torch.Tensor с помощью Pillow, как это делается в самой библиотеке CLIP.
image = prepare_pil_image(image, transform).to(device) image_features = self.model.encode_image(image).cpu().numpy()На выходе получится массив размера [n, 512], где n — количество изображений в датасете, а 512 — число признаков для каждого изображения из модели CLIP. Затем делим полученный массив на набор для обучения (train_embeddings) и для теста (test_embeddings).
2. Далее используем библиотеку umap-learn. С её помощью учим и сокращаем размерность до 2-5 признаков. Гиперпараметры приведены для примера, скорее всего для вашего датасета лучший результат будет при других значениях.
dimension_model = umap.UMAP(n_neighbors=70, n_epochs=300, min_dist=0.03, n_components=5, random_state=35) train_clusterable_embedding = dimension_model.fit_transform(train_embeddings)3. Затем на уменьшенных векторах строим кластеризацию. Для этого создаем модель HDBSCAN, обучаем и собираем информацию о том, какая картинка какому кластеру соответствует и с какой вероятностью.
cluster_model = hdbscan.HDBSCAN( min_cluster_size=1000, alpha=2., cluster_selection_method="leaf", prediction_data=True ) cluster_model.fit_predict(train_clusterable_embedding) train_labels, train_probabilities = hdbscan.approximate_predict(cluster_model, train_clusterable_embedding) test_labels, test_probabilities = hdbscan.approximate_predict(cluster_model, test_clusterable_embeddings)На тестовой выборке (test_clusterable_embeddings) можно оценить качество кластеризации на новых данных.
Результаты
Итого у нас был на руках датасет на 150 000 изображений после удаления дубликатов. По времени вышло примерно так:
- Обучение umap и HDBSCAN — около 2 часов.
- Кластеризация на проде — 1-2 секунды на 1 изображение.
Теперь посмотрим на получившиеся в наших экспериментах кластеры. Получились весьма интересные и показательные категории:



Также в виде отдельных кластеров выделились: животные, политика, 4chan, аниме, скриншоты твиттера, скриншоты приложения iFunny, шутки про США и другие страны, селфи.Из интересного — кластеризатор выделил в отдельную категорию мемы с Doge, знаменитой собакой породы сиба-ину:

Минусы подхода
- Тяжело получить качественное разделение на кластеры. Мы экспериментировали с параметрами UMAP и HDBSCAN, но все равно ошибки остаются, и часть сложного контента попадает в кластер «другое».
- Количество и логика кластеров может меняться от случайных параметров. Но если вы точно знаете, на какие классы хотите разделить изображения, то возможно лучшим решением будет разметить изображения и применить fine-tuning к той же модели CLIP.
- Модели требуют времени и памяти на инференсе. Для ускорения в продакшене можно использовать GPU.
Где использовать подход
Но есть и плюсы. Вот некоторые примеры, где можно применять такой подход кластеризации контента:
- Для исследование контента. Можно брать контент только одной категории (или от одной группы юзеров) и смотреть, на какие кластеры его стоит разделить. Так можно лучше понять свою аудиторию.
- Для получения предварительных классов для дальнейшей разметки. Например, если вам нужны только животные, то можно брать их из кластера «животные», но удалять на стадии разметки ошибки кластеризации. Это ускорит время разметки.
- Для получения признаков для других моделей, например, рекомендаций. Даже с ошибками в кластеризации разделение по большей части выглядит логичным и точным. Таким образом, можно улучшать метрики качества рекомендации контента в ленте.
- Для быстрых экспериментов с одной категорией контента. Можно взять, скажем, кластер с едой и сделать кнопку поиска только по фотографиям еды.
Заключение
Модель CLIP отдает качественные признаки изображений, по которым можно получить кластеризацию, действительно отражающую логику и категории внутри вашего датасета. Сочетанием UMAP и HDBSCAN можно легко добиться среднего количества качественных кластеров (10-30) почти без пересечений.
Результаты нас в целом устроили. Эту кластеризацию можно делать без разметки, а затем полученные кластеры использовать в других задачах.
