Таблица на языке C

Можно ли реализовать такую таблицу на языке С? Первая строчка задается автоматически, № тоже, а далее необходимо, чтобы пользователь вводил необходимую информацию. Я пробовал делать с табуляцией \t но все тщетно. Вот собственно сам кусок кода:
#include #include #include #include struct library < char LastNAME[100]; char FirstNAME[100]; char MiddleNAME[100]; int BirthDate, BirthMonth, BirthYear; char Address[100]; int PhoneNumberMOBILE; int PhoneNumberWORK; >notebook[10]; void DataInitialization() //Инициализация данных < FILE* F; char fname[100]; int NumberOfEntries=0; printf("Укажите имя файла, в котором будет хранится база данных (как на примере: text.txt)\n->"); scanf_s("%s", fname, sizeof(fname)); while (getchar() != '\n'); if ((F = fopen(fname, "w+")) == NULL) < printf("Невозможно открыть для чтения файл \n"); return; >; printf("Сколько записей вы хотите сделать?\n -> "); scanf_s("%d", &NumberOfEntries); //ЗАМЕНИТЬ ПЕРЕМЕННУЮ printf("№ | Фамилия | Имя | Отчество | Дата Рождения | Адрес | моб.телефон | раб.телефон |\n"); /*while (1) /*>*/ > void ViewData() //Просмотр существующей базы данных < >void DataEdit() //Редактирование базы данных < >void AddData() //Дополнение базы данных новыми записями < >void DeleteData() //Удаление данных < >void SearchData() //Поиск в базе данных < >void SortData() //Сортировка данных по заданному полю < >int main() < setlocale(LC_ALL, "Russian"); int menu=1; while (menu != 0) < printf("Выберите, что вам нужно сделать\n" "0 ->Выход из программы\n" "1 -> Создание новой базы данных\n" "2 -> Просмотр существующей базы данных\n" "3 -> Редактирование базы данных\n" "4 -> Дополнение базы данных новыми записями\n" "5 -> Удаление записей из базы данных\n" "6 -> Поиск в базе данных\n" "7 -> Сортировка данных по заданному полю\n"); scanf_s("%d", &menu); if (menu > 7) printf("Пж выберите цифру из предложенного списка:\n\n"); switch (menu) < case 1: DataInitialization();//Инициализация данных break; case 2: ViewData(); //Просмотр существующей базы данных break; case 3: DataEdit(); //Редактирование базы данных break; case 4: AddData(); //Дополнение базы данных новыми записями break; case 5: DeleteData(); //Удаление данных break; case 6: SearchData(); //Поиск в базе данных break; case 7: SortData(); //Сортировка данных по заданному полю break; >> >``` Как сделать таблицу в Excel. Пошаговая инструкция

PDF шпаргалка с ТОП горячих клавиш в Excel Получить
Таблицы в Excel представляют собой ряд строк и столбцов со связанными данными, которыми вы управляете независимо друг от друга.
Работая в Excel с таблицами, вы сможете создавать отчеты, делать расчеты, строить графики и диаграммы, сортировать и фильтровать информацию.
Если ваша работа связана с обработкой данных, то навыки работы с таблицами в Эксель помогут вам сильно сэкономить время и повысить эффективность.
Как работать в Excel с таблицами. Пошаговая инструкция
Прежде чем работать с таблицами в Эксель, последуйте рекомендациям по организации данных:
- Данные должны быть организованы в строках и столбцах, причем каждая строка должна содержать информацию об одной записи, например о заказе;
- Первая строка таблицы должна содержать короткие, уникальные заголовки;
- Каждый столбец должен содержать один тип данных, таких как числа, валюта или текст;
- Каждая строка должна содержать данные для одной записи, например, заказа. Если применимо, укажите уникальный идентификатор для каждой строки, например номер заказа;
- В таблице не должно быть пустых строк и абсолютно пустых столбцов.
1. Выделите область ячеек для создания таблицы
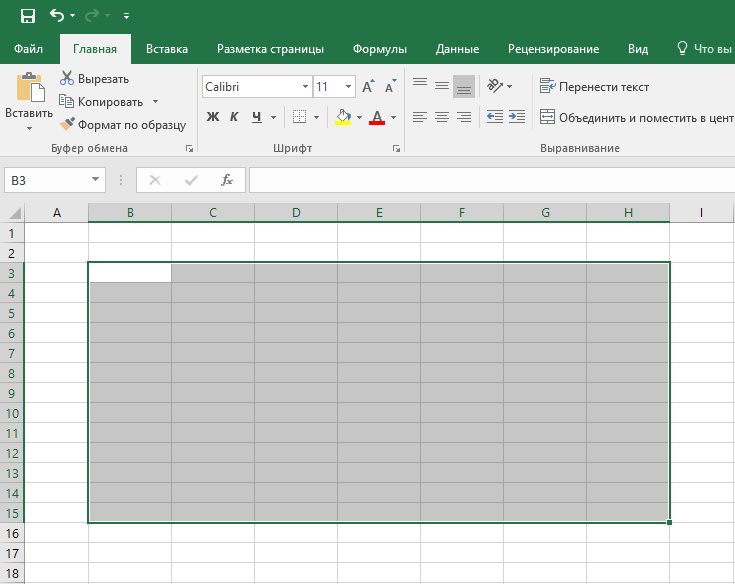
Выделите область ячеек, на месте которых вы хотите создать таблицу. Ячейки могут быть как пустыми, так и с информацией.
2. Нажмите кнопку «Таблица» на панели быстрого доступа
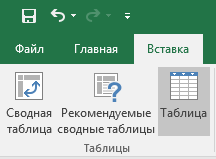
На вкладке «Вставка» нажмите кнопку «Таблица».
3. Выберите диапазон ячеек
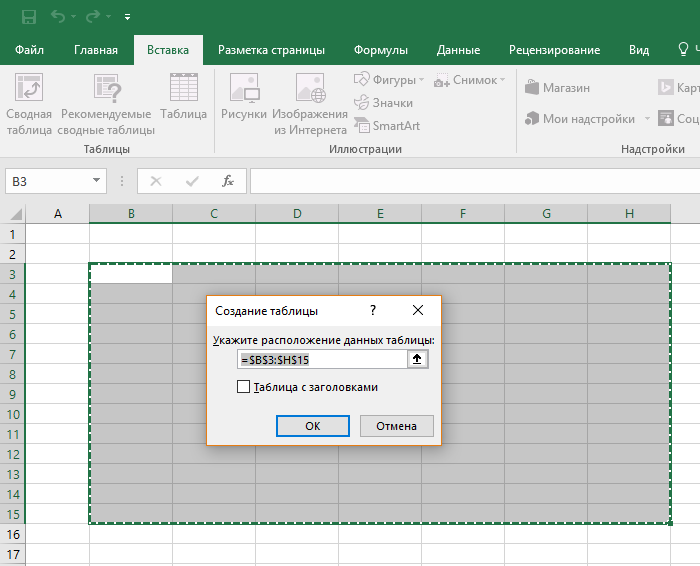
Во всплывающем вы можете скорректировать расположение данных, а также настроить отображение заголовков. Когда все готово, нажмите «ОК».
4. Таблица готова. Заполняйте данными!
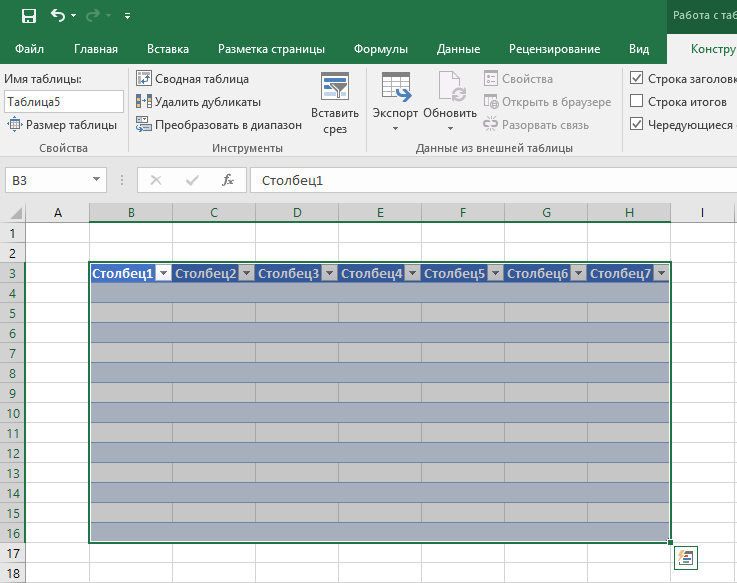
Поздравляю, ваша таблица готова к заполнению! Об основных возможностях в работе с умными таблицами вы узнаете ниже.
Видео урок: как создать простую таблицу в Excel
Форматирование таблицы в Excel
Для настройки формата таблицы в Экселе доступны предварительно настроенные стили. Все они находятся на вкладке «Конструктор» в разделе «Стили таблиц»:

