Парсинг сайта с применением авторизации

Любой, кто когда-либо пытался парсить сайты на python начинал с простого запроса «get» библиотеки «requests». Запрос «get» выгружает html код страницы, который можно обрабатывать под свои нужды.
Но иногда данные доступны только после авторизации на ресурсе. В этом посте я покажу, как можно подключаться, используя логин-пароль и библиотеку «requests».
Использование сессий дает преимущества в скорости парсинга данных и исключает блокировку учетной записи. Если приходится выгружать данные — страницу сайта за страницей, при каждом новом запросе будет создаваться новый запрос с новым подключением к сайту, при использовании сессии она создается один раз и используется на всем протяжении работы.
Возьмем сайт https://ivi.ru/ и попытаемся залогиниться.
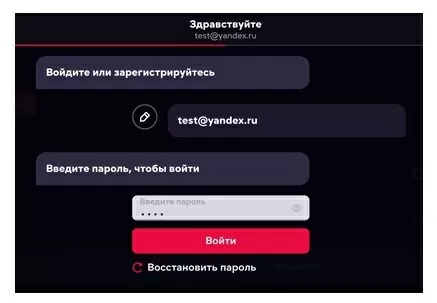
Для авторизации требуется ввести email и пароль. В библиотеке requests есть метод «POST», с помощью которого реализуются отправки данных на сервер. Общий вид использования метода: «requests.post(url, headers, data)». «url» ссылка на ресурс, «headers» заголовки запроса, «data» данные запроса, которые мы будем передавать.
Импорт, авторизация и исходные параметры
pip install requestsПрежде всего, нужно узнать, откуда брать данные «headers» и «data». Для этого запустим инструмент разработчика. Переходим во вкладку СЕТЬ и обновляем страницу. Здесь видим все активности сети.
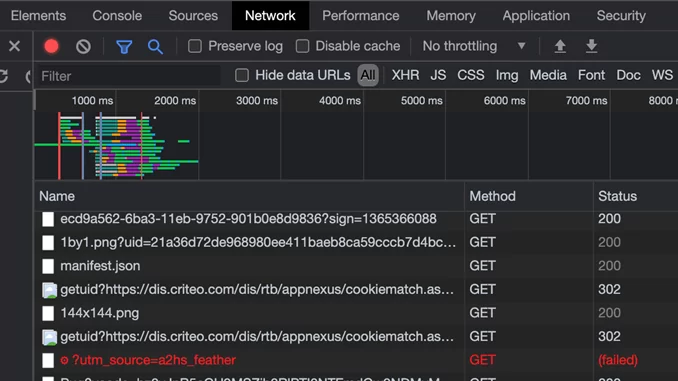
На главной странице сайта входим в профиль. Открывается форма авторизации, вводим логин-пароль и нажимаем кнопку ВОЙТИ. Ищем нашу ссылку.
Чтобы быстрее находить нужную строку в отображении полей нужно добавить поле «Method» и по нему отсортировать столбец. Данные на авторизацию отправляются в «POST» запросах.
Находим строку v5/