Animation Clip
Анимационные клипы — это крошечные строительные блоки анимации в Unity. Они представляют собой отдельные элементы движения, такие как RunLeft (бег в левую сторону), Jump (прыжок) или Crawl (ползание) и могут быть объединены разными способами, образуя живые и реалистичные анимации (см. Конечные автоматы в анимации, Animator Controller, Blend Trees). Анимационные клипы можно выбрать в данных, импортированных из FBX (см. страницу Вкладка Animations импортера FBX), при выборе клипа вы увидите следующий набор свойств:
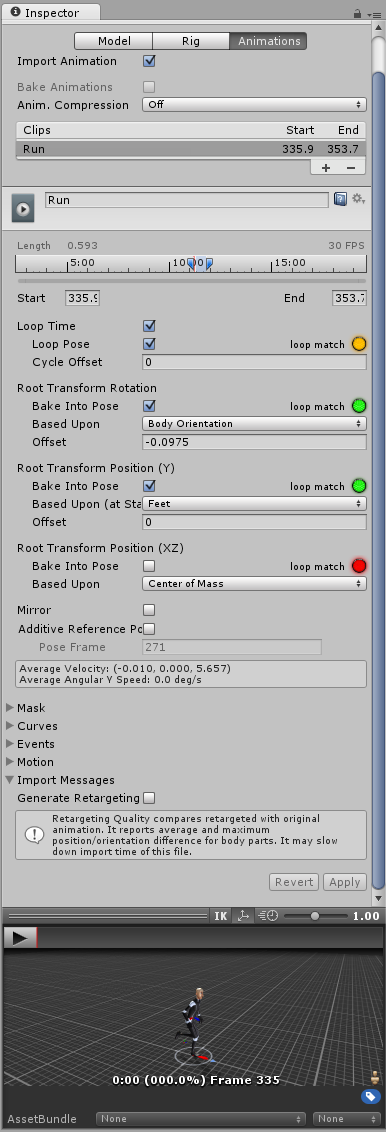
Asset-specific properties
(These properties apply to all animation clips defined within this asset).
| Свойство: | Функция: |
|---|---|
| Import Animation | Should any animation be imported from this asset?. If un-checked, all other options on this page are hidden and no animation is imported. |
| Bake Animations | Animations created using IK or Simulation will be baked to forward kinematic keyframes. This option is only available for Maya, 3dsMax and Cinema4D files. |
| Resample Curves | When enabled, animation curves will be resampled on every frame. You should enable this if you’re having issues with the interpolation between keys in your original animation. Disable this to keep animation curves as they were originally authored. This option is only available for Generic animtions, not Humanoid animations. |
| Import Animation | Should any animation be imported from this asset?. If un-checked, all other options on this page are hidden and no animation is imported. |
| Anim. Compression | The type of compression to use when importing the animation |
| — Off | No Compression |
| — Keyframe Reduction | Removes redundant keyframes |
| — Optimal | Let unity decide how to compress. Either by keyframe reduction or by using dense format. Unity will pick the most optimal of the two. |
Clip-specific properties
(These properties are set separately for each animation clip defined within this asset).
| Свойство: | Функция: |
|---|---|
| Name | Имя клипа. |
| Source Take | Метка в исходном файле анимации, которую следует использовать в качестве данного клипа (эта опция отобразится, если в анимационном файле более одной метки). Это то, что разделяет анимации между собой в Motionbuilder, Maya и других пакетах для 3D моделирования. Unity может импортировать такие метки как отдельные клипы, или вы можете создать клип из всего файла либо из отдельной метки. |
| Start | Начальный кадр клипа. |
| End | Конечный кадр клипа. |
| Loop Time | Включите эту опцию, чтобы анимационный клип проигрывался и начинался заново при достижении окончания. |
| Loop Pose | Включите для плавного зацикливания движения. |
| Cycle Offset | Смещение для цикла зацикленной анимации, если нам требуется начать его с другого времени. |
| Root Transform Rotation | |
| Bake into Pose | Включите, чтобы “запечь” корневое вращение в движение костей. Отключите, чтобы корневое вращение хранилось как root motion. |
| Based Upon | На чём основывается корневое вращение. |
| — Original | Сохраняет вращение таким, каким оно было создано в исходном файле. |
| — Body Orientation | Сохраняет прямое направление верхней части тела. |
| Offset | Смещение корневого вращения (в градусах). |
| Root Transform Position (Y) | |
| Bake into Pose | Включите, чтобы “запечь” вертикальный root motion в движение костей. Отключите, чтобы вертикальный root motion хранился как root motion. |
| Based Upon | На чём основывается вертикальное корневое положение. |
| — Original | Сохраняет вертикальное положение таким, каким оно было создано в исходном файле. |
| — Center of Mass | Сохраняет центр масс совмещённым с положением корневой трансформации. |
| — Feet | Сохраняет ступню совмещённой с положением корневой трансформации. |
| Offset | Смещение вертикального корневого положения. |
| Root Transform Position (XZ) | |
| Bake into Pose | Включите, чтобы “запечь” горизонтальный root motion в движение костей. Отключите, чтобы горизонтальный root motion хранился как root motion. |
| Based Upon | На чём основывается горизонтальное корневое положение. |
| — Original | Сохраняет горизонтальное положение таким, каким оно было создано в исходном файле. |
| — Center of Mass | Сохраняет центр масс совмещённым с положением корневой трансформации. |
| Offset | Смещение горизонтального корневого положения. |
| Mirror | Зеркально отразить этот клип (поменять местами левую и правую части). |
| Additive Reference Pose | When enabled, allows you to define the reference pose used as the base for the additive animation. Also, a blue marker becomes visible in the Start/End timeline editor:  . You can specify the reference pose by entering a frame number in the “Pose Frame” field, or by dragging the blue marker in the timeline. . You can specify the reference pose by entering a frame number in the “Pose Frame” field, or by dragging the blue marker in the timeline. |
| Mask | Маска для тела (Body mask) и маска трансформаций (Transform mask), применённые к данному анимационному клипу (см. секцию про маски для тела). |
| Curves | Кривые, связанные с параметрами (см. раздел про кривые в Mecanim). |
| Events | Используется для создания нового события на клипе (см. раздел Использование событий в анимации). |
| Motion | Allows you to define a custom root motion node (see Selecting a Root Motion Node). |
| Import Messages | Gives you information about how your animation was imported, including an optional ‘Retargeting Quality Report’. |
Создание клипов — это по сути создание начальной и конечной точек для сегментов анимации. Чтобы клипы плавно зацикливались, они должны быть размечены так, чтобы первый и последний кадры совпадали наилучшим образом для зацикливания. Для дополнительной информации на эту тему, прочтите раздел Зацикливание анимационных клипов.