Если 7-ми стилей вам мало для выбора, тогда, нажав на кнопку, в правом нижнем углу стилей таблиц, раскроются все доступные стили. В дополнении к предустановленным системой стилям, вы можете настроить свой формат.
Помимо цветовой гаммы, в меню «Конструктора» таблиц можно настроить:

- Отображение строки заголовков — включает и отключает заголовки в таблице;
- Строку итогов — включает и отключает строку с суммой значений в колонках;
- Чередующиеся строки — подсвечивает цветом чередующиеся строки;
- Первый столбец — выделяет «жирным» текст в первом столбце с данными;
- Последний столбец — выделяет «жирным» текст в последнем столбце;
- Чередующиеся столбцы — подсвечивает цветом чередующиеся столбцы;
- Кнопка фильтра — добавляет и убирает кнопки фильтра в заголовках столбцов.
Видео урок: как задать формат таблицы
Как добавить строку или столбец в таблице Excel
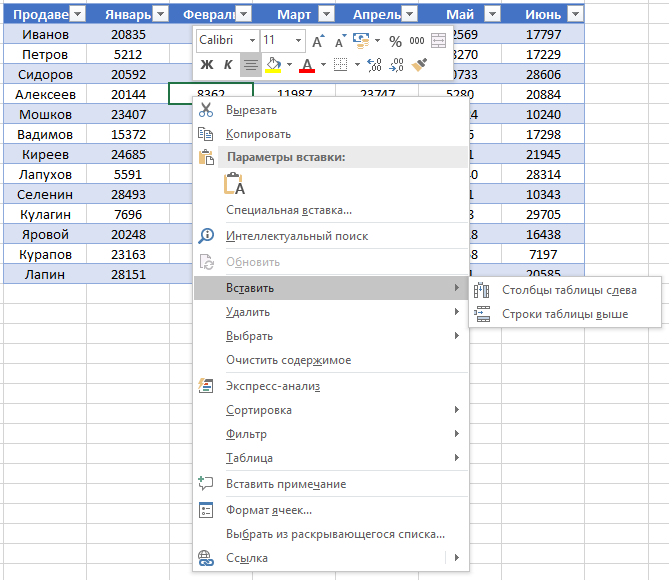
Даже внутри уже созданной таблицы вы можете добавлять строки или столбцы. Для этого кликните на любой ячейке правой клавишей мыши для вызова всплывающего окна:

- Выберите пункт «Вставить» и кликните левой клавишей мыши по «Столбцы таблицы слева» если хотите добавить столбец, или «Строки таблицы выше», если хотите вставить строку.
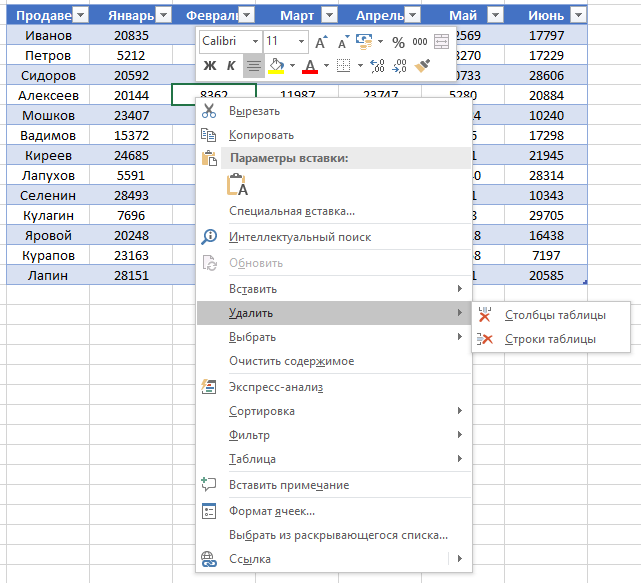
- Если вы хотите удалить строку или столбец в таблице, то спуститесь по списку в сплывающем окне до пункта «Удалить» и выберите «Столбцы таблицы», если хотите удалить столбец или «Строки таблицы», если хотите удалить строку.
Как отсортировать таблицу в Excel
Для сортировки информации при работе с таблицей, нажмите справа от заголовка колонки «стрелочку», после чего появится всплывающее окно:

В окне выберите по какому принципу отсортировать данные: «по возрастанию», «по убыванию», «по цвету», «числовым фильтрам».
Видео урок как отсортировать таблицу
Как отфильтровать данные в таблице Excel
Для фильтрации информации в таблице нажмите справа от заголовка колонки «стрелочку», после чего появится всплывающее окно:

- «Текстовый фильтр» отображается когда среди данных колонки есть текстовые значения;
- «Фильтр по цвету» так же как и текстовый, доступен когда в таблице есть ячейки, окрашенные в отличающийся от стандартного оформления цвета;
- «Числовой фильтр» позволяет отобрать данные по параметрам: «Равно…», «Не равно…», «Больше…», «Больше или равно…», «Меньше…», «Меньше или равно…», «Между…», «Первые 10…», «Выше среднего», «Ниже среднего», а также настроить собственный фильтр.
- Во всплывающем окне, под «Поиском» отображаются все данные, по которым можно произвести фильтрацию, а также одним нажатием выделить все значения или выбрать только пустые ячейки.
Если вы хотите отменить все созданные настройки фильтрации, снова откройте всплывающее окно над нужной колонкой и нажмите «Удалить фильтр из столбца». После этого таблица вернется в исходный вид.
Как посчитать сумму в таблице Excel
Для того чтобы посчитать сумму колонки в конце таблицы, нажмите правой клавишей мыши на любой ячейке и вызовите всплывающее окно:

В списке окна выберите пункт «Таблица» => «Строка итогов»:

Внизу таблица появится промежуточный итог. Нажмите левой клавишей мыши на ячейке с суммой.

В выпадающем меню выберите принцип промежуточного итога: это может быть сумма значений колонки, «среднее», «количество», «количество чисел», «максимум», «минимум» и т.д.
Видео урок: как посчитать сумму в таблице Excel
Как в Excel закрепить шапку таблицы
Таблицы, с которыми приходится работать, зачастую крупные и содержат в себе десятки строк. Прокручивая таблицу «вниз» сложно ориентироваться в данных, если не видно заголовков столбцов. В Эксель есть возможность закрепить шапку в таблице таким образом, что при прокрутке данных вам будут видны заголовки колонок.
Для того чтобы закрепить заголовки сделайте следующее:
- Перейдите на вкладку «Вид» в панели инструментов и выберите пункт «Закрепить области»:

- Выберите пункт «Закрепить верхнюю строку»:

- Теперь, прокручивая таблицу, вы не потеряете заголовки и сможете легко сориентироваться где какие данные находятся:
Видео урок: как закрепить шапку таблицы:
Как перевернуть таблицу в Excel
Представим, что у нас есть готовая таблица с данными продаж по менеджерам:

На таблице сверху в строках указаны фамилии продавцов, в колонках месяцы. Для того чтобы перевернуть таблицу и разместить месяцы в строках, а фамилии продавцов нужно:
- Выделить таблицу целиком (зажав левую клавишу мыши выделить все ячейки таблицы) и скопировать данные (CTRL+C):

- Переместить курсор мыши на свободную ячейку и нажать правую клавишу мыши. В открывшемся меню выбрать «Специальная вставка» и нажать на этом пункте левой клавишей мыши:

- В открывшемся окне в разделе «Вставить» выбрать «значения» и поставить галочку в пункте «транспонировать»:

- Готово! Месяцы теперь размещены по строкам, а фамилии продавцов по колонкам. Все что остается сделать — это преобразовать полученные данные в таблицу.

