10 приемов Python Pandas, которые сделают вашу работу более эффективной
Pandas — это широко используемый пакет Python для структурированных данных. Существует много хороших учебных пособий на данную тематику, но здесь мы бы хотели раскрыть несколько интересных приемов, которые, вероятно, еще пока неизвестны читателю, но могут оказаться крайне полезными.
read_csv
Все знают эту команду. Но если данные, которые вы пытаетесь прочитать, слишком большие, попробуйте добавить команду nrows = 5 , чтобы прочитать сначала небольшую часть данных перед загрузкой всей таблицы. В этом случае вам удастся избежать ситуации выбора неверного разделителя (не всегда в данных есть разделение в виде запятой).
(Или вы можете использовать команду ‘head’ в linux для проверки первых 5 строк в любом текстовом файле: head -c 5 data.txt )
Затем вы можете извлечь список столбцов, используя df.columns.tolist() , а затем добавить команду usecols = [‘c1’, ‘c2’,…], чтобы извлечь только нужные вам столбцы. Кроме того, если вы знаете типы данных определенных столбцов, вы можете добавить dtype = для более быстрой загрузки. Еще одно преимущество этой команды в том, что если у вас есть столбец, который содержит как строки, так и числа, рекомендуется объявить его тип строковым, чтобы не возникало ошибок при попытке объединить таблицы, используя этот столбец в качестве ключа.
select_dtypes
Если предварительная обработка данных должна выполняться в Python, то эта команда сэкономит ваше время. После чтения из таблицы типами данных по умолчанию для каждого столбца могут быть bool, int64, float64, object, category, timedelta64 или datetime64. Вы можете сначала проверить распределение с помощью
df.dtypes.value_counts()
чтобы узнать все возможные типы данных вашего фрейма, затем используйте
df.select_dtypes(include=[‘float64’, ‘int64’])
чтобы выбрать субфрейм только с числовыми характеристиками.
сopy
Это важная команда. Если вы сделаете:
import pandas as pd
df1 = pd.DataFrame(< ‘a’:[0,0,0], ‘b’: [1,1,1]>)
df2 = df1
df2[‘a’] = df2[‘a’] + 1
df1.head()
Вы обнаружите, что df1 изменен. Это потому, что df2 = df1 не делает копию df1 и присваивает ее df2, а устанавливает указатель, указывающий на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, вы можете сделать либо:
df2 = df1.copy ()
from copy import deepcopy
df2 = deepcopy(df1)
map
Это классная команда для простого преобразования данных. Сначала вы определяете словарь, в котором «ключами» являются старые значения, а «значениями» являются новые значения.
level_map =
df[‘c_level’] = df[‘c’].map(level_map)
Например: True, False до 1, 0 (для моделирования); определение уровней; определяемые пользователем лексические кодировки.
apply or not apply?
Если нужно создать новый столбец с несколькими другими столбцами в качестве входных данных, функция apply была бы весьма полезна.
def rule(x, y):
if x == ‘high’ and y > 10:
return 1
else:
return 0
df = pd.DataFrame(< 'c1':[ 'high' ,'high', 'low', 'low'], 'c2': [0, 23, 17, 4]>)
df['new'] = df.apply(lambda x: rule(x['c1'], x['c2']), axis = 1)
df.head()
В приведенных выше кодах мы определяем функцию с двумя входными переменными и используем функцию apply, чтобы применить ее к столбцам ‘c1’ и ‘c2’.
но проблема «apply» заключается в том, что иногда она занимает очень много времени.
Скажем, если вы хотите рассчитать максимум из двух столбцов «c1» и «c2», конечно, вы можете применить данную команду
df[‘maximum’] = df.apply(lambda x: max(x[‘c1’], x[‘c2’]), axis = 1)
но это будет медленнее, нежели:
df[‘maximum’] = df[[‘c1’,’c2']].max(axis =1)
Вывод: не используйте команду apply, если вы можете выполнить ту же работу используя другие функции (они часто быстрее). Например, если вы хотите округлить столбец ‘c’ до целых чисел, выполните округление (df [‘c’], 0) вместо использования функции apply.
value counts
Это команда для проверки распределения значений. Например, если вы хотите проверить возможные значения и частоту для каждого отдельного значения в столбце «c», вы можете применить
df[‘c’].value_counts()
Есть несколько полезных приемов / функций:
A. normalize = True : если вы хотите проверить частоту вместо подсчетов.
B. dropna = False : если вы хотите включить пропущенные значения в статистику.
C. sort = False : показать статистику, отсортированную по значениям, а не по количеству.
D. df[‘c].value_counts().reset_index().: если вы хотите преобразовать таблицу статистики в датафрейм Pandas и управлять ими.
количество пропущенных значений
При построении моделей может потребоваться исключить строку со слишком большим количеством пропущенных значений / строки со всеми пропущенными значениями. Вы можете использовать .isnull () и .sum () для подсчета количества пропущенных значений в указанных столбцах.
import pandas as pd
import numpy as np
df = pd.DataFrame(< ‘id’: [1,2,3], ‘c1’:[0,0,np.nan], ‘c2’: [np.nan,1,1]>)
df = df[[‘id’, ‘c1’, ‘c2’]]
df[‘num_nulls’] = df[[‘c1’, ‘c2’]].isnull().sum(axis=1)
df.head()
выбрать строки с конкретными идентификаторами
В SQL мы можем сделать это, используя SELECT * FROM… WHERE ID в («A001», «C022»,…), чтобы получить записи с конкретными идентификаторами. Если вы хотите сделать то же самое с pandas, вы можете использовать:
df_filter = df ['ID']. isin (['A001', 'C022', . ])
df [df_filter]
Percentile groups
Допустим, у вас есть столбец с числовыми значениями, и вы хотите классифицировать значения в этом столбце по группам, скажем, топ 5% в группу 1, 5–20% в группу 2, 20–50% в группу 3, нижние 50% в группу 4. Конечно, вы можете сделать это с помощью pandas.cut, но мы бы хотели представить другую функцию:
import numpy as np
cut_points = [np.percentile(df[‘c’], i) for i in [50, 80, 95]]
df[‘group’] = 1
for i in range(3):
df[‘group’] = df[‘group’] + (df[‘c’] < cut_points[i])
# or Которая быстро запускается (не применяется функция apply).to_csv
Опять-таки, это команда, которую используют все. Отметим пару полезных приемов. Первый:print(df[:5].to_csv())Вы можете использовать эту команду, чтобы напечатать первые пять строк того, что будет записано непосредственно в файл.
Еще один прием касается смешанных вместе целых чисел и пропущенных значений. Если столбец содержит как пропущенные значения, так и целые числа, тип данных по-прежнему будет float, а не int. Когда вы экспортируете таблицу, вы можете добавить float_format = '%. 0f', чтобы округлить все числа типа float до целых чисел. Используйте этот прием, если вам нужны только целочисленные выходные данные для всех столбцов – так вы избавитесь от всех назойливых нулей ‘.0’ .
Pandas: как проверить dtype для всех столбцов в DataFrame
Вы можете использовать следующие методы для проверки типа данных ( dtype ) для столбцов в кадре данных pandas:
Способ 1: проверить dtype одного столбца
df.column_name.dtypeСпособ 2: проверить dtype всех столбцов
df.dtypesСпособ 3: проверьте, какие столбцы имеют определенный тип dtype
df.dtypes [df.dtypes == 'int64']В следующих примерах показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team points assists all_star 0 A 18 5 True 1 B 22 7 False 2 C 19 7 False 3 D 14 9 True 4 E 14 12 True 5 F 11 9 TrueПример 1: проверка dtype одного столбца
Мы можем использовать следующий синтаксис, чтобы проверить тип данных только столбца точек в DataFrame:
#check dtype of points column df.points.dtype dtype('int64')Из вывода мы видим, что столбец точек имеет целочисленный тип данных.
Пример 2: Проверка dtype всех столбцов
Мы можем использовать следующий синтаксис для проверки типа данных всех столбцов в DataFrame:
#check dtype of all columns df.dtypes team object points int64 assists int64 all_star bool dtype: objectИз вывода мы видим:
- Столбец команды : объект (это то же самое, что и строка)
- столбец очков : целое число
- столбец помогает : целое число
- столбец all_star : логическое значение
Используя эту одну строку кода, мы можем увидеть тип данных каждого столбца в DataFrame.
Пример 3: проверьте, какие столбцы имеют определенный тип dtype
Мы можем использовать следующий синтаксис, чтобы проверить, какие столбцы в DataFrame имеют тип данных int64:
#show all columns that have a class of int64 df.dtypes [df.dtypes == 'int64'] points int64 assists int64 dtype: object Из вывода мы видим, что столбцы очков и помощи имеют тип данных int64.
Мы можем использовать аналогичный синтаксис, чтобы проверить, какие столбцы имеют другие типы данных.
Например, мы можем использовать следующий синтаксис, чтобы проверить, какие столбцы в DataFrame имеют тип данных объекта:
#show all columns that have a class of object (i.e. string) df.dtypes [df.dtypes == 'O'] team object dtype: object Мы видим, что только столбец team имеет тип данных «O», что означает объект.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции с пандами DataFrames:
Как анализировать данные на Python с Pandas: первые шаги


