Python Beautifulsoup Как достать ссылку из тега ?
Почему я не могу спарсить ссылку из тега ? Я делаю вроде всё правильно. Этот вопрос связан с моим предыдущим вопросом. Я хочу, чтобы выдавало ссылку, а выдаёт None. Сам код:
def get_content(html): soup = BeautifulSoup(html, 'html.parser') items = soup.find_all('section', class_='proposition') cars = [] for item in items: titles = None if titles_tag := item.find('div', class_='proposition_title'): if titles_1_tag := titles_tag.find('h3'): titles = titles_1_tag.get_text(strip=True) links = None if links_tag := item.find('section', class_='proposition'): if links_1_tag := links_tag.find('a'): links = links_1_tag.get('href') usd_prices = None if usd_prices_tag := item.find('div', class_='proposition_price'): if usd_prices_1_tag := usd_prices_tag.find('span'): usd_prices = usd_prices_1_tag.get_text(strip=True) cars.append( < 'title': titles, 'link': links, 'usd_price': usd_prices, >) print(cars) Проблема в:
links = None if links_tag := item.find('section', class_='proposition'): if links_1_tag := links_tag.find('a'): links = links_1_tag.get('href') Если нужно, то скину сайт, на котором я парсю.
Извлечение HTML-строки из объекта bs4 в Python
Извлечение HTML из объекта BeautifulSoup возможно двумя методами: с помощью soup.prettify() , возвращающем отформатированный HTML, и str(soup) , который возвращает неотформатированную строку HTML. На практике это выглядит так:
Скопировать код
from bs4 import BeautifulSoup # Предположим, у нас есть объект BeautifulSoup – 'soup'. print(soup.prettify()) # Отформатированный HTML print(str(soup)) # HTML в виде неотформатированной строкиДетальный разбор
Разберёмся, каким образом можно извлечь содержимое HTML с использованием BeautifulSoup.
Извлечение текста и тегов
Вы можете отделить текст от тегов или извлечь определённые теги следующим образом:
Скопировать код
# Выведем только текст, исключая теги print(soup.get_text()) # Выведем содержимое конкретного тега print(soup.find('span')) # Как часто вы сталкиваетесь со span в своем "супе"?Особенности различных методов
Помимо этого, обратите внимание на разницу в работе следующих методов:
- soup.prettify() добавляет в код переносы строк и отступы для удобства чтения. Он предназначен для создания красивого представления кода.
- str(soup) возвращает HTML в исходном виде, без дополнительного форматирования. Это, можно сказать, прямолинейный подход.
Обработка специальных символов
Заботьтесь о корректной кодировке, если вы работаете с необычными символами:
Скопировать код
# Преобразуем вывод в кодировку UTF-8 print(soup.prettify().encode('utf-8')) # Готовы к международному форматуВизуализация
Представьте себе строителя (��), который по чертежам (��), представляющим собой объект Beautiful Soup, строит веб-страницу:
Скопировать код
��♂️ Строитель: "Хм. Этот чертёж что-то прямо особенное. Понятно, это объект Beautiful Soup!" �� Чертёж: [Объект Beautiful Soup с HTML-элементами и их структурой]Из строительных материалов получается окончательное здание (��) — это наш HTML-код:
Скопировать код
�� Готовая конструкция: ". " # И вот перед вами — объект Beautiful Soup в виде превосходной HTML-структуры!Иль простым языком :
Скопировать код
BeautifulSoupObject -> ��♂️ -> �� -> 'Готовый HTML'Это описывает процесс преобразования объекта Beautiful Soup в HTML-код.