Animation Import Warnings
If any problems occured during the animation import process, a warning will be displayed at the top of the Animations Import inspector, like this:

The warnings do not necessarily mean your animation has not imported or will not work. It may just mean that the imported animation could look slightly different to the source animation. The detail of the warnings, if any, are displayed further down the inspector under the “Import Messages” section. The animation import warnings that you might recieve are as follows:
- Default bone length found in this file is different from the one found in the source avatar.
- Inbetween bone default rotation found in this file is different from the one found in the source avatar.
- Source avatar hierarchy doesn’t match one found in this model.
- This animation has Has translation animation that will be discarded.
- Humanoid animation has inbetween transforms and rotation that will be discarded.
- Has scale animation that will be discarded.
All these messages indicate that some data present in your original file was omitted when Unity imported and converted your animation to its own internal format. These warnings essentially tell you that the retargeted animation may not exactly match the source animation.
Модельный клип

Стоимость: 15 000 ₽
Короткий видеофайл с демонстрацией способностей модели и умения работать перед камерой .
Видеосъемка и монтаж работы ребенка на камеру:
Модельные навыки
Позирование
Танцевальные движения
Пластика (повороты, развороты, раскованность).
Модельные клипы востребованы у зарубежных брендов, например, Zara. Демонстрирует раскрепощенность в работе ребенка на площадке, его движения на камеру, мимика, пластика, эмоциональность. По желанию заказчика возможно приглашение визажиста, стилиста. Оплачивается дополнительно.
Срок изготовления – 30 дней
Для заказа услуги — свяжитесь с нами по номеру телефона +7 919 960 11 55 или оставьте свои контактные данные в блоке «связаться с нами»
Знакомимся с Clips
Clips — это приложение iOS, в котором можно делать отличные видео с текстом, графикой и разными эффектами. А потом делиться ими со всем миром.
Для начала сюжет.
Пользоваться приложением очень легко. Нажмите и удерживайте кнопку записи, чтобы начать съёмку. Или выберите в медиатеке уже отснятое видео или фото. Пользуясь жестами, вы можете зуммировать и панорамировать прямо во время съёмки, чтобы подчеркнуть драматичность или комичность момента.
Сказано – показано.
Функция «Живые заголовки» позволяет быстро создавать анимированные титры, превращая вашу речь в надписи. Просто начните говорить во время съёмки, и слова будут мгновенно появляться на экране. А затем коснитесь ролика, чтобы отредактировать текст, добавить знаки препинания или изменить стиль титров.
Добавьте красоты.
Вы можете оформить своё видео в стиле немого кино, добавить анимированные эмодзи или яркие стикеры с Микки Маусом и его друзьями, героями «Звёздных войн», «Истории игрушек» и другими персонажами. Полноэкранные постеры с анимированным фоном позволят вам рассказать историю более увлекательно. И финальный аккорд: к вашим услугам десятки музыкальных треков, которые автоматически подстраиваются к продолжительности вашего видео. Просто выберите подходящий по настроению.
Заходите в новый мир.
Приложение Clips становится ещё увлекательнее. С помощью функции «Сцены» и камеры TrueDepth вы можете снять себя на видео и поместить в совершенно другую среду — это может быть анимированный пейзаж, научная лаборатория и даже поле боя из мультфильма«Суперсемейка 2» от Disney/Pixar. Каждая сцена отрисована как круговая панорама, поэтому эффект вашего присутствия в ней будет абсолютным. А на большом дисплее нового iPad Pro видно ещё больше деталей — вы словно погружаетесь в волшебный мир.
И здесь, и там.
Теперь приложение Clips работает с iCloud, поэтому вы можете смотреть и редактировать свои проекты на любом устройстве. Снимите фото или видео на iPhone, а затем добавьте фильтры, стикеры и подписи с помощью iPad.
Отправьте с инновациями.
Приложение Clips распознаёт лица в ваших видеороликах и запоминает, кому вы чаще всего отправляете свои видео. Поэтому, когда вы захотите поделиться новым шедевром, эти люди будут предложены вам как возможные адресаты. Просто коснитесь нужного имени, чтобы отправить видео через Сообщения, или сразу опубликуйте его в соцсети.