Мария Жарова Выпускница МФТИ, data scientist в Альфа-банк, председатель дипломной комиссии на курсе по Data Science в SkillFactory
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре. Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 790 ₽/мес 11 317 ₽/мес

Анализ данных в Pandas
-
Создание блокнота в Google Colab На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
Импортирование библиотеки Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так.
И прочитать с помощью такой команды:
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).

Если нужно посмотреть на другое количество строк, оно указывается в скобках, например df.head(12) . Последние строки фрейма выводятся методом .tail() .
Также чтобы просто полностью красиво отобразить датасет, используется функция display() . По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.

Характеристики датасета Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды: df.describe()
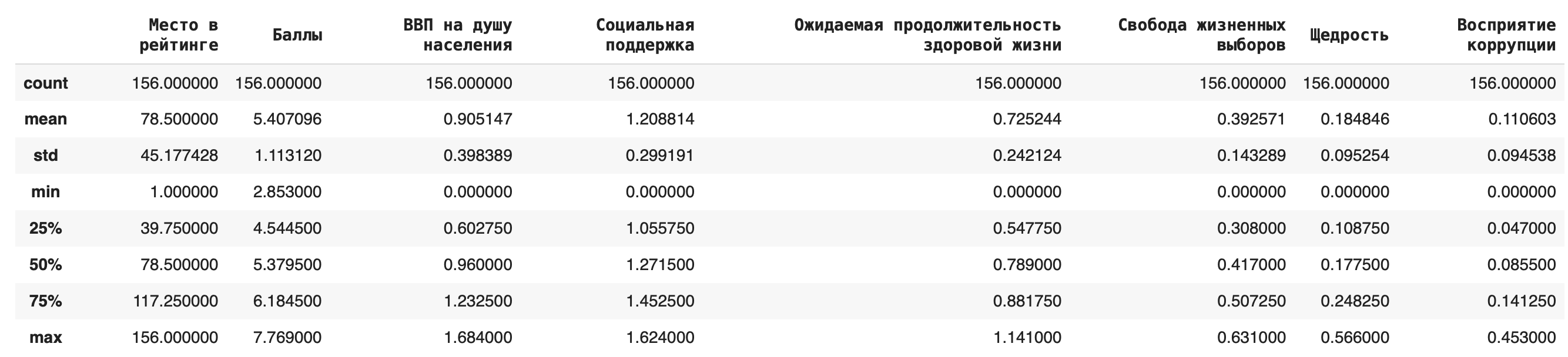

Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу.
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]