Подсказки и советы
Навигация по HTML-структуре
Методы .contents или .children позволят вам навигировать по структуре HTML:
Скопировать код
# Дочерние элементы объекта soup print(soup.contents) # Все дочерние элементы объекта soup, рекурсивно for child in soup.children: print(child) # Когда-нибудь думали, что у супа могут быть дети?Обращение к атрибутам
Для того чтобы получить атрибуты, вроде id , class или data-атрибуты, используйте синтаксис обращения к словарю:
Скопировать код
# Обращение к атрибуту 'id' первого элемента div print(soup.find('div')['id']) # Ищете ID для div? Вот он!Обработка неполных тегов
Иногда теги могут быть неполными или вовсе отсутствовать. BeautifulSoup отлично справляется и с такими случаями:
Скопировать код
# Парсинг неполного HTML soup = BeautifulSoup("Ой, а где закрывающий тег?", 'html.parser') print(soup.prettify()) # Недостающие теги найдены и добавлены.
Работа с комментариями и скриптами
Комментарии и скрипты также можно удалять и обрабатывать:
Скопировать код
from bs4 import Comment # Удаление всех комментариев comments = soup.findAll(text=lambda text: isinstance(text, Comment)) [comment.extract() for comment in comments] # До свидания, комментарии! # Поиск тегов script script_tags = soup.find_all('script') # Если они вам не по душе, просто избавьтесь от них!Полезные ресурсы
- Официальная документация Beautiful Soup — основной источник информации по всем вопросам, связанным с Beautiful Soup.
- Учебник по Beautiful Soup: создание веб-скрейпера на Python от Real Python — отличный ресурс для тех, кто хотел бы изучить сбор данных из сети с использованием Beautiful Soup и Python.
- Веб-скрапинг с использованием Beautiful Soup и Requests: учебный курс на YouTube от Кори Шафера — видеокурс, в котором детально рассказывается о основах веб-скрапинга и использовании Beautiful Soup.
- Практическое руководство по извлечению содержимого HTML с помощью Beautiful Soup на Python от DigitalOcean — с помощью этого руководства вы сможете освоить практическое применение Beautiful Soup.
- Статья на Medium о способах извлечения атрибутов, текста и HTML с помощью Beautiful Soup на Towards Data Science — интересное чтение для тех, кто работает с Beautiful Soup.
- Краткое руководство по началу работы с Beautiful Soup — полезное руководство для начинающих разработчиков, только начинающих знакомиться с HTML-парсингом.
Как вытащить «src» из тега «img» через BeautifulSoup

Всем привет. Искал долго, но решения так и не нашёл.
Есть такой код, он выводит все теги img со страницы (по определённым причинам не могу раскрыть сам сайт). Потому что нужно именно все, вне зависимости от класса и месторасположения. Однако у меня не получается вытащить от туда ссылку картинки src, т.к. я новичок и разумеется данный код не то, чтобы сам написал, буду признателен, если в ответе вы укажете код в качестве примера.
import requests from bs4 import BeautifulSoup url = 'какой-то сайт' response = requests.get(url) soup = BeautifulSoup(response.content, 'lxml') images = soup.find_all('img') for image in images: print (images)
Парсинг сайта вместе с Python и библиотекой Beautiful Soup: простая инструкция в три шага
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.

Иллюстрация: Катя Павловская для Skillbox Media

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Что такое парсинг и зачем он нужен?
