Запросы
С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
К примеру, разные товары могут иметь одних и тех же производителей, и, допустим, у нас следующая таблица товаров:
USE productsdb; DROP TABLE IF EXISTS Products; CREATE TABLE Products ( Id INT AUTO_INCREMENT PRIMARY KEY, ProductName VARCHAR(30) NOT NULL, Manufacturer VARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price DECIMAL NOT NULL ); INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES ('iPhone X', 'Apple', 3, 71000), ('iPhone 8', 'Apple', 3, 56000), ('Galaxy S9', 'Samsung', 6, 56000), ('Galaxy S8', 'Samsung', 2, 46000), ('Honor 10', 'Huawei', 3, 26000);
Выберем всех производителей:
SELECT Manufacturer FROM Products;
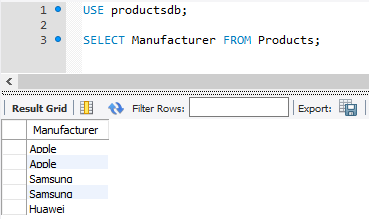
Однако при таком запросе производители повторяются. Теперь применим оператор DISTINCT для выборки уникальных значений:
SELECT DISTINCT Manufacturer FROM Products;
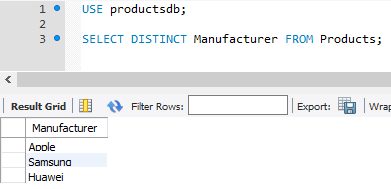
Также мы можем задавать выборку уникальных значений по нескольким столбцам:
SELECT DISTINCT Manufacturer, ProductCount FROM Products;
В данном случае для выборки используются столбцы Manufacturer и ProductCount. Из пяти строк только для двух строк эти столбцы имеют повторяющиеся значения. Поэтому в выборке будет 4 строки:
Как выбрать уникальные значения не используя distinct?
может быть используя подзапрос, группировку строк и оконную функцию.
не уверен, что код сработает, но как-то так:
select * from ( SELECT dp.id_dep, dep.code_department, dp.code_place, vc.valuename, vr.valueseria, vr.nominal, vr.bаlrate, vr.dt_open, FROM valuerests vr JOIN valuecodes vc ON vr.id_value = vc.id_value JOIN valuekinds vk ON vc.id_valkind = vk.id_valkind JOIN place dp ON vr.id_place = dp.id_place JOIN department dep ON dp.id_dep = dep.id_department WHERE vk.code = 'AAA' AND vr.balrate > 0 AND vr.dt_open = :p_dt AND dp.code_place = :p_cp ) where ROW_NUMBER() OVER(PARTITION BY id_dep, code_department, code_place, valuename,valueseria,nominal,bаlrate, dt_open ORDER BY balrate DESC) = 1 суть в том, чтобы дать номера строкам в группировке и брать только те, где 1(то есть не повторяющиеся)
чтобы его запустить надо поэксперементировать, надеюсь идея окажется полезной 🙂
select tbl.*, ROW_NUMBER() OVER(PARTITION BY id_dep, code_department, code_place, valuename,valueseria,nominal,bаlrate, dt_open ORDER BY balrate DESC) as ic from ( SELECT dp.id_dep, dep.code_department, dp.code_place, vc.valuename, vr.valueseria, vr.nominal, vr.bаlrate, vr.dt_open, FROM valuerests vr JOIN valuecodes vc ON vr.id_value = vc.id_value JOIN valuekinds vk ON vc.id_valkind = vk.id_valkind JOIN place dp ON vr.id_place = dp.id_place JOIN department dep ON dp.id_dep = dep.id_department WHERE vk.code = 'AAA' AND vr.balrate > 0 AND vr.dt_open = :p_dt AND dp.code_place = :p_cp ) tbl where ic = 1 select * from ( select t.*, ROW_NUMBER() OVER(PARTITION BY c1,c2,c3,c4 order by c2 DESC) as Ic from ( select 'AA' as c1, 12 as c2, 33.5 as c3, 'BB' as c4 UNION ALL select 'AA' as c1, 12 as c2, 33.5 as c3, 'BB' as c4 UNION ALL select 'AA' as c1, 12 as c2, 33.5 as c3, 'BB' as c4 ) t )t2 where Ic = 1 Уникальные записи – SELECT DISTINCT
Примечание:
Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
В подавляющем большинстве случаев, записи в таблицах баз данных уникальны, но в отдельных столбцах допускаются повторяющиеся значения. Если запрос выгружает столбцы не являющиеся ключевыми, то полученные строки могут дублироваться.
Избавиться от дубликатов можно, добавив в запрос ключевое слово DISTINCT. Оно указывается в предложении SELECT, сразу после ключевого слова SELECT:
SELECT DISTINCT FROM
Выбрать уникальные имена всех сотрудников.
-- Выполняем запрос в контексте учебной базы USE CallCenter SELECT DISTINCT Имя FROM Сотрудники
Общее количество записей в таблице сотрудников составляет 39, но приведенный SQL-код выгрузил 34 строки. 5-ть повторяющихся имен были удалены из результата.
Дополним синтаксис оператора SELECT, описанный в предыдущем уроке, новым ключевым словом:
SELECT [DISTINCT] [Имя_таблицы.]Имя_столбца[, [Имя_таблицы.]Имя_столбца2 …] FROM [[Имя_базы_данных.]Имя_Схемы.]Имя_таблицы
- Объединение таблиц – UNION
- Соединение таблиц – операция JOIN и ее виды
- Тест на знание основ SQL
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Как посчитать уникальные значения в sql
Используем DISTINCT и COUNT() . Первый удалит дубликаты, а вторая посчитает количество строк.
SELECT COUNT(DISTINCT car_id) FROM orders; -- покажет количество уникальных car_id в таблице orders