Срез можно сохранить в новой переменной: data_new = df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, 'Место в рейтинге':'Социальная поддержка']
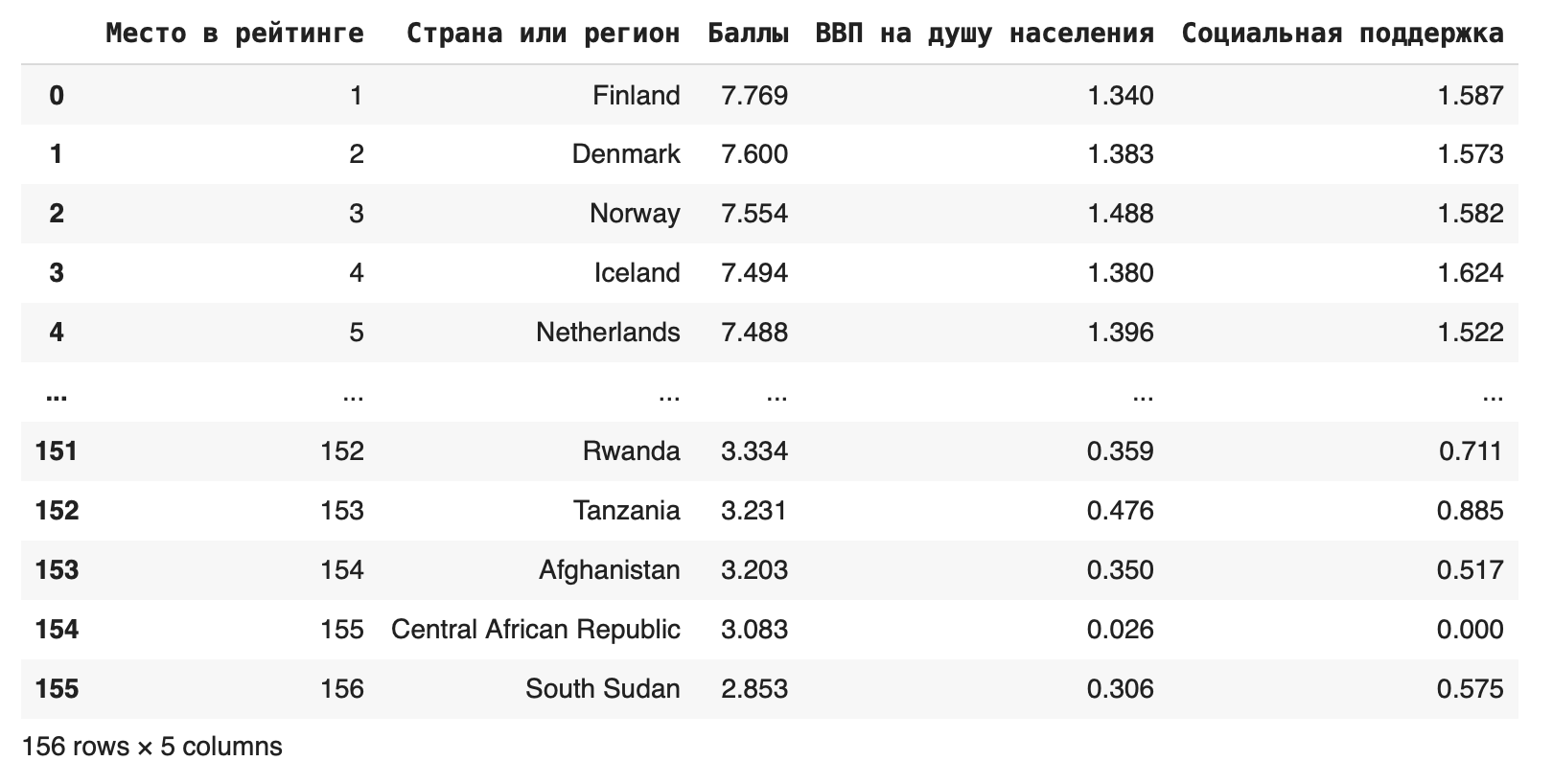
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc: df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
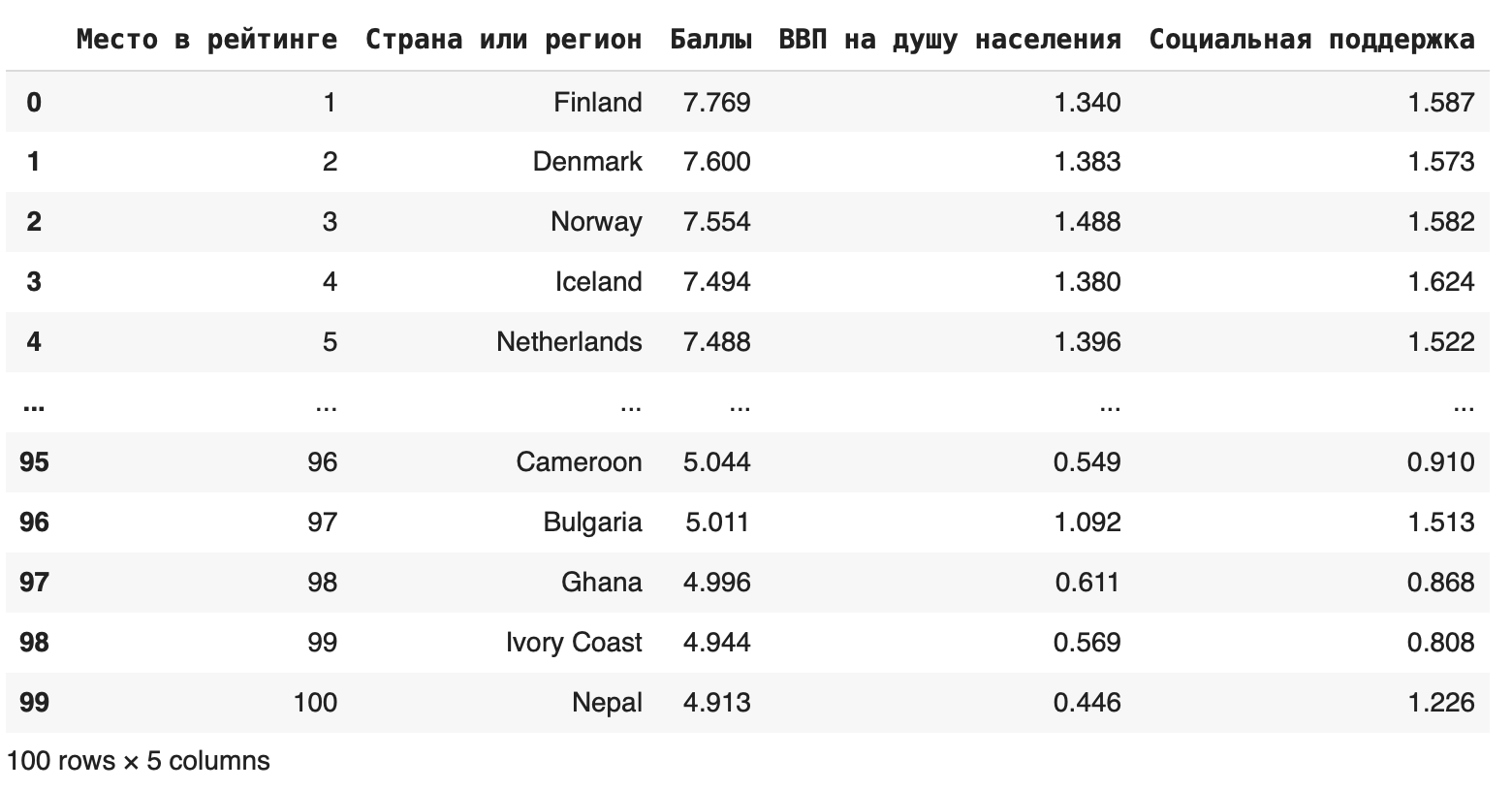
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df['Баллы'].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df['Сумма'] = df['ВВП на душу населения'] + df['Социальная поддержка']