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP-запросы, XML и JSON
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
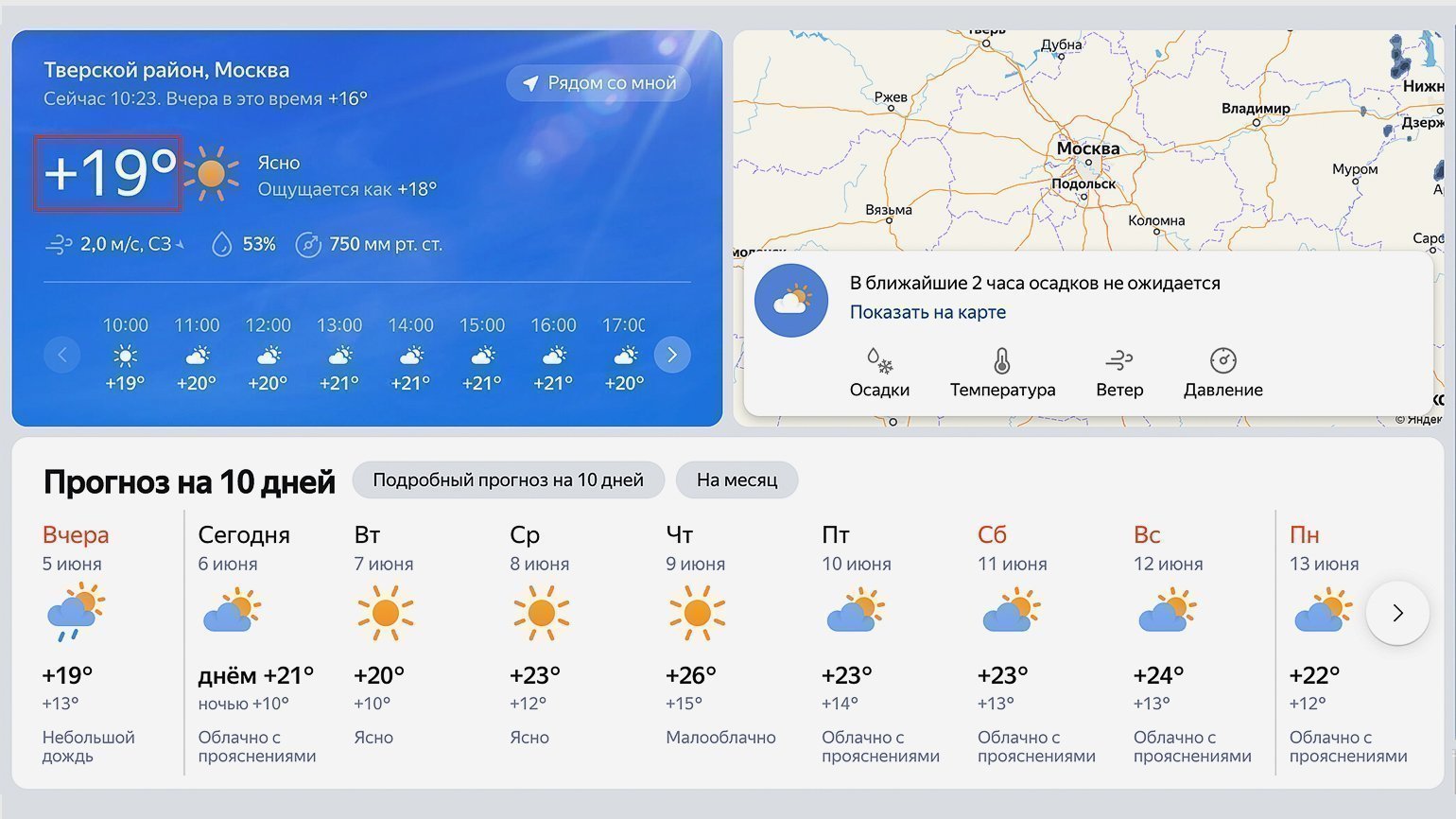
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
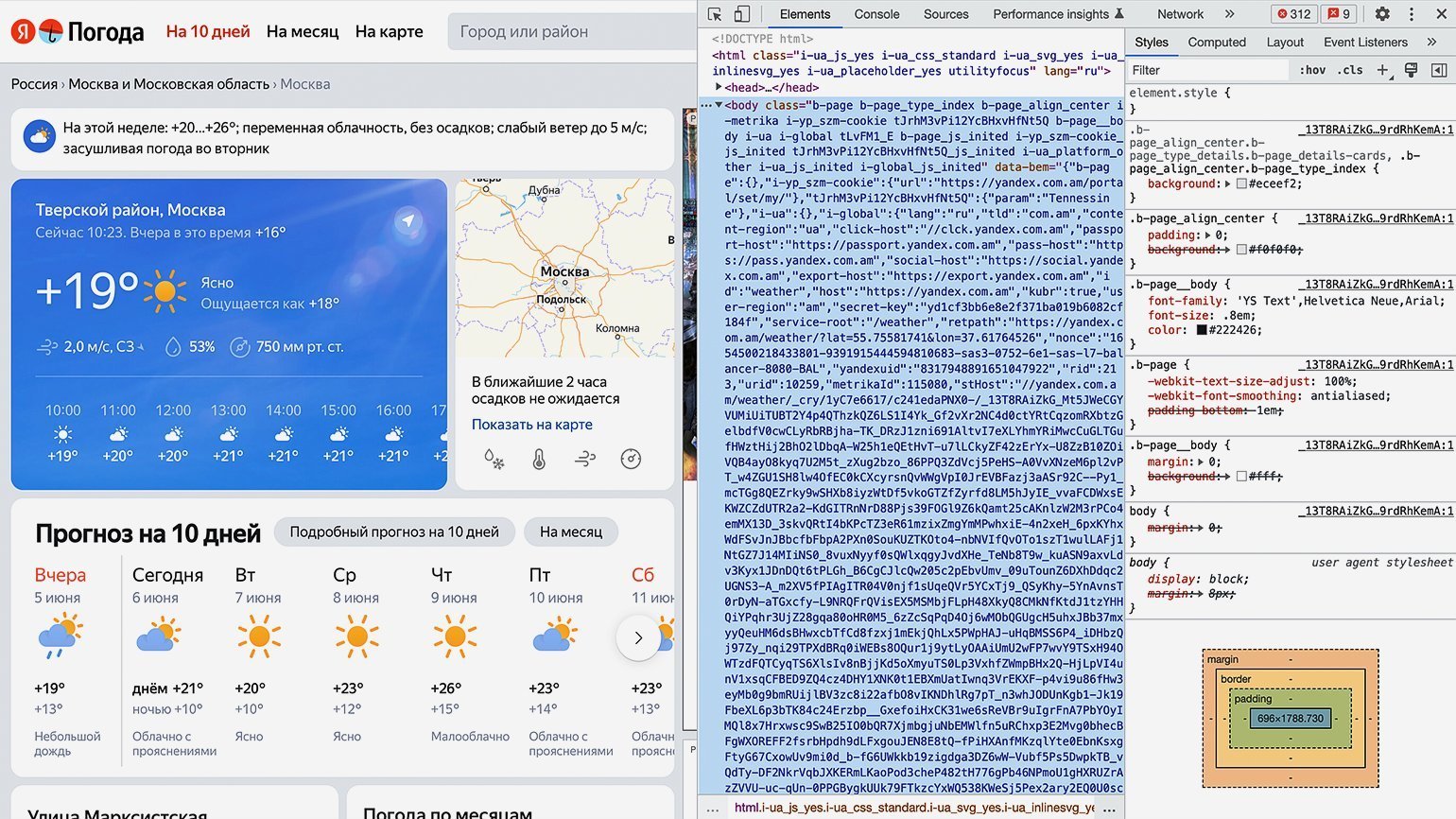
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега . Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
Шаг 3
Пишем код и получаем необходимую информацию