Смотрим информацию по этой строке
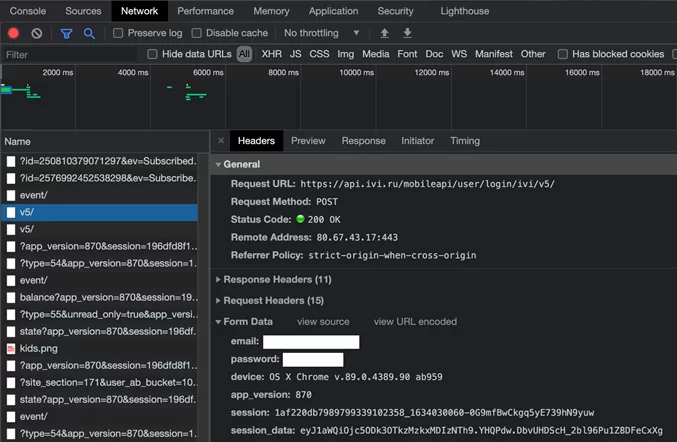
Во вкладке «headers» находим «General» в нем возьмем «url», в «Request Headers» нас интересует только «User-Agent», который пропишем в «headers», в «Form Data» данные для запроса «data».
import requestsurl = 'https://api.ivi.ru/mobileapi/user/login/ivi/v5/'headers = < 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36' >data =
Создаем сессию, она будет держать наше соединение с сайтом, и мы сможем с ним работать.
session = requests.Session() session.headers.update(headers) response = session.post(url, data=data) Смотрим статус ответа
response
Ответ 200 означает успешный ответ от сервера.
Посмотрим, что возвратил наш запрос
response.json(), 'email': 'test@yandex.ru', 'email_real': 1, 'msisdn': '', 'confirmed': 1, 'storageless': False, 'is_debug': False, 'children': [], 'basic': '0.0000', 'bonus': '0.0000'>> Здесь важная строка «session», которая указывает на наш номер сессии. Дальше в примере будет видно, что, если бы мы не создали сессию, изменить данные нам бы не удалось.
Попробуем поменять данные профиля. Нажимаем на кнопку редактировать и меняем имя.
Ищем в инструменте разработчика нашу строку. Чтобы не было много записей, можно сразу же после нажатия кнопки сохранить остановить загрузку страницы, «POST» запрос на изменение будет идти первым, только после этого происходит загрузка страницы с обновленными данными.
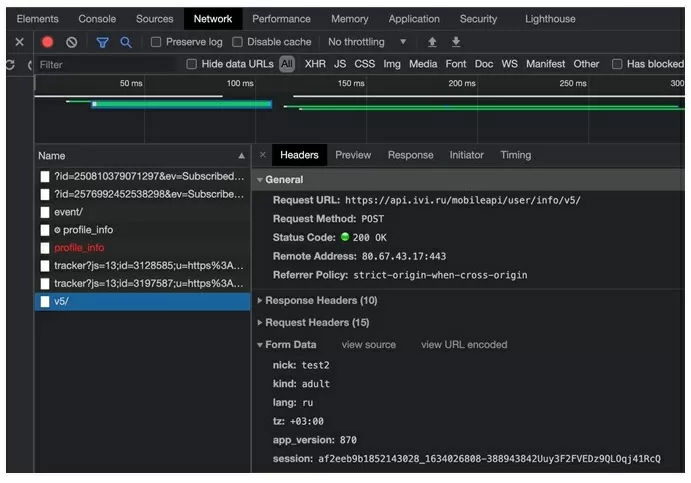
Записываем «url» и копируем «data». Необходимо обратить внимание на строку «session», где нужно передать наш номер сессии. Номер берем из ответа сервера.
url_change_nick = 'https://api.ivi.ru/mobileapi/user/info/v5/'session_id = response.json()['result']['session'] data =
response = session.post(url_change_nick, data=data)Чтобы удостовериться в работе нашего кода обновляем страницу в браузере.