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = df = df.append(new_row, ignore_index=True)
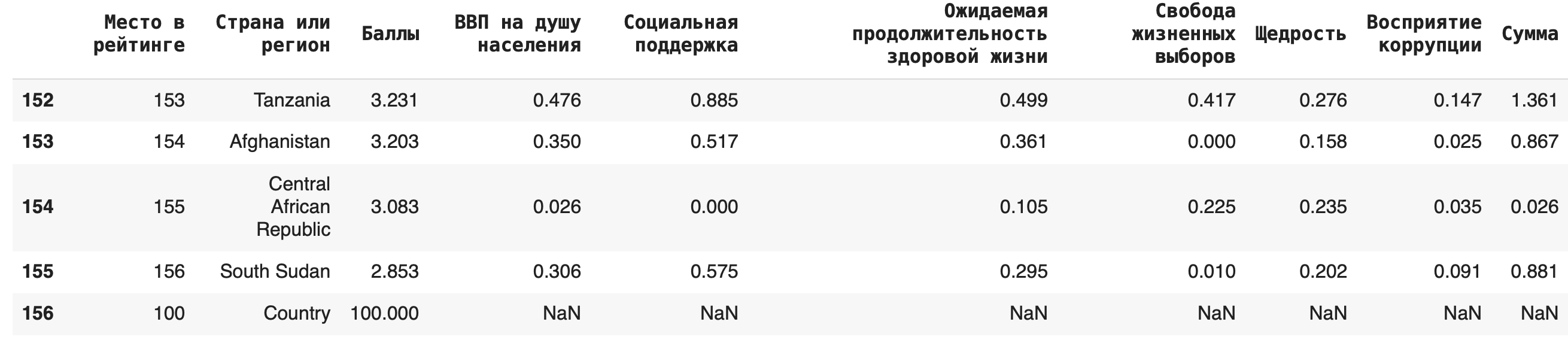
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
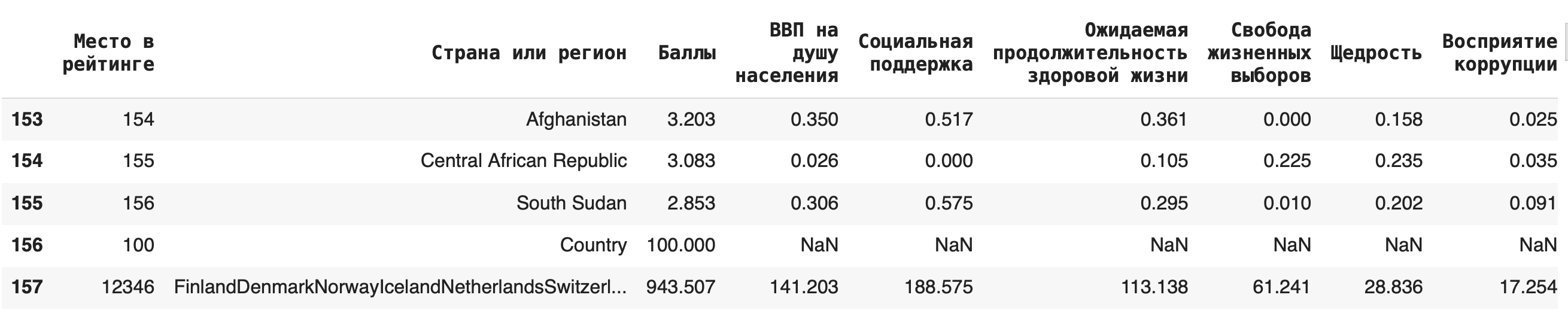
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop(['Сумма'], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df['Страна или регион'].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len(): len(df['Страна или регион'].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df['Страна или регион'].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df['Баллы_new'] = round(df['Баллы'])
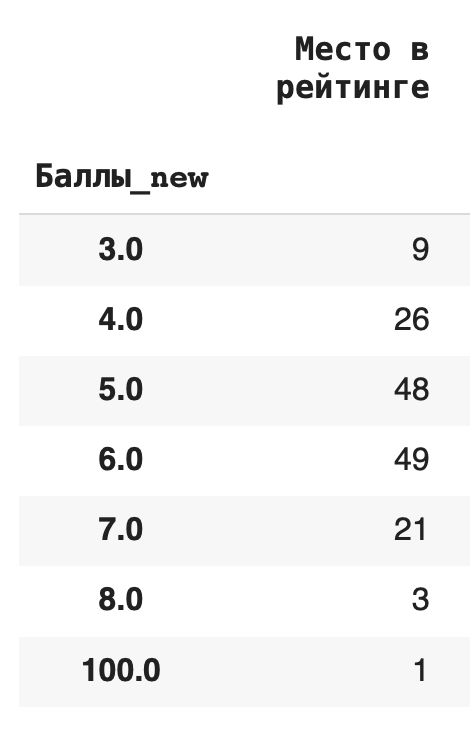
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count(): df.groupby('Баллы_new').count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum(): df.groupby('Баллы_new').sum()
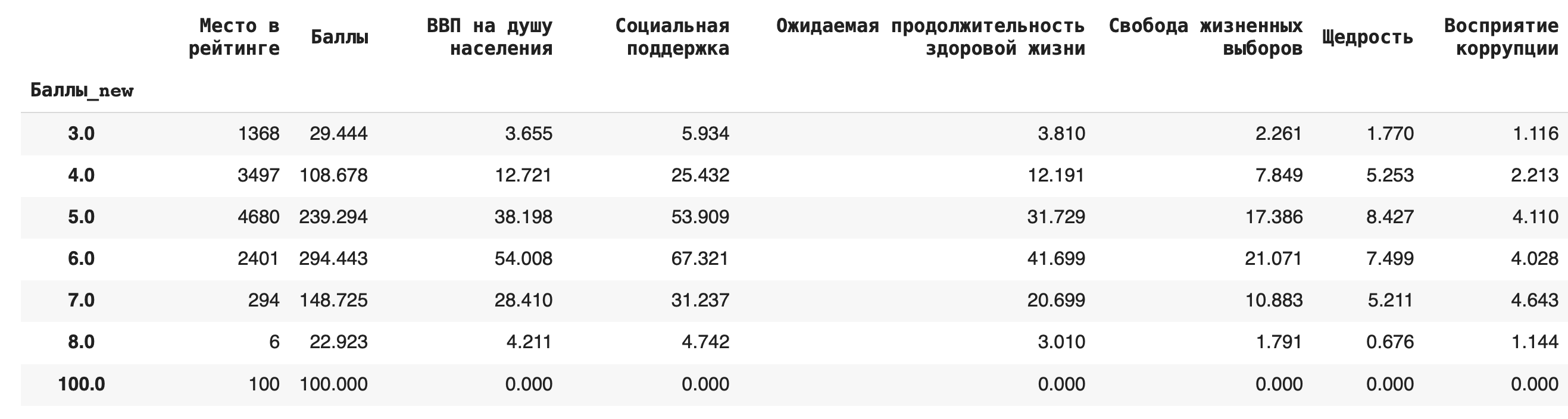
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean(): df.groupby('Баллы_new').mean()