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента . Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это . Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
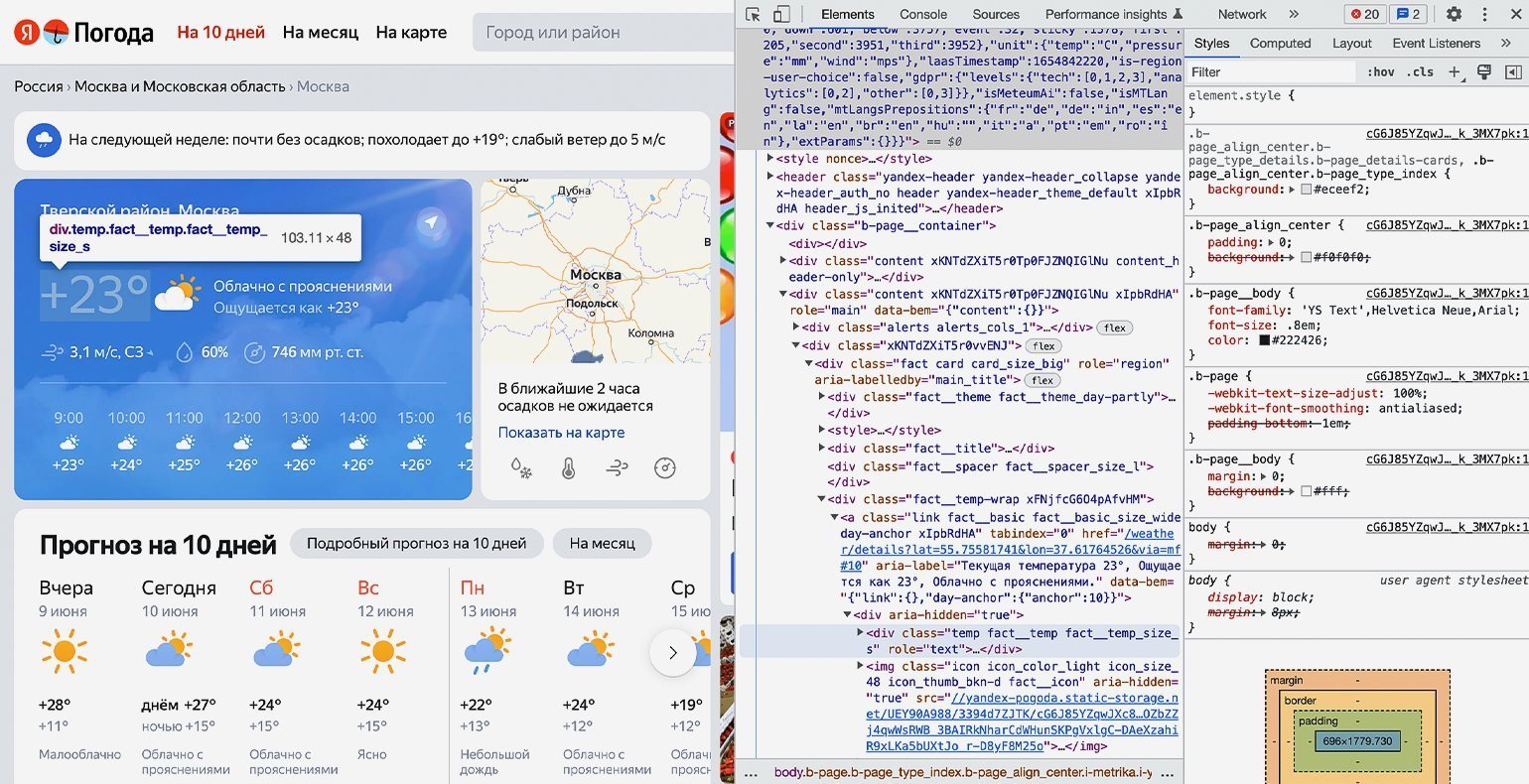
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
class="temp__value temp__value_with-unit">+17
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Скрапинг веб-сайтов с помощью Python — мастер-класс для новичков
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Запись вебинара по скрапингу сайтов с помощью Python и библиотеки Beautiful Soup
Парсинг динамических сайтов c помощью Python и библиотеки Selenium
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Запись вебинара по сбору данных с помощью библиотек Selenium и Beautiful Soup
Резюме
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.
Читайте также:
- 3 фреймворка для тестирования на Python: обзор конфигураций
- 5 шаблонов проектирования, которые должен освоить каждый разработчик
- Как происходит модульное тестирование в Python