Видео урок как перевернуть таблицу:
В этой статье вы ознакомились с принципами работы в Excel с таблицами, а также основными подходами в их создании. Пишите свои вопросы в комментарии!
Хеш-таблица в C/C++: полная реализация
Хеш-таблица в C/C++ (ассоциативный массив) — это структура данных, которая сопоставляет ключи со значениями и использует хеш-функцию для вычисления индексов ключа.
Индекс хеш-таблицы позволяет нам сохранить значение в соответствующем месте.
Если два разных ключа получают один и тот же индекс, для учета подобных коллизий мы должны использовать другие структуры данных (сегменты).
Главное преимущество использования хеш-таблицы – очень короткое время доступа. Конфликты иногда могут возникать, но шансы практически равны нулю, если выбрать очень хорошую хэш-функцию.
Итак, в среднем временная сложность представляет собой постоянное время доступа O(1) – это называется амортизационной временной сложностью.
C++ STL (стандартная библиотека шаблонов) использует структуру данных std::unordered_map(), которая реализует все эти функции хэш-таблицы.
Однако уметь строить хеш-таблицы с нуля – навык важный и полезный, и именно этим мы займемся в данном мануале.
Давайте разберемся подробнее в деталях реализации таблиц. Любая реализация хеш-таблицы состоит из следующих трех компонентов:
- Хорошая хеш-функция для сопоставления ключей со значениями.
- Структура данных хеш-таблицы, поддерживающая операции вставки, поиска и удаления.
- Структура данных для учета конфликтов ключей
Выбор хэш-функции
Первый шаг — выбрать достаточно хорошую хеш-функцию с низкой вероятностью возникновения коллизии.
Но для иллюстрации в этом мануале мы сделаем все наоборот – выберем плохую функцию и посмотрим, что получится.
В этой статье мы будем работать только со строками (или массивами символов).
Мы будем использовать очень простую хеш-функцию, которая просто суммирует значения ASCII строки. Эта функция позволит нам продемонстрировать, как обрабатывать коллизии.
#define CAPACITY 50000 // Size of the Hash Table unsigned long hash_function(char* str)
Вы можете проверить эту функцию для разных строк и увидеть, возникают коллизии или нет. Например, строки «Hel» и «Cau» будут конфликтовать, так как они имеют одинаковое значение ASCII.
Примечание: Таблица должна вернуть число в пределах своей емкости. В противном случае мы можем получить доступ к несвязанной области памяти, что приведет к ошибке.
Определение структуры данных хеш-таблицы
Хеш-таблица — это массив элементов, которые сами по себе являются парой .
Давайте теперь определим структуру нашего элемента.
typedef struct Ht_item Ht_item; // Define the Hash Table Item here struct Ht_item < char* key; char* value; >;
Теперь хеш-таблица имеет массив указателей, которые сами ведут на Ht_item, так что получается двойной указатель.
Помимо этого, мы также будем отслеживать количество элементов в хеш-таблице с помощью count и сохранять размер таблицы в size.
typedef struct HashTable HashTable; // Define the Hash Table here struct HashTable < // Contains an array of pointers // to items Ht_item** items; int size; int count; >;
Создание хеш-таблицы и ее элементов
Чтобы создать в памяти новую хеш-таблицу и ее элементы, нам нужны функции.
Сначала давайте создадим элементы. Это очень просто делается: нам нужно лишь выделить память для ключа и значения и вернуть указатель на элемент.
Ht_item* create_item(char* key, char* value) < // Creates a pointer to a new hash table item Ht_item* item = (Ht_item*) malloc (sizeof(Ht_item)); item->key = (char*) malloc (strlen(key) + 1); item->value = (char*) malloc (strlen(value) + 1); strcpy(item->key, key); strcpy(item->value, value); return item; >
Теперь давайте напишем код для создания таблицы. Этот код выделяет память для структуры-оболочки HashTable и устанавливает для всех ее элементов значение NULL (поскольку они не используются).
HashTable* create_table(int size) < // Creates a new HashTable HashTable* table = (HashTable*) malloc (sizeof(HashTable)); table->size = size; table->count = 0; table->items = (Ht_item**) calloc (table->size, sizeof(Ht_item*)); for (int i=0; isize; i++) table->items[i] = NULL; return table; >
Мы почти закончили с этой частью. Как программист C/C++, вы обязаны освобождать выделенную память с помощью malloc(), calloc().
Давайте же напишем функции, которые освобождают элемент и всю таблицу.
void free_item(Ht_item* item) < // Frees an item free(item->key); free(item->value); free(item); > void free_table(HashTable* table) < // Frees the table for (int i=0; isize; i++) < Ht_item* item = table->items[i]; if (item != NULL) free_item(item); > free(table->items); free(table); >
Итак, мы завершили работу над нашей функциональной хеш-таблицей. Давайте теперь начнем писать методы insert(), search() и delete().
Вставка в хеш-таблицу
Сейчас мы создадим функцию ht_insert(), которая выполнит задачу вставки за нас.
Она принимает в качестве параметров указатель HashTable, ключ и значение.
void ht_insert(HashTable* table, char* key, char* value);
Далее нужно выполнить определенные шаги, связанные с функцией вставки.
Создать элемент на основе пары .
- Вычислить индекс на основе хеш-функции
- Путем сравнения ключа проверить, занят ли данный индекс или еще нет.
- Если он не занят, мы можем напрямую вставить его в index
- В противном случае возникает коллизия, и нам нужно ее обработать
О том, как обрабатывать коллизии, мы поговорим немного позже, после того, как создадим исходную модель.
Первый шаг прост. Мы напрямую вызываем create_item(key, value).
int index = hash_function(key);
Второй и третий шаги для получения индекса используют hash_function(key). Если мы вставляем ключ в первый раз, элемент должен быть NULL. В противном случае либо точная пара «ключ: значение» уже существует, либо это коллизия.
В этом случае мы определяем другую функцию handle_collision(), которая, как следует из названия, обработает эту потенциальную коллизию.
// Create the item Ht_item* item = create_item(key, value); // Compute the index int index = hash_function(key); Ht_item* current_item = table->items[index]; if (current_item == NULL) < // Key does not exist. if (table->count == table->size) < // Hash Table Full printf("Insert Error: Hash Table is full\n"); free_item(item); return; >// Insert directly table->items[index] = item; table->count++; >
Давайте рассмотрим первый сценарий, где пара «ключ: значение» уже существует (то есть такой же элемент уже был вставлен в таблицу ранее). В этом случае мы всего лишь должны обновить значение элемента, просто присвоить ему новое значение.
if (current_item == NULL) < . . >else < // Scenario 1: We only need to update value if (strcmp(current_item->key, key) == 0) < strcpy(table->items[index]->value, value); return; > else < // Scenario 2: Collision // We will handle case this a bit later handle_collision(table, item); return; >>
Итак, функция вставки (без коллизий) теперь выглядит примерно так:
void handle_collision(HashTable* table, Ht_item* item) < >void ht_insert(HashTable* table, char* key, char* value) < // Create the item Ht_item* item = create_item(key, value); Ht_item* current_item = table->items[index]; if (current_item == NULL) < // Key does not exist. if (table->count == table->size) < // Hash Table Full printf("Insert Error: Hash Table is full\n"); return; >// Insert directly table->items[index] = item; table->count++; > else < // Scenario 1: We only need to update value if (strcmp(current_item->key, key) == 0) < strcpy(table->items[index]->value, value); return; > else < // Scenario 2: Collision // We will handle case this a bit later handle_collision(table, item); return; >> >
Поиск элементов в хеш-таблице
Если мы хотим проверить правильность вставки, мы должны определить функцию поиска, которая проверяет, существует ключ или нет, и возвращает соответствующее значение, если он существует.
char* ht_search(HastTable* table, char* key);
Логика очень проста. Функция просто переходит к элементам, котороые не являются NULL, и сравнивает ключ. В противном случае она вернет NULL.
char* ht_search(HashTable* table, char* key) < // Searches the key in the hashtable // and returns NULL if it doesn't exist int index = hash_function(key); Ht_item* item = table->items[index]; // Ensure that we move to a non NULL item if (item != NULL) < if (strcmp(item->key, key) == 0) return item->value; > return NULL; >
Тестирование базовой модели
Давайте проверим, правильно ли работает то, что мы муже написали. Для этого мы используем программу-драйвер main().