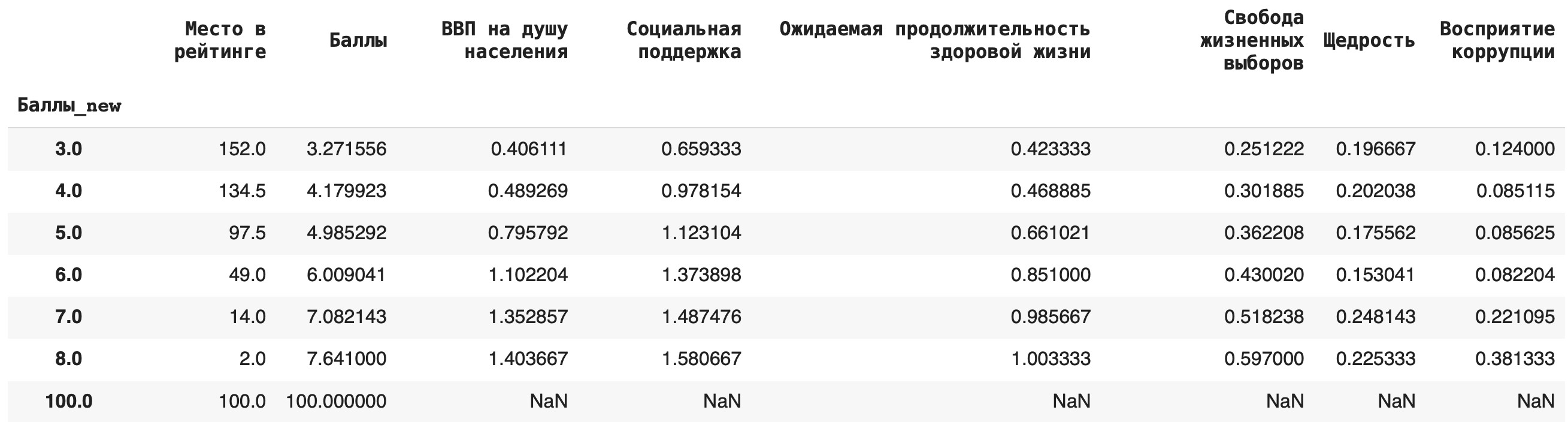
4) Рассчитаем медиану. Для этого пишем команду median(): df.groupby('Баллы_new').median()
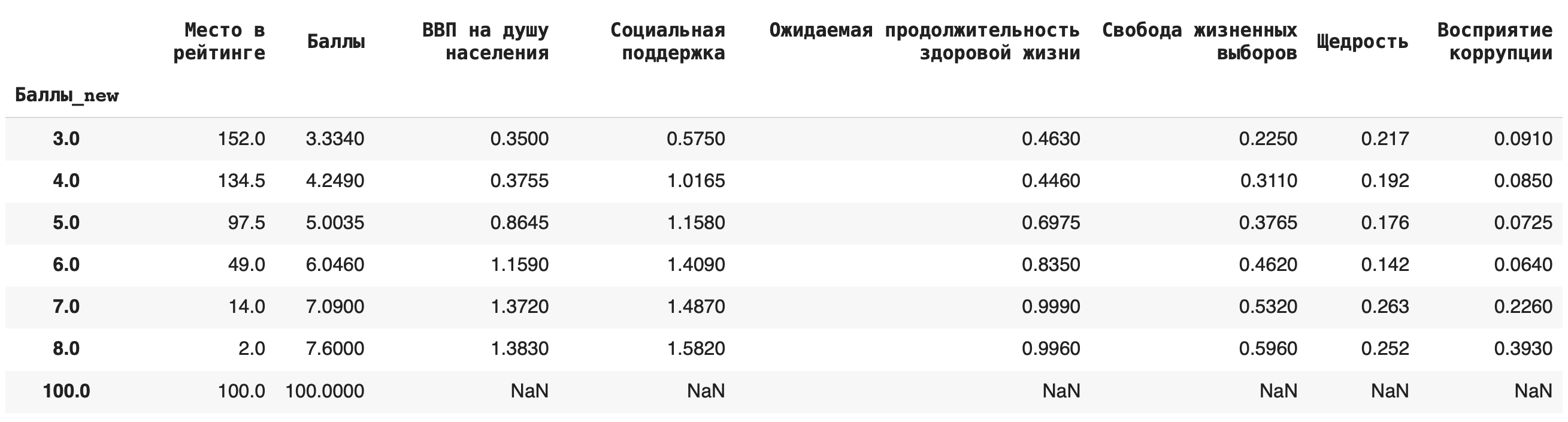
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций:
df_agg = df.groupby('Баллы_new').agg(< 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' >)
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df['ВВП_new'] = round(df['ВВП на душу населения'])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = ['Баллы_new'], columns = ['ВВП_new'], values = 'Социальная поддержка', aggfunc = 'mean')
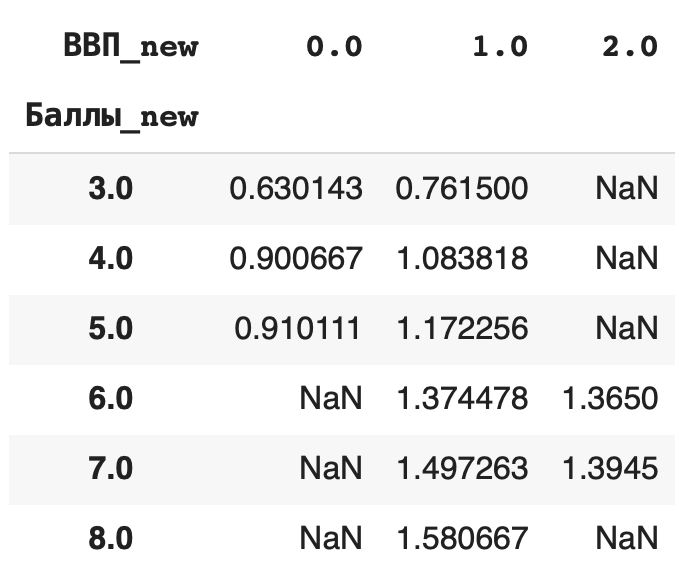
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = 'ВВП на душу населения').head()
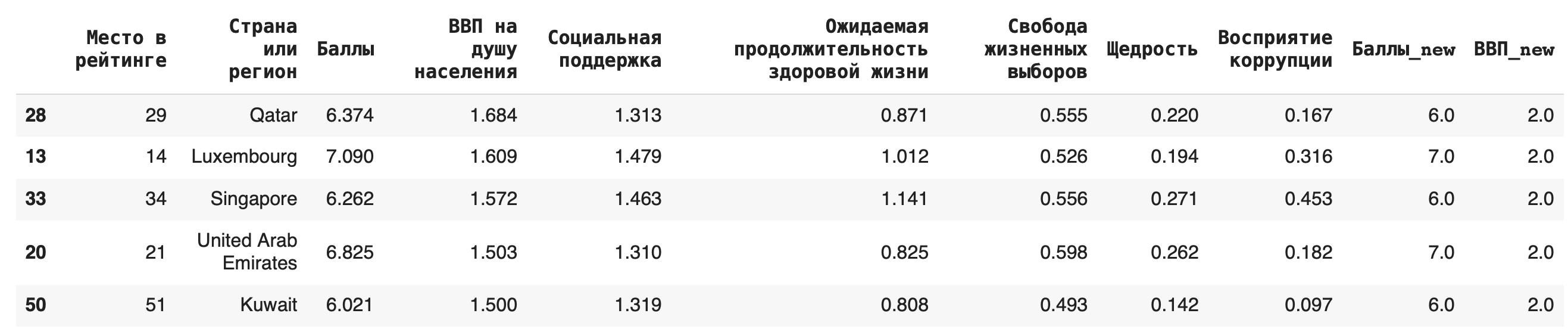
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = 'ВВП на душу населения', ascending=False)
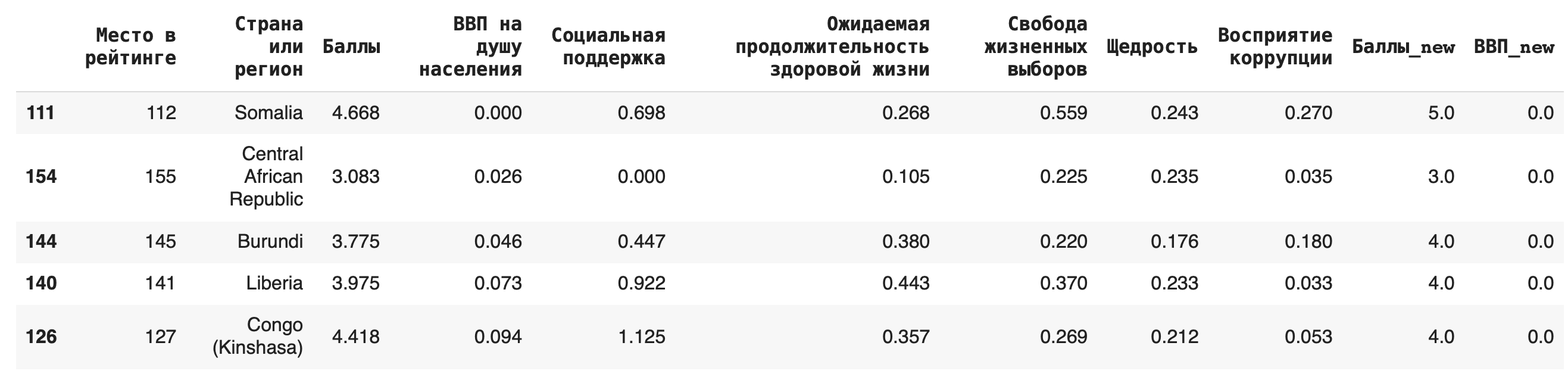
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df['Страна или регион'] == 'Norway']