Наш код успешно сработал.
Использование учетных данных WINDOWS
Также бывают редкие случаи, когда нужно использовать логин-пароль от учетной записи Windows. Для этого можно использовать библиотеку «requests-negotiate-sspi». Она становится особенно полезной, когда часто меняется пароль от учетной записи.
Устанавливаем и импортируем библиотеку, нам нужен метод «HttpNegotiateAuth»
pip install requests_negotiate_sspi from requests_negotiate_sspi import HttpNegotiateAuth Повторяем все, что делали выше: прописываем «headers», заполняем «data» и поднимаем сессию. Попробуем получить дату и время сервера.
Вначале сделаем запрос без передачи данных авторизации
xml_request = ''' ''' headers = < 'Host': host_name, 'Content-Type': 'text/xml; charset=utf-8', 'Content-Length': str(len(xml_request)) >session.headers = headers response = session.post('http://' + host_name + '/ServerService.asmx?WSDL', data=xml_request) response Посмотрим текст ответа
response.text401 - Unauthorized: Access is denied due to invalid credentials. Как мы видим ошибка авторизации.
Повторяем запрос с использованием «HttpNegotiateAuth»
response = session.post('http://' + host_name + '/ServerService.asmx?WSDL', auth=HttpNegotiateAuth(), data=xml_request) response.text 44298.576980902777 Ответ на запрос даты и времени сервера получен успешно.
Sessions позволяет вам использовать requests более эффективно и решать проблемы с подключением к аккаунту, ускорять работу выполнения запросов и исключать блокировку при ограничении количества соединений.
Python парсинг с авторизацией
Пытаюсь парсить информацию о своём персонаже в браузерной игре. Для этого нужно залогинится. Как это сделать?
Пишу такой вот код:
import requests URL = "https://tiwar.ru/?sign_in=1" r = requests.post(URL, data=) print(r.text) Выдает код страницы с вводом логина и пароля:
Пароль:
Заметил, что в input для login есть по умолчанию value со значением «», а у пароля нет, думаю в этом проблема. Как можно заполнить? P.S. Пришел к такому выводу, так как в другой игре есть значения и для логина и пароля по умолчанию и я могу парсить данные своего персонажа при точно таком же коде:
import requests URL = "https://s7-ru.bitefight.gameforge.com/user/lobbylogincheck" # Парсится без проблем с авторизацией r = requests.post(URL, data=) print(r.text) Как спарсить сайт, который требует авторизацию с помощью гугла?
Захотел спарсить маркетплейс, на котором требуется авторизация с помощью гугл аккаунта прежде чем появится доступ к страницам. Тут же встал вопрос: как это сделать?
P.s. Парсить сайты я умею, нужен именно совет по авторизации с помощью гугл аккаунта
- Вопрос задан более двух лет назад
- 349 просмотров
2 комментария
Простой 2 комментария

Python-то тут при чём?
Saboteur @saboteur_kiev
P.s. Парсить сайты я умею,
Ну это не совсем так, раз проблема с авторизацией оказалась таким блокером.
Сайты не хранят аккаунты пользователя в гугле, следовательно при авторизации через гугл каждый сайт все равно создает локального пользователя и после авторизации выдает ему необходимые токены. Следовательно если ты не умеешь авторизироваться скриптом, нужно авторизироваться в браузере, получить все куки с токенами и использовать их в парсере, возможно также подделав User-Agent.
Решения вопроса 0
Ответы на вопрос 2
Софт для автоматизации
Самый простой способ это написать парсер на JavaScript и далее запустить его в консоли браузера, так как браузер уже авторизован на целевом сайте вашему скрипту останется лишь зайти и собрать нужные вам данные.
Ответ написан более двух лет назад
barabulka112 @barabulka112 Автор вопроса
Проблема в том, что нужно доставать необходимые данные из html страницы путем подачи запросов(не использовать браузер вообще). Для этого хочу использовать библиотеку requests и bs4, но не могу понять как авторизоваться через гугл акканут.
barabulka112, запросами можно парсить и из браузера.
barabulka112 @barabulka112 Автор вопроса
Надим Закиров, та я понимаю. Я к тому, что мне нужно парсить не используя браузер.

Dimonchik @dimonchik2013
non progredi est regredi
авториуешься руками и шлешь куки
но в целом без имитиации вряд ли долго протянет, хотя все может быть
Как парсить сайт с авторизацией?
На localhost’е формируется перечень ссылок, ведущих на отдельные страницы некого сайта site.com; ссылки имеют вид https://site.com/id/nnnnn. Есть потребность сохранить эти страницы локально, но сайт без авторизации часть информации скрывает. Данные для авторизации (логин/пароль) есть.
Понятно, что при обращении к страницам сайта он определяет факт авторизации через сессионные куки. Вопрос в том, как авторизоваться с localhost’a, используя эти самые куки?
- Вопрос задан 11 апр.
- 626 просмотров
4 комментария
Простой 4 комментария