Чтобы проиллюстрировать, как все работает, добавим еще одну функцию print_table(), которая выводит хеш-таблицу.
#include #include #include #define CAPACITY 50000 // Size of the Hash Table unsigned long hash_function(char* str) < unsigned long i = 0; for (int j=0; str[j]; j++) i += str[j]; return i % CAPACITY; >typedef struct Ht_item Ht_item; // Define the Hash Table Item here struct Ht_item < char* key; char* value; >; typedef struct HashTable HashTable; // Define the Hash Table here struct HashTable < // Contains an array of pointers // to items Ht_item** items; int size; int count; >; Ht_item* create_item(char* key, char* value) < // Creates a pointer to a new hash table item Ht_item* item = (Ht_item*) malloc (sizeof(Ht_item)); item->key = (char*) malloc (strlen(key) + 1); item->value = (char*) malloc (strlen(value) + 1); strcpy(item->key, key); strcpy(item->value, value); return item; > HashTable* create_table(int size) < // Creates a new HashTable HashTable* table = (HashTable*) malloc (sizeof(HashTable)); table->size = size; table->count = 0; table->items = (Ht_item**) calloc (table->size, sizeof(Ht_item*)); for (int i=0; isize; i++) table->items[i] = NULL; return table; > void free_item(Ht_item* item) < // Frees an item free(item->key); free(item->value); free(item); > void free_table(HashTable* table) < // Frees the table for (int i=0; isize; i++) < Ht_item* item = table->items[i]; if (item != NULL) free_item(item); > free(table->items); free(table); > void handle_collision(HashTable* table, unsigned long index, Ht_item* item) < >void ht_insert(HashTable* table, char* key, char* value) < // Create the item Ht_item* item = create_item(key, value); // Compute the index unsigned long index = hash_function(key); Ht_item* current_item = table->items[index]; if (current_item == NULL) < // Key does not exist. if (table->count == table->size) < // Hash Table Full printf("Insert Error: Hash Table is full\n"); // Remove the create item free_item(item); return; >// Insert directly table->items[index] = item; table->count++; > else < // Scenario 1: We only need to update value if (strcmp(current_item->key, key) == 0) < strcpy(table->items[index]->value, value); return; > else < // Scenario 2: Collision // We will handle case this a bit later handle_collision(table, index, item); return; >> > char* ht_search(HashTable* table, char* key) < // Searches the key in the hashtable // and returns NULL if it doesn't exist int index = hash_function(key); Ht_item* item = table->items[index]; // Ensure that we move to a non NULL item if (item != NULL) < if (strcmp(item->key, key) == 0) return item->value; > return NULL; > void print_search(HashTable* table, char* key) < char* val; if ((val = ht_search(table, key)) == NULL) < printf("Key:%s does not exist\n", key); return; >else < printf("Key:%s, Value:%s\n", key, val); >> void print_table(HashTable* table) < printf("\nHash Table\n-------------------\n"); for (int i=0; isize; i++) < if (table->items[i]) < printf("Index:%d, Key:%s, Value:%s\n", i, table->items[i]->key, table->items[i]->value); > > printf(«——————-\n\n»); > int main()
В результате мы получим:
Key:1, Value:First address Key:2, Value:Second address Key:3 does not exist Hash Table ------------------- Index:49, Key:1, Value:First address Index:50, Key:2, Value:Second address -------------------
Замечательно! Кажется, все работает так, как мы и ожидали. Теперь давайте перейдем к обработке коллизий.
Разрешение коллизий
Существуют различные способы разрешения коллизии. Мы рассмотрим метод под названием «метод цепочек», целью которого является создание независимых цепочек для всех элементов с одинаковым хэш-индексом.
Мы создадим эти цепочки с помощью связных списков.
Всякий раз, когда возникает коллизия, мы добавляем дополнительные элементы, которые конфликтуют с одним и тем же индексом в списке переполненных бакетов. Таким образом, нам не придется удалять какие-либо существующие записи из таблицы.
Поскольку связные списки имеют временную сложность O(n) для вставки, поиска и удаления, при возникновении коллизии время доступа в наихудшем случае тоже будет O(n). Этот метод хорошо подходит для работы с таблицами небольшой емкости.
Давайте же приступим к реализации связанного списка.
typedef struct LinkedList LinkedList; // Define the Linkedlist here struct LinkedList < Ht_item* item; LinkedList* next; >; LinkedList* allocate_list () < // Allocates memory for a Linkedlist pointer LinkedList* list = (LinkedList*) malloc (sizeof(LinkedList)); return list; >LinkedList* linkedlist_insert(LinkedList* list, Ht_item* item) < // Inserts the item onto the Linked List if (!list) < LinkedList* head = allocate_list(); head->item = item; head->next = NULL; list = head; return list; > else if (list->next == NULL) < LinkedList* node = allocate_list(); node->item = item; node->next = NULL; list->next = node; return list; > LinkedList* temp = list; while (temp->next->next) < temp = temp->next; > LinkedList* node = allocate_list(); node->item = item; node->next = NULL; temp->next = node; return list; Ht_item* linkedlist_remove(LinkedList* list) < // Removes the head from the linked list // and returns the item of the popped element if (!list) return NULL; if (!list->next) return NULL; LinkedList* node = list->next; LinkedList* temp = list; temp->next = NULL; list = node; Ht_item* it = NULL; memcpy(temp->item, it, sizeof(Ht_item)); free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); return it; > void free_linkedlist(LinkedList* list) < LinkedList* temp = list; while (list) < temp = list; list = list->next; free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); > >
Теперь нужно добавить эти списки переполненных бакетов в хеш-таблицу. У каждого элемента должна быть одна такая цепочка, поэтому для всей таблицы мы добавим массив указателей LinkedList.
typedef struct HashTable HashTable; // Define the Hash Table here struct HashTable < // Contains an array of pointers // to items Ht_item** items; LinkedList** overflow_buckets; int size; int count; >;
Теперь, когда мы определили overflow_buckets, давайте добавим функции для их создания и удаления. Их также необходимо учитывать в старых функциях create_table() и free_table().
LinkedList** create_overflow_buckets(HashTable* table) < // Create the overflow buckets; an array of linkedlists LinkedList** buckets = (LinkedList**) calloc (table->size, sizeof(LinkedList*)); for (int i=0; isize; i++) buckets[i] = NULL; return buckets; > void free_overflow_buckets(HashTable* table) < // Free all the overflow bucket lists LinkedList** buckets = table->overflow_buckets; for (int i=0; isize; i++) free_linkedlist(buckets[i]); free(buckets); > HashTable* create_table(int size) < // Creates a new HashTable HashTable* table = (HashTable*) malloc (sizeof(HashTable)); table->size = size; table->count = 0; table->items = (Ht_item**) calloc (table->size, sizeof(Ht_item*)); for (int i=0; isize; i++) table->items[i] = NULL; table->overflow_buckets = create_overflow_buckets(table); return table; > void free_table(HashTable* table) < // Frees the table for (int i=0; isize; i++) < Ht_item* item = table->items[i]; if (item != NULL) free_item(item); > // Free the overflow bucket linked linkedlist and it's items free_overflow_buckets(table); free(table->items); free(table); >
Теперь перейдем к функции handle_collision().
Здесь есть два сценария. Если список элемента не существует, нам нужно создать такой список и добавить в него элемент.
В противном случае мы можем просто вставить элемент в список.
void handle_collision(HashTable* table, unsigned long index, Ht_item* item) < LinkedList* head = table->overflow_buckets[index]; if (head == NULL) < // We need to create the list head = allocate_list(); head->item = item; table->overflow_buckets[index] = head; return; > else < // Insert to the list table->overflow_buckets[index] = linkedlist_insert(head, item); return; > >
Итак, мы закончили со вставкой, и теперь нам также нужно обновить функцию поиска, так как нам, возможно, потребуется также просмотреть переполненные бакеты.
char* ht_search(HashTable* table, char* key) < // Searches the key in the hashtable // and returns NULL if it doesn't exist int index = hash_function(key); Ht_item* item = table->items[index]; LinkedList* head = table->overflow_buckets[index]; // Ensure that we move to items which are not NULL while (item != NULL) < if (strcmp(item->key, key) == 0) return item->value; if (head == NULL) return NULL; item = head->item; head = head->next; > return NULL;