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:
df[df['Ожидаемая продолжительность здоровой жизни'] > 1]
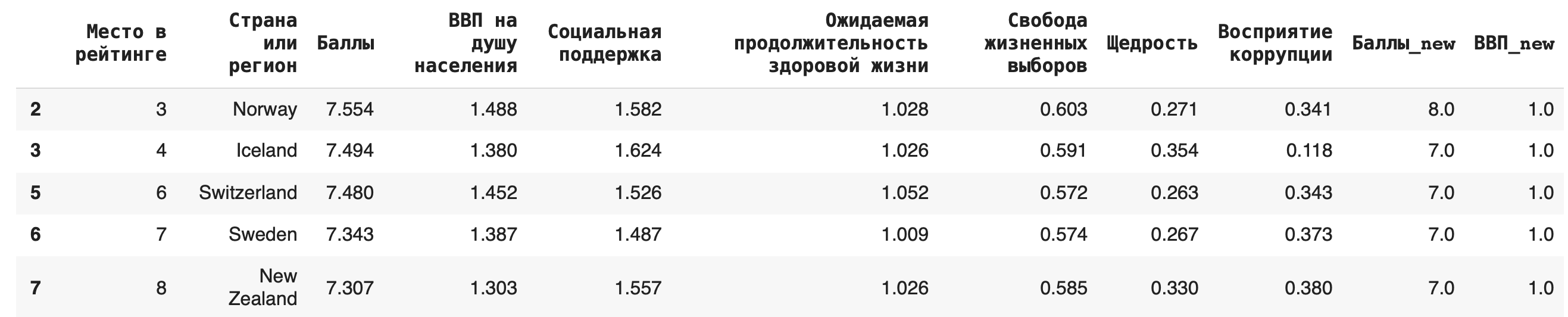
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():
df[df['Страна или регион'].str.startswith('F')]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df['ВВП на душу населения'] > 1) & (df['Социальная поддержка'] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df['Страна или регион'].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True. df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'], inplace = True)
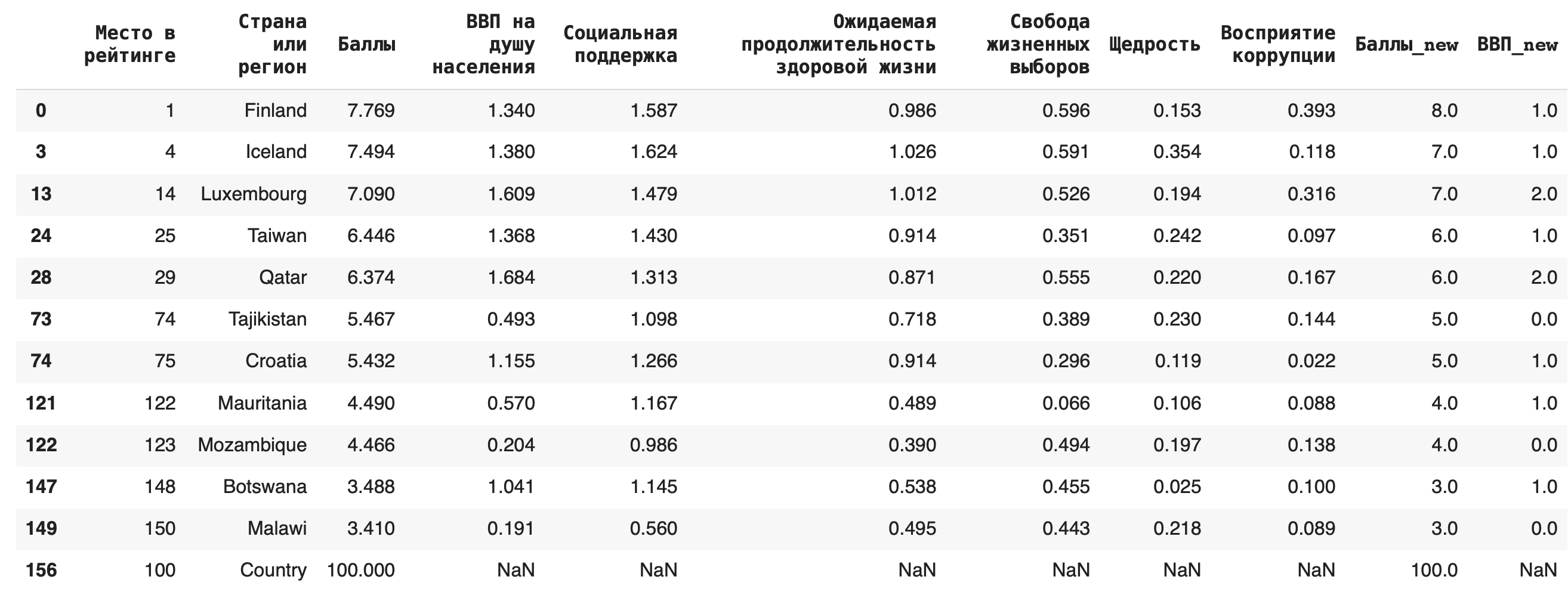
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
1) Обычный график по точкам.
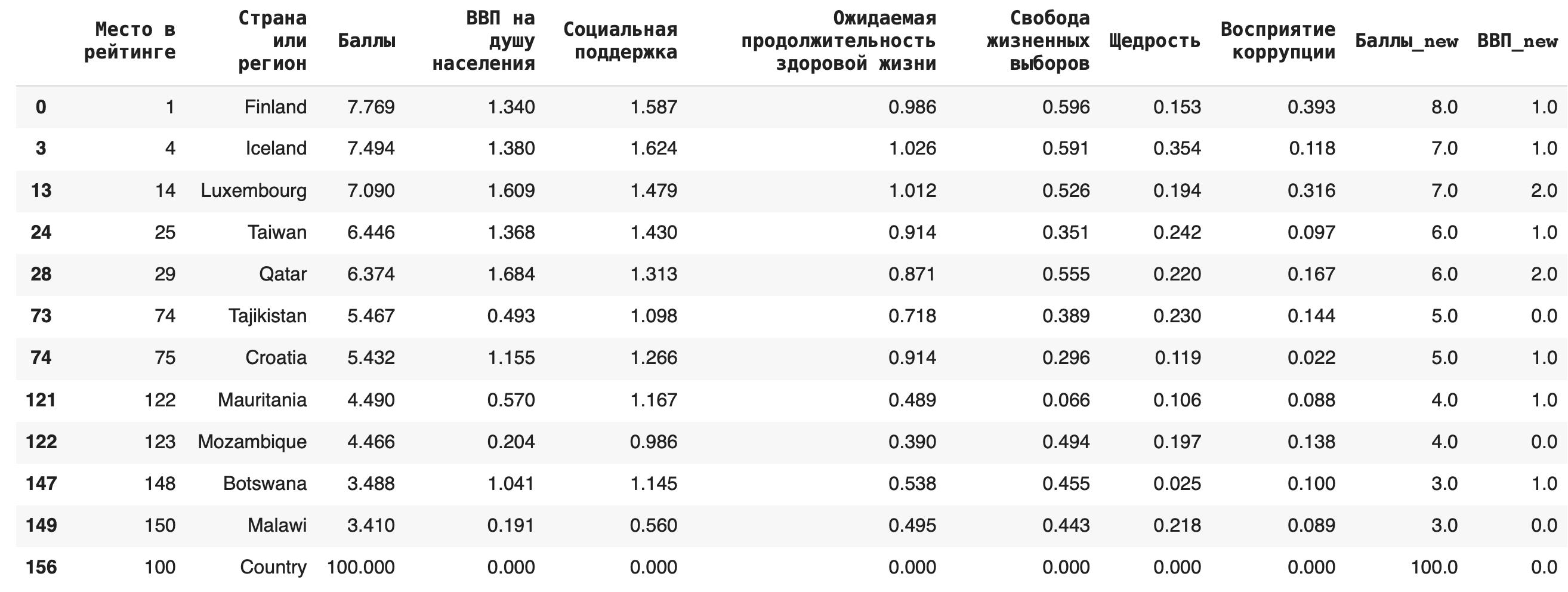
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = 'Место в рейтинге', y = 'ВВП на душу населения')
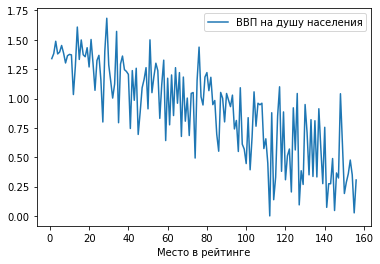
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = 'Место в рейтинге', y = 'ВВП на душу населения')
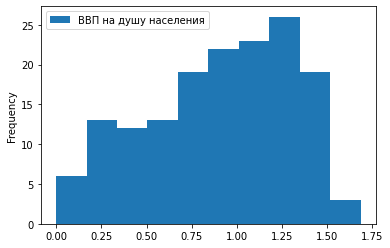
3) Точечный график.
df.plot.scatter(x = 'Место в рейтинге', y = 'ВВП на душу населения')
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv('WHR_2019.csv')
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).
Мария Жарова Выпускница МФТИ, data scientist в Альфа-банк, председатель дипломной комиссии на курсе по Data Science в SkillFactory
Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

Нельзя сказать, что это — исчерпывающий список возможностей pandas , но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
import pandas as pd import numpy as np anime = pd.read_csv('anime-recommendations-database/anime.csv') rating = pd.read_csv('anime-recommendations-database/rating.csv') anime_modified = anime.set_index('name') После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding='ISO-8859–1' ). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.
anime = pd.read_csv('anime-recommendations-database/anime.csv') 
Загруженные CSV-данные
Существует похожая функция для загрузки данных из Excel-файлов — pd.read_excel .
▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
df = pd.DataFrame([[1,'Bob', 'Builder'], [2,'Sally', 'Baker'], [3,'Scott', 'Candle Stick Maker']], columns=['id','name', 'occupation']) 
Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
anime_copy = anime.copy(deep=True) 
Копия датафрейма
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
rating[:10].to_csv('saved_ratings.csv', index=False) Экспортировать данные в виде Excel-файлов можно с помощью функции df.to_excel .
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
anime.head(3) rating.tail(1) 
Данные из начала датафрейма

Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция len(), которую я тут покажу, не входит в состав pandas . Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.
len(df) #=> 3 ▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
len(ratings['user_id'].unique()) ▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
anime.info() 
Сведения о датафрейме
Есть ещё одна функция, похожая на df.info — df.dtypes . Она лишь выводит сведения о типах данных столбцов.
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
anime.describe() 
Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
anime.type.value_counts() 
Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
anime['genre'].tolist() anime['genre'] 
Результаты работы команды anime['genre'].tolist()