Итак, мы учли коллизии в функциях insert() и search(). На данный момент наш код выглядит так:
#include #include #include #define CAPACITY 50000 // Size of the Hash Table unsigned long hash_function(char* str) < unsigned long i = 0; for (int j=0; str[j]; j++) i += str[j]; return i % CAPACITY; >typedef struct Ht_item Ht_item; // Define the Hash Table Item here struct Ht_item < char* key; char* value; >; typedef struct LinkedList LinkedList; // Define the Linkedlist here struct LinkedList < Ht_item* item; LinkedList* next; >; typedef struct HashTable HashTable; // Define the Hash Table here struct HashTable < // Contains an array of pointers // to items Ht_item** items; LinkedList** overflow_buckets; int size; int count; >; static LinkedList* allocate_list () < // Allocates memory for a Linkedlist pointer LinkedList* list = (LinkedList*) malloc (sizeof(LinkedList)); return list; >static LinkedList* linkedlist_insert(LinkedList* list, Ht_item* item) < // Inserts the item onto the Linked List if (!list) < LinkedList* head = allocate_list(); head->item = item; head->next = NULL; list = head; return list; > else if (list->next == NULL) < LinkedList* node = allocate_list(); node->item = item; node->next = NULL; list->next = node; return list; > LinkedList* temp = list; while (temp->next->next) < temp = temp->next; > LinkedList* node = allocate_list(); node->item = item; node->next = NULL; temp->next = node; return list; > static Ht_item* linkedlist_remove(LinkedList* list) < // Removes the head from the linked list // and returns the item of the popped element if (!list) return NULL; if (!list->next) return NULL; LinkedList* node = list->next; LinkedList* temp = list; temp->next = NULL; list = node; Ht_item* it = NULL; memcpy(temp->item, it, sizeof(Ht_item)); free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); return it; > static void free_linkedlist(LinkedList* list) < LinkedList* temp = list; while (list) < temp = list; list = list->next; free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); > > static LinkedList** create_overflow_buckets(HashTable* table) < // Create the overflow buckets; an array of linkedlists LinkedList** buckets = (LinkedList**) calloc (table->size, sizeof(LinkedList*)); for (int i=0; isize; i++) buckets[i] = NULL; return buckets; > static void free_overflow_buckets(HashTable* table) < // Free all the overflow bucket lists LinkedList** buckets = table->overflow_buckets; for (int i=0; isize; i++) free_linkedlist(buckets[i]); free(buckets); > Ht_item* create_item(char* key, char* value) < // Creates a pointer to a new hash table item Ht_item* item = (Ht_item*) malloc (sizeof(Ht_item)); item->key = (char*) malloc (strlen(key) + 1); item->value = (char*) malloc (strlen(value) + 1); strcpy(item->key, key); strcpy(item->value, value); return item; > HashTable* create_table(int size) < // Creates a new HashTable HashTable* table = (HashTable*) malloc (sizeof(HashTable)); table->size = size; table->count = 0; table->items = (Ht_item**) calloc (table->size, sizeof(Ht_item*)); for (int i=0; isize; i++) table->items[i] = NULL; table->overflow_buckets = create_overflow_buckets(table); return table; > void free_item(Ht_item* item) < // Frees an item free(item->key); free(item->value); free(item); > void free_table(HashTable* table) < // Frees the table for (int i=0; isize; i++) < Ht_item* item = table->items[i]; if (item != NULL) free_item(item); > free_overflow_buckets(table); free(table->items); free(table); > void handle_collision(HashTable* table, unsigned long index, Ht_item* item) < LinkedList* head = table->overflow_buckets[index]; if (head == NULL) < // We need to create the list head = allocate_list(); head->item = item; table->overflow_buckets[index] = head; return; > else < // Insert to the list table->overflow_buckets[index] = linkedlist_insert(head, item); return; > > void ht_insert(HashTable* table, char* key, char* value) < // Create the item Ht_item* item = create_item(key, value); // Compute the index unsigned long index = hash_function(key); Ht_item* current_item = table->items[index]; if (current_item == NULL) < // Key does not exist. if (table->count == table->size) < // Hash Table Full printf("Insert Error: Hash Table is full\n"); // Remove the create item free_item(item); return; >// Insert directly table->items[index] = item; table->count++; > else < // Scenario 1: We only need to update value if (strcmp(current_item->key, key) == 0) < strcpy(table->items[index]->value, value); return; > else < // Scenario 2: Collision handle_collision(table, index, item); return; >> > char* ht_search(HashTable* table, char* key) < // Searches the key in the hashtable // and returns NULL if it doesn't exist int index = hash_function(key); Ht_item* item = table->items[index]; LinkedList* head = table->overflow_buckets[index]; // Ensure that we move to items which are not NULL while (item != NULL) < if (strcmp(item->key, key) == 0) return item->value; if (head == NULL) return NULL; item = head->item; head = head->next; > return NULL; > void print_search(HashTable* table, char* key) < char* val; if ((val = ht_search(table, key)) == NULL) < printf("%s does not exist\n", key); return; >else < printf("Key:%s, Value:%s\n", key, val); >> void print_table(HashTable* table) < printf("\n-------------------\n"); for (int i=0; isize; i++) < if (table->items[i]) < printf("Index:%d, Key:%s, Value:%s", i, table->items[i]->key, table->items[i]->value); if (table->overflow_buckets[i]) < printf(" =>Overflow Bucket => «); LinkedList* head = table->overflow_buckets[i]; while (head) < printf("Key:%s, Value:%s ", head->item->key, head->item->value); head = head->next; > > printf(«\n»); > > printf(«——————-\n»); > int main()
Удаление из хеш-таблицы
Давайте взглянем на функцию удаления данных из таблицы:
void ht_delete(HashTable* table, char* key);
Эта функция работает аналогично вставке. Нам нужно:
- Вычислить хеш-индекс и получить элемент.
- Если это NULL, нам ничего не нужно делать
- В противном случае, если для этого индекса нет цепочки коллизий, после сравнения ключей нужно просто удалить элемент из таблицы.
- Если цепочка коллизий существует, мы должны удалить этот элемент и соответствующим образом сдвинуть данные.
Мы не будем перечислять здесь слишком много подробностей, так как эта процедура включает только обновление элементов заголовка и освобождение памяти. Предлагаем вам попытаться реализовать это самостоятельно.
Предоставляем вам рабочую версию для сравнения.
void ht_delete(HashTable* table, char* key) < // Deletes an item from the table int index = hash_function(key); Ht_item* item = table->items[index]; LinkedList* head = table->overflow_buckets[index]; if (item == NULL) < // Does not exist. Return return; >else < if (head == NULL && strcmp(item->key, key) == 0) < // No collision chain. Remove the item // and set table index to NULL table->items[index] = NULL; free_item(item); table->count--; return; > else if (head != NULL) < // Collision Chain exists if (strcmp(item->key, key) == 0) < // Remove this item and set the head of the list // as the new item free_item(item); LinkedList* node = head; head = head->next; node->next = NULL; table->items[index] = create_item(node->item->key, node->item->value); free_linkedlist(node); table->overflow_buckets[index] = head; return; > LinkedList* curr = head; LinkedList* prev = NULL; while (curr) < if (strcmp(curr->item->key, key) == 0) < if (prev == NULL) < // First element of the chain. Remove the chain free_linkedlist(head); table->overflow_buckets[index] = NULL; return; > else < // This is somewhere in the chain prev->next = curr->next; curr->next = NULL; free_linkedlist(curr); table->overflow_buckets[index] = head; return; > > curr = curr->next; prev = curr; > > > >
Полный код
Наконец, мы можем посмотреть на полный код программы хеш-таблицы.