Результаты работы команды anime['genre']
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм anime_modified , так как его индексные значения выглядят интереснее.
anime_modified.index.tolist() 
Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
anime.columns.tolist() 
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
anime['train set'] = True ▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
anime[['name','episodes']] 
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
anime.drop(['anime_id', 'genre', 'members'], axis=1).head() 
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0) , которая позволяет получать суммы значений из различных строк.
df = pd.DataFrame([[1,'Bob', 8000], [2,'Sally', 9000], [3,'Scott', 20]], columns=['id','name', 'power level']) df.append(df.sum(axis=0), ignore_index=True) 
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0) .
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
df1 = anime[0:2] df2 = anime[2:4] pd.concat([df1, df2], ignore_index=True) 
Датафрейм df1

Датафрейм df2

Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция df.merge , которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.
rating.merge(anime, left_on=’anime_id’, right_on=’anime_id’, suffixes=(‘_left’, ‘_right’)) 
Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
anime_modified.loc[['Haikyuu!! Second Season','Gintama']] 
Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции df.iloc первой строке назначается индекс 0 , второй — индекс 1 , и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.
Следующая конструкция позволяет выбрать три первых строки датафрейма:
anime_modified.iloc[0:3] 
Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
anime[anime['type'].isin(['TV', 'Movie'])] 
Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
anime[anime[‘type’] == 'TV'] ▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
anime[1:3] 
Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
anime[anime['rating'] > 8] 
Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values :
anime.sort_values('rating', ascending=False) 
Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
anime.groupby('type').count() 
Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется reset_index() . В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.
anime.groupby(["type"]).agg(< "rating": "sum", "episodes": "count", "name": "last" >).reset_index() ▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
tmp_df = rating.copy() tmp_df.sort_values('user_id', ascending=True, inplace=True) tmp_df = tmp_df[tmp_df.user_id < 10] tmp_df = tmp_df[tmp_df.anime_id < 30] tmp_df = tmp_df[tmp_df.rating != -1] pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum, fill_value=0) 
Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения 0 в ячейки, содержащие значение NaN . В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0 . А затем используем функцию fillna(0) для замены значений NaN на 0 .
pivot = pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum) pivot.fillna(0) 
Таблица, содержащая значения NaN

Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1 , то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.
anime.sample(frac=0.25) 
Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
for idx,row in anime[:2].iterrows(): print(idx, row) 
Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
jupyter notebook — NotebookApp.iopub_data_rate_limit=1.0e10 Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.
Уважаемые читатели! Есть ли какие-нибудь возможности pandas , без которых вы не представляете своей повседневной работы?

- Блог компании RUVDS.com
- Веб-разработка
- Python