#include #include #include #define CAPACITY 50000 // Size of the Hash Table unsigned long hash_function(char* str) < unsigned long i = 0; for (int j=0; str[j]; j++) i += str[j]; return i % CAPACITY; >typedef struct Ht_item Ht_item; // Define the Hash Table Item here struct Ht_item < char* key; char* value; >; typedef struct LinkedList LinkedList; // Define the Linkedlist here struct LinkedList < Ht_item* item; LinkedList* next; >; typedef struct HashTable HashTable; // Define the Hash Table here struct HashTable < // Contains an array of pointers // to items Ht_item** items; LinkedList** overflow_buckets; int size; int count; >; static LinkedList* allocate_list () < // Allocates memory for a Linkedlist pointer LinkedList* list = (LinkedList*) malloc (sizeof(LinkedList)); return list; >static LinkedList* linkedlist_insert(LinkedList* list, Ht_item* item) < // Inserts the item onto the Linked List if (!list) < LinkedList* head = allocate_list(); head->item = item; head->next = NULL; list = head; return list; > else if (list->next == NULL) < LinkedList* node = allocate_list(); node->item = item; node->next = NULL; list->next = node; return list; > LinkedList* temp = list; while (temp->next->next) < temp = temp->next; > LinkedList* node = allocate_list(); node->item = item; node->next = NULL; temp->next = node; return list; > static Ht_item* linkedlist_remove(LinkedList* list) < // Removes the head from the linked list // and returns the item of the popped element if (!list) return NULL; if (!list->next) return NULL; LinkedList* node = list->next; LinkedList* temp = list; temp->next = NULL; list = node; Ht_item* it = NULL; memcpy(temp->item, it, sizeof(Ht_item)); free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); return it; > static void free_linkedlist(LinkedList* list) < LinkedList* temp = list; while (list) < temp = list; list = list->next; free(temp->item->key); free(temp->item->value); free(temp->item); free(temp); > > static LinkedList** create_overflow_buckets(HashTable* table) < // Create the overflow buckets; an array of linkedlists LinkedList** buckets = (LinkedList**) calloc (table->size, sizeof(LinkedList*)); for (int i=0; isize; i++) buckets[i] = NULL; return buckets; > static void free_overflow_buckets(HashTable* table) < // Free all the overflow bucket lists LinkedList** buckets = table->overflow_buckets; for (int i=0; isize; i++) free_linkedlist(buckets[i]); free(buckets); > Ht_item* create_item(char* key, char* value) < // Creates a pointer to a new hash table item Ht_item* item = (Ht_item*) malloc (sizeof(Ht_item)); item->key = (char*) malloc (strlen(key) + 1); item->value = (char*) malloc (strlen(value) + 1); strcpy(item->key, key); strcpy(item->value, value); return item; > HashTable* create_table(int size) < // Creates a new HashTable HashTable* table = (HashTable*) malloc (sizeof(HashTable)); table->size = size; table->count = 0; table->items = (Ht_item**) calloc (table->size, sizeof(Ht_item*)); for (int i=0; isize; i++) table->items[i] = NULL; table->overflow_buckets = create_overflow_buckets(table); return table; > void free_item(Ht_item* item) < // Frees an item free(item->key); free(item->value); free(item); > void free_table(HashTable* table) < // Frees the table for (int i=0; isize; i++) < Ht_item* item = table->items[i]; if (item != NULL) free_item(item); > free_overflow_buckets(table); free(table->items); free(table); > void handle_collision(HashTable* table, unsigned long index, Ht_item* item) < LinkedList* head = table->overflow_buckets[index]; if (head == NULL) < // We need to create the list head = allocate_list(); head->item = item; table->overflow_buckets[index] = head; return; > else < // Insert to the list table->overflow_buckets[index] = linkedlist_insert(head, item); return; > > void ht_insert(HashTable* table, char* key, char* value) < // Create the item Ht_item* item = create_item(key, value); // Compute the index unsigned long index = hash_function(key); Ht_item* current_item = table->items[index]; if (current_item == NULL) < // Key does not exist. if (table->count == table->size) < // Hash Table Full printf("Insert Error: Hash Table is full\n"); // Remove the create item free_item(item); return; >// Insert directly table->items[index] = item; table->count++; > else < // Scenario 1: We only need to update value if (strcmp(current_item->key, key) == 0) < strcpy(table->items[index]->value, value); return; > else < // Scenario 2: Collision handle_collision(table, index, item); return; >> > char* ht_search(HashTable* table, char* key) < // Searches the key in the hashtable // and returns NULL if it doesn't exist int index = hash_function(key); Ht_item* item = table->items[index]; LinkedList* head = table->overflow_buckets[index]; // Ensure that we move to items which are not NULL while (item != NULL) < if (strcmp(item->key, key) == 0) return item->value; if (head == NULL) return NULL; item = head->item; head = head->next; > return NULL; > void ht_delete(HashTable* table, char* key) < // Deletes an item from the table int index = hash_function(key); Ht_item* item = table->items[index]; LinkedList* head = table->overflow_buckets[index]; if (item == NULL) < // Does not exist. Return return; >else < if (head == NULL && strcmp(item->key, key) == 0) < // No collision chain. Remove the item // and set table index to NULL table->items[index] = NULL; free_item(item); table->count--; return; > else if (head != NULL) < // Collision Chain exists if (strcmp(item->key, key) == 0) < // Remove this item and set the head of the list // as the new item free_item(item); LinkedList* node = head; head = head->next; node->next = NULL; table->items[index] = create_item(node->item->key, node->item->value); free_linkedlist(node); table->overflow_buckets[index] = head; return; > LinkedList* curr = head; LinkedList* prev = NULL; while (curr) < if (strcmp(curr->item->key, key) == 0) < if (prev == NULL) < // First element of the chain. Remove the chain free_linkedlist(head); table->overflow_buckets[index] = NULL; return; > else < // This is somewhere in the chain prev->next = curr->next; curr->next = NULL; free_linkedlist(curr); table->overflow_buckets[index] = head; return; > > curr = curr->next; prev = curr; > > > > void print_search(HashTable* table, char* key) < char* val; if ((val = ht_search(table, key)) == NULL) < printf("%s does not exist\n", key); return; >else < printf("Key:%s, Value:%s\n", key, val); >> void print_table(HashTable* table) < printf("\n-------------------\n"); for (int i=0; isize; i++) < if (table->items[i]) < printf("Index:%d, Key:%s, Value:%s", i, table->items[i]->key, table->items[i]->value); if (table->overflow_buckets[i]) < printf(" =>Overflow Bucket => "); LinkedList* head = table->overflow_buckets[i]; while (head) < printf("Key:%s, Value:%s ", head->item->key, head->item->value); head = head->next; > > printf("\n"); > > printf("-------------------\n"); > int main() < HashTable* ht = create_table(CAPACITY); ht_insert(ht, "1", "First address"); ht_insert(ht, "2", "Second address"); ht_insert(ht, "Hel", "Third address"); ht_insert(ht, "Cau", "Fourth address"); print_search(ht, "1"); print_search(ht, "2"); print_search(ht, "3"); print_search(ht, "Hel"); print_search(ht, "Cau"); // Collision! print_table(ht); ht_delete(ht, "1"); ht_delete(ht, "Cau"); print_table(ht); free_table(ht); return 0; >Результат выглядит так: Key:1, Value:First address Key:2, Value:Second address 3 does not exist Key:Hel, Value:Third address Key:Cau, Value:Fourth address ------------------- Index:49, Key:1, Value:First address Index:50, Key:2, Value:Second address Index:281, Key:Hel, Value:Third address => Overflow Bucket => Key:Cau, Value:Fourth address ------------------- ------------------- Index:50, Key:2, Value:Second address Index:281, Key:Hel, Value:Third address -------------------
Заключение
Надеемся, вы поняли, как можно реализовать хеш-таблицу с нуля на C/C++. Возможно, у вас получилось реализовать ее самостоятельно.
Советуем вам также попробовать на примере полученной таблицы использовать другие алгоритмы обработки коллизий и другие хеш-функции и проверить их производительность.
Скачать код, который мы рассмотрели в этом руководстве, можно на Github Gist.
HTML таблицы основы
Этот раздел познакомит вас с таблицами HTML, представив самые базовые понятия — строки и ячейки, заголовки, слияние строк и столбцов, а также объединение всех ячеек в столбце в целях стилизации.
| Начальные условия: | Знание основ HTML (читайте Введение в HTML — Introduction to HTML). |
|---|---|
| Цель: | Общее знакомство с таблицами HTML. |
Что такое таблица ?
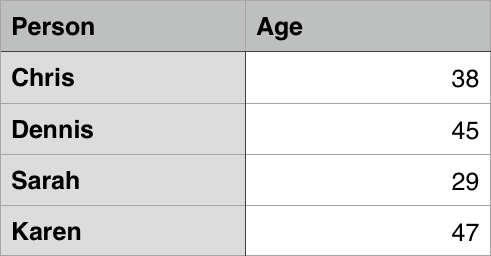
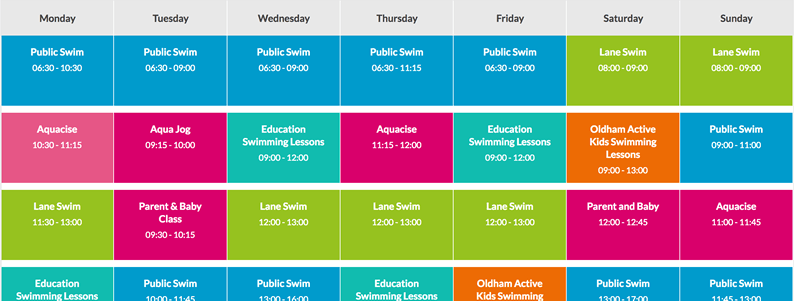
Таблица — это структурированный набор данных, состоящий из строк и столбцов (табличных данных). Таблицы позволяют быстро и легко посмотреть значения, показывающие некоторую взаимосвязь между различными типами данных, например — человек и его возраст, или расписание в плавательном бассейне.
Люди постоянно используют таблицы, причём уже давно, как показывает документ по переписи в США, относящийся к 1800 году:

Так что не удивительно, что создатели HTML включили в него средства для структурирования и представления табличных данных в сети.
Как работает таблица?
Смысл таблицы в том, что она жёсткая. Информацию легко интерпретировать, визуально сопоставляя заголовки строк и столбцов. Например, посмотрите на приведённую ниже таблицу и найдите единственное личное местоимение, используемое в третьем лице , с полом ♀, выступающее в качестве объекта в предложении. Ответ можно найти, сопоставив соответствующие заголовки столбцов и строк.
| Субъект | Объект | |||
|---|---|---|---|---|
| Единствен. числ. | 1 Лицо | Я | меня | |
| 2 Лицо | ты | тебя | ||
| 3 Лицо | ♂ | он | его | |
| ♀ | она | её | ||
| o | оно | его | ||
| Множ.числ. | 1 Лицо | мы | нас | |
| 2 Лицо | вы | вас | ||
| 2 Лицо | они | их | ||
Если правильно представить таблицу HTML, интерпретировать её данные смогут даже люди, имеющие проблемы со зрением.
Оформление таблиц
Исходный код HTML (HTML source code) вышеприведённой таблице есть в GitHub; посмотрите его и живой пример (look at the live example)! Вы заметите, что таблица там выглядит иначе — это потому, что на сайте MDN к этим данным была применена таблица стилей, а приведённый в GitHub пример информации о стиле не имеет.
Не питайте ложных иллюзий — чтобы эффективно представлять таблицы в веб, необходимо придать им хорошую структуру в HTML и применить к ним таблицы стилей (CSS). В данном разделе мы сфокусируемся на HTML, чтобы узнать о том, что касается CSS, вам надо обратиться к статье Стилизация таблиц.
В этом разделе мы не фокусируемся на CSS, но всё же дали простейшую таблицу стилей CSS, чтобы сделать таблицы более читабельными. Эту таблицу стилей можно найти здесь, можно также использовать шаблон HTML, применяющий эту стаблицу стилей — вместе они дадут вам хорошую основу для экспериментов с таблицами HTML.
Примечание: Посмотрите также таблицу personal_pronouns с применённым к ней стилем, чтобы получить представление о том, как она выглядит.
Когда не надо использовать таблицы HTML?
HTML-таблицы следует использовать для табличных данных — это то, для чего они предназначены. К сожалению, многие используют таблицы HTML для оформления веб-страниц, например, одна строка для заголовка, одна для содержимого, одна для сносок, и тому подобное. Подробнее об этом можно узнать в разделе Вёрстка на Начальном обучающем модуле доступности. Это происходило из-за плохой поддержки CSS в разных браузерах; в наше время такое встречается гораздо реже, но иногда всё же попадается.
Короче говоря, использование таблиц в целях оформления вместо методов CSS является плохой идеей по следующим причинам :
- Таблицы, используемые для оформления, уменьшают доступность страниц для людей, имеющих проблемы со зрением: Скринридеры (Screenreaders (en-US)), используемые ими, интерпретируют HTML-теги и читают содержимое пользователю. Поскольку таблицы не являются средством для представления структуры таблицы, и разметка получается сложнее, чем при использовании методов CSS, скринридеры вводят пользователей в заблуждение.
- Таблицы создают путаницу тегов: Как уже упоминалось, оформление страниц с помощью таблиц даёт более сложную структуру разметки, чем специально предназначенные для этого методы. Соответственно, такой код труднее писать, поддерживать и отлаживать.
- Таблицы не реагируют автоматически на тип устройства: У надлежащих контейнеров (например, , , , или ) ширина по умолчанию равна 100% от их родительского элемента. У таблиц же размер по умолчанию подстраивается под их содержимое, так что чтобы они одинаково хорошо работали на разных типах устройств необходимо принимать дополнительные меры.
Упражнение: ваша первая таблица
Итак, мы уже достаточно говорили о теории, теперь возьмём конкретный пример и построим таблицу.
- Прежде всего, создайте локальную копию blank-template.html и minimal-table.css в новой папке на вашем компьютере.
- Содержимое любой таблицы заключается между двумя тегами : (en-US). Добавьте их в тело HTML.
- Самым маленьким контейнером в таблице является ячейка, она создаётся элементом (‘td’ — сокращение от ‘table data’). Введите внутри тегов table следующее:
td>Hi, I'm your first cell.td>
td>Hi, I'm your first cell.td> td>I'm your second cell.td> td>I'm your third cell.td> td>I'm your fourth cell.td>
tr> td>Hi, I'm your first cell.td> td>I'm your second cell.td> td>I'm your third cell.td> td>I'm your fourth cell.td> tr>
В результате получится таблица, которая будет выглядеть примерно так:
| Hi, I’m your first cell. | I’m your second cell. | I’m your third cell. | I’m your fourth cell. |
|---|---|---|---|
| Second row, first cell. | Cell 2. | Cell 3. | Cell 4. |
Примечание: Этот пример можно также найти на GitHub под названием simple-table.html (see it live also).
Добавление заголовков с помощью элементов
Теперь обратимся к табличным заголовкам — особым ячейкам, которые идут вначале строки или столбца и определяют тип данных, которые содержит данная строка или столбец (как «Person» и «Age» в первом примере данной статьи). Чтобы показать, для чего они нужны, возьмём следующий пример. Сначала исходный код:
table> tr> td> td> td>Knockytd> td>Flortd> td>Ellatd> td>Juantd> tr> tr> td>Breedtd> td>Jack Russelltd> td>Poodletd> td>Streetdogtd> td>Cocker Spanieltd> tr> tr> td>Agetd> td>16td> td>9td> td>10td> td>5td> tr> tr> td>Ownertd> td>Mother-in-lawtd> td>Metd> td>Metd> td>Sister-in-lawtd> tr> tr> td>Eating Habitstd> td>Eats everyone's leftoverstd> td>Nibbles at foodtd> td>Hearty eatertd> td>Will eat till he explodestd> tr> table>
Теперь как выглядит таблица:
| Knocky | Flor | Ella | Juan | |
|---|---|---|---|---|
| Breed | Jack Russell | Poodle | Streetdog | Cocker Spaniel |
| Age | 16 | 9 | 10 | 5 |
| Owner | Mother-in-law | Me | Me | Sister-in-law |
| Eating Habits | Eats everyone’s leftovers | Nibbles at food | Hearty eater | Will eat till he explodes |
Проблема в том, что, хотя вы и можете представить, о чем идёт речь, ссылаться на эти данные не так легко, как хотелось бы. Лучше, чтобы строка и столбец с заголовками как-то выделялись.
Упражнение: заголовки
Попробуем улучшить эту таблицу.
Примечание: Законченный пример можно найти на dogs-table-fixed.html в GitHub (посмотрите живой пример).
Для чего нужны заголовки?
Мы уже частично ответили на этот вопрос — когда заголовки выделяются, легче искать данные и таблица выглядит лучше.
Примечание: По умолчанию к заголовкам таблицы применяется определённый стиль — они выделены жирным шрифтом и выровнены по центру, даже если вы не задавали для них стиль специально.
Заголовки дают дополнительное преимущество — вместе с атрибутом scope (который мы будем изучать в следующей статье) они помогают улучшить связь каждого заголовка со всеми данными строки или столбца одновременно, что довольно полезно
Слияние нескольких строк или столбцов
Иногда нам нужно, чтобы ячейки распространялись на несколько строк или столбцов. Возьмём простой пример, в котором приведены имена животных. Иногда бывает нужно вывести имена людей рядом с именами животных. А иногда это не требуется, и тогда мы хотим, чтобы имя животного занимало всю ширину.
Исходная разметка выглядит так:
table> tr> th>Animalsth> tr> tr> th>Hippopotamusth> tr> tr> th>Horseth> td>Maretd> tr> tr> td>Stalliontd> tr> tr> th>Crocodileth> tr> tr> th>Chickenth> td>Cocktd> tr> tr> td>Roostertd> tr> table>
Но результат не такой, как хотелось бы:
| Animals | |
|---|---|
| Hippopotamus | |
| Horse | Mare |
| Stallion | |
| Crocodile | |
| Chicken | Cock |
| Rooster |
Нужно, чтобы «Animals», «Hippopotamus» и «Crocodile» распространялись на два столбца, а «Horse» и «Chicken» — на две строки. К счастью, табличные заголовки и ячейки имеют атрибуты colspan и rowspan , которые позволяют это сделать. Оба принимают безразмерное числовое значение, которое равно количеству строк или столбцов, на которые должны распространяться ячейки. Например, colspan=»2″ распространяет ячейку на два столбца.
Воспользуемся colspan и rowspan чтобы улучшить таблицу.
- Сначала создайте локальную копию animals-table.html и minimal-table.css в новой папке на вашем компьютере. Код HTML содержит пример с животными, который вы уже видели выше.
- Затем используйте атрибут colspan чтобы распространить «Animals», «Hippopotamus» и «Crocodile» на два столбца.
- Наконец, используйте атрибут rowspan чтобы распространить «Horse» и «Chicken» на две строки.
- Сохраните код и откройте его в браузере, чтобы увидеть улучшения.
Примечание: Законченный пример можно посмотреть в animals-table-fixed.html на GitHub (живой пример).
Стилизация столбцов
И последняя возможность, о которой рассказывается в данной статье. HTML позволяет указать, какой стиль нужно применять к целому столбцу данных сразу — для этого применяют элементы и (en-US) . Их ввели, поскольку задавать стиль для каждой ячейки в отдельности или использовать сложный селектор вроде :nth-child() было бы слишком утомительно.
Возьмём простой пример:
table> tr> th>Data 1th> th style="background-color: yellow">Data 2th> tr> tr> td>Calcuttatd> td style="background-color: yellow">Orangetd> tr> tr> td>Robotstd> td style="background-color: yellow">Jazztd> tr> table>
| Data 1 | Data 2 |
|---|---|
| Calcutta | Orange |
| Robots | Jazz |
table> colgroup> col /> col style="background-color: yellow" /> colgroup> tr> th>Data 1th> th>Data 2th> tr> tr> td>Calcuttatd> td>Orangetd> tr> tr> td>Robotstd> td>Jazztd> tr> table>
Мы определяем два «стилизующих столбца». Мы не применяем стиль к первому столбцу, но пустой элемент ввести необходимо — иначе стиль будет применён только к первому столбцу.
Если бы мы хотели применить информацию о стиле к обоим столбцам, мы могли бы просто ввести один элемент с атрибутом span, таким образом:
colgroup> col style="background-color: yellow" span="2" /> colgroup>
Подобно colspan и rowspan , span принимает безразмерное числовое значение, указывающее, к какому количеству столбцов нужно применить данный стиль.
Упражнение: colgroup и col
Теперь попробуйте сами.
Ниже приведена таблица уроков по языкам. В пятницу (Friday) новый класс целый день изучает голландский (Dutch), кроме того, во вторник (Tuesday) и четверг (Thursdays) есть занятия по немецкому (German). Учительница хочет выделить столбцы, соответствующие дням, когда она преподаёт.
| Mon | Tues | Wed | Thurs | Fri | Sat | Sun |
|---|---|---|---|---|---|---|
| 1st period | English | German | Dutch | |||
| 2nd period | English | English | German | Dutch | ||
| 3rd period | German | German | Dutch | |||
| 4th period | English | English | Dutch |
Заново создайте таблицу, проделав указанные ниже действия.
Посмотрите, что у вас получилось. Если застрянете, или захотите себя проверить, можете посмотреть нашу версию в timetable-fixed.html (посмотрите живой пример).
Итог
Здесь приведены практически все базовые сведения о таблицах HTML. В следующей статье вы получите более продвинутые сведения на